Ресемплинг — это… Что такое Ресемплинг?
Иллюстрация эффекта наложения спектров при децимации изображения. Сверху — исходное изображение. Слева снизу — уменьшенное в два раза с фильтрацией. Справа снизу — уменьшенное в два раза без фильтрации (с наложением спектров).
Передискретиза́ция (англ. resampling) в обработке сигналов — изменение частоты дискретизации дискретного (чаще всего цифрового) сигнала. Алгоритмы передискретизации широко применяются при обработке звуковых сигналов, радиосигналов и изображений.
В англоязычной литературе применяются также термины downsampling для обозначения понижения частоты дискретизации и upsampling для её повышения.
Понятие передискретизации не следует смешивать с процедурой дискретизации сигнала с запасом по частоте дискретизации (англ. oversampling).
Общие принципы
Вычисление промежуточного отсчёта дискретного сигнала с помощью идеального фильтра нижних частот.
Согласно теореме Котельникова любой непрерывный сигнал с финитным спектром (то есть таким спектром, что спектральные составляющие, соответствующие частотам выше некоторой частоты f0, отсутствуют) может быть представлен в виде отсчётов дискретного сигнала с частотой дискретизации fd > 2f0. При этом такое преобразование является взаимно однозначным, то есть при соблюдении условий теоремы Котельникова по дискретному сигналу можно восстановить исходный сигнал с финитным спектром без искажений.
При передискретизации отсчёты сигнала, соответствующие одной частоте дискретизации, вычисляются по имеющимся отсчётам этого же сигнала, соответствующим другой частоте дискретизации (при этом предполагается, что обе частоты дискретизации соответствуют условиям теоремы Котельникова). Идеальная передискретизация эквивалентна восстановлению непрерывного сигнала по его отсчётам с последующей дискретизацией его на новой частоте.
Точное вычисление значения исходного непрерывного сигнала в определённой точке производится следующим образом:
где s(ti) — i-й отсчёт сигнала, ti — момент времени, соответствующий этому отсчёту,
Сложность практического применения этого выражения заключается в том, что функция не является финитной, поэтому для вычисления значения сигнала в определённый момент времени необходимо обработать бесконечное число его отсчётов (как в прошлом, так и в будущем). В реальной жизни интерполяция осуществляется с помощью других фильтров, при этом выражение для неё принимает следующий вид:
где h(t) — импульсная характеристика соответствующего восстанавливающего фильтра. Вид этого фильтра выбирается в зависимости от задачи.
Прямое вычисление новых отсчётов сигнала по вышеприведённым формулам требует значительных вычислительных ресурсов и нежелательно для приложений реального времени.
- децимация — уменьшение частоты дискретизации в целое число раз;
- интерполяция в узком смысле — увеличение частоты дискретизации в целое число раз.
При таких ограничениях становится удобным применение цифровых фильтров для передискретизации.
Передискретизация с помощью цифровых фильтров
Иллюстрация алгоритма децимации дискретного сигнала (с коэффициентом 2). Красные точки обозначают отсчеты, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал после фильтрации в цифровом фильтре нижних частот. Снизу — децимированный сигнал.
Иллюстрация алгоритма интерполяции дискретного сигнала (с коэффициентом 2). Красные точки обозначают исходные отсчеты сигнала, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал со вставленными нулевыми отсчётами (зеленые точки). Снизу — интерполированный сигнал (синие точки — интерполированные значения отсчётов).
Сверху — исходный сигнал. В середине — этот же сигнал со вставленными нулевыми отсчётами (зеленые точки). Снизу — интерполированный сигнал (синие точки — интерполированные значения отсчётов).
Децимация
Децимацией называют уменьшение частоты дискретизации в целое число раз (далее N). Децимация цифрового сигнала производится в два этапа:
- Цифровая фильтрация сигнала с целью удаления высокочастотных составляющих, не удовлетворяющих условиям теоремы Котельникова для новой частоты дискретизации;
- Удаление (отбрасывание) лишних отсчетов (сохраняется каждый N-й отсчёт).
Первый этап необходим для исключения наложения спектров, природа которого аналогична наложению спектров при первоначальной дискретизации аналогового сигнала. Наложение спектров особенно заметно на тех участках сигнала, которые содержат значительные высокочастотные спектральные составляющие. Так, на приведённых в начале статьи фотографиях небо практически не подвергнулось наложению спектров, но эффект бросается в глаза, если обратить внимание на резкие переходы (такие как чёткие линии зданий и дорожной разметки).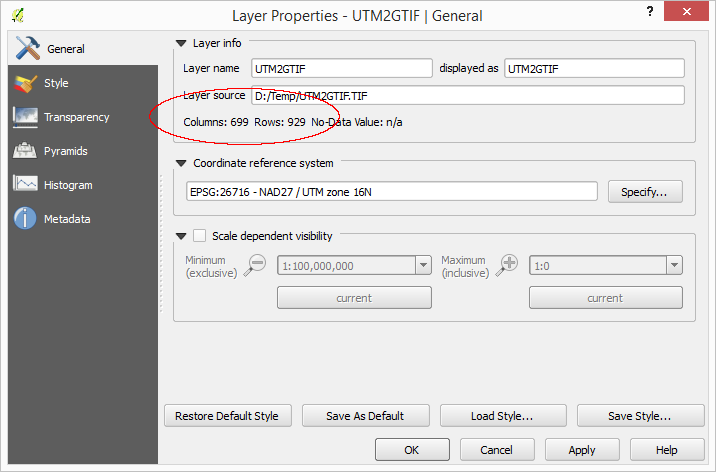
При программной реализации алгоритма децимации «лишние» отсчёты не удаляются, а просто не вычисляются. При этом число обращений к цифровому фильтру уменьшается в N раз.
Интерполяция
Под интерполяцией в узком смысле понимают увеличение частоты дискретизации сигнала в целое число раз путем вычисления промежуточных отсчетов по уже имеющимся. Идеальная интерполяция позволяет точно восстановить значения сигнала в промежуточных отсчётах.
Стандартный алгоритм интерполяции заключается в следующем:
- вставка нулевых отсчетов на место отсчетов, которые необходимо вычислить;
- фильтрация сигнала цифровым фильтром нижних частот для того, чтобы убрать спектральные составляющие сигнала, которых заведомо не могло быть в исходном сигнале согласно теореме Котельникова.
Точность этого метода ограничивается невозможностью реализации фильтра нижних частот с идеально прямоугольной частотной характеристикой.
При программной реализации интерполяции нулевые отсчёты не участвуют в вычислении полинома, что позволяет оптимизировать процесс вычисления.
Комбинация интерполяции и децимации
Для того, чтобы изменить частоту дискретизации сигнала в раз (M и N — целые положительные числа), можно сначала провести интерполяцию, увеличив частоту дискретизации в M раз, а затем с помощью децимации уменьшить её в N раз. Фильтрацию сигнала достаточно произвести всего один раз — между интерполяцией и децимацией.
Недостатком данного метода является необходимость фильтрации сигнала на повышенной в M раз частоте дискретизации, что требует значительных вычислительных ресурсов. При этом соответствующая частота может во много раз превосходить как исходную, так и окончательную частоту передискретизации, особенно если
Передискретизация с помощью полифазных фильтров
Метод передискретизации с помощью полифазных фильтров аналогичен предыдущему, с тем отличием, что в нём вместо одного фильтра, работающего на высокой частоте дискретизации, используется несколько фильтров, работающих на низкой частоте. При этом удаётся добиться сокращения количества необходимых вычислений, так как для каждого отсчёта необходимо вычислить выход только одного из этих фильтров.
Передискретизация с помощью дискретного преобразования Фурье
Передискретизация с помощью ДПФ используется для повышения частоты дискретизации в целое или дробное число раз. Алгоритм работает только с конечными отрезками сигнала. Пусть N — начальное число отсчётов, M — число отсчётов в передискретизованном сигнале. Алгоритм включает в себя следующие операции:
1. Вычисляется ДПФ исходного сигнала (чаще всего по алгоритму быстрого преобразования Фурье).
2. В середину спектра вставляется необходимое число нулевых компонент:
- 2.


- 2.2. если N чётное
3. Вычисляется обратное ДПФ.
Ограничением этого метода является то, что, как и любой метод, основанный на ДПФ, он даёт точный результат только для периодического дискретного сигнала. Для обработки непериодических сигналов необходимо применять оконные функции и выбирать отрезки сигнала для вычисления ДПФ таким образом, чтобы их концы перекрывались.
Применения
Широко применяется как аппаратная (на основе специализированных микросхем или FPGA), так и программная (на базе процессоров общего назначения или сигнальных процессоров) реализация алгоритмов передискретизации.
Выбор конкретной реализации алгоритма передискретизации является результатом компромисса между качеством преобразования и его вычислительной сложностью. Основным параметром, влияющим на эти характеристики, является близость используемых цифровых фильтров к идеальным. Более качественные фильтры требуют больше ресурсов для вычисления.
На практике передискретизация в большинстве случаев ведёт к потере информации о сигнале по следующим причинам:
- при уменьшении частоты дискретизации сигнал необходимо отфильтровать с целью удаления высокочастотных спектральных составляющих, которые не соответствуют условиям теоремы Котельникова для новой частоты дискретизации;
- вычисления, производимые над цифровыми (квантованными по уровню) сигналами ведут к необратимым ошибкам округления.
Таким образом, при увеличении частоты дискретизации с последующим уменьшением её до исходного значения качество сигнала будет потеряно (если только высокая частота не кратна низкой).
При обработке звука
Оборудование, предназначенное для воспроизведения цифрового звука, как правило, рассчитано на вполне определённую частоту дискретизации сигнала непосредственно перед цифро-аналоговым преобразованием (для многих звуковых карт эта частота составляет 48000 Гц). Все звуковые сигналы с другими частотами дискретизации должны быть рано или поздно передискретизованы.
Передискретизация звукового сигнала на требуемую частоту может осуществляться мультимедиа-проигрывателем, драйвером звуковой карты или самой звуковой картой. Использование программы-проигрывателя для данной цели может быть оправдано, если есть желание избежать аппаратной передискретизации звука (или передискретизации драйвером) с целью добиться более высокого качества (при большей загрузке центрального процессора). Однако программная передискретизация воспроизводимого материала на частоту, отличную от частоты, поддерживаемой оборудованием, не имеет смысла и приводит только к потере качества сигнала.
Существуют программные передискретизаторы звуковых сигналов с открытым исходным кодом:
- SRC (Secret Rabbit Code) или libsamplerate[1] — существует плагин для [2] — существуют плагины для foobar2000.
Также передискретизация поддерживается программами-редакторами звука.
При обработке изображений
Изменение разрешения является одной из распространённых операций обработки изображений. Передискретизация, приближенная к идеальной (с минимизацией наложения спектров), не всегда является желательной. Выбор фильтра для передискретизации является результатом компромисса между типом и выраженностью артефактов и вычислительной сложностью преобразования (актуальной для приложений реального времени).
Передискретизация, приближенная к идеальной (с минимизацией наложения спектров), не всегда является желательной. Выбор фильтра для передискретизации является результатом компромисса между типом и выраженностью артефактов и вычислительной сложностью преобразования (актуальной для приложений реального времени).
Типичные артефакты при изменении разрешения изображения:
Для передискретизации изображений применяется большое число фильтров, которые можно классифицировать следующим образом[3]:
- Фильтры интерполяционного типа, обладающие сравнительно узкой импульсной характеристикой. К ним относятся, в частности, треугольный фильтр, производящий билинейную интерполяцию и полином Лагранжа, с помощью которого можно реализовать бикубическую интерполяцию. Применение таких фильтров позволяет осуществить передискретизацию изображения достаточно быстро.
- Фильтры с колоколообразной характеристикой, такие как фильтр Гаусса. Эти фильтры хорошо справляются с пикселизацией, звоном и алиасингом, а также отфильтровывают высокочастотные шумы. Их недостаток — заметное размытие изображения.
- Оконные sinc-фильтры. Sinc-фильтр — это идеальный фильтр нижних частот. Как говорилось выше, он не может быть реализован. Однако если частотную характеристику sinc-фильтра умножить на оконную функцию, получится реализуемый фильтр с хорошими спектральными свойствами. При применении данных фильтров к изображениям удаётся сохранить относительно высокую чёткость (даже при увеличении разрешения), но может быть сильно заметен эффект звона. Одним из наиболее часто применяемых фильтров данного типа является фильтр Ланцоша.
 Их недостаток — заметное размытие изображения.
Их недостаток — заметное размытие изображения.При обработке радиосигналов
При демодуляции цифровых сигналов желательно, чтобы частота дискретизации сигнала была кратна его скорости манипуляции (иначе говоря, чтобы на каждый символ приходилось одинаковое число отсчётов сигнала). Однако частота дискретизации входного сигнала с АЦП, как правило, фиксирована, а скорость манипуляции может меняться. Решением является передискретизация сигнала.
Примечания
- ↑ Secret Rabbit Code (aka libsamplerate)
- ↑ Shibatch Audio Tools
- ↑ Resize and Scaling на сайте программы
Литература
- Richard G. Lyons Understanding digital signal processing. — Addison Wesley, 1997. — 517 с. — ISBN 0-201-63467-8
- Л. Рабинер, Б. Гоулд Теория и применение цифровой обработки сигналов = Theory and Application of Digital Signal Processing. — М.: Мир, 1978. — 848 с.
- Романюк Ю.А. Основы цифровой обработки сигналов. В 3-х ч. Ч.1. Свойства и преобразования дискретных сигналов: Учебное пособие. — М.: МФТИ, 2005. — 332 с. — ISBN 5-74-170144-2
Wikimedia Foundation. 2010.
Ресемплинг — это… Что такое Ресемплинг?
Иллюстрация эффекта наложения спектров при децимации изображения. Сверху — исходное изображение. Слева снизу — уменьшенное в два раза с фильтрацией. Справа снизу — уменьшенное в два раза без фильтрации (с наложением спектров).
Передискретиза́ция (англ. resampling) в обработке сигналов — изменение частоты дискретизации дискретного (чаще всего цифрового) сигнала. Алгоритмы передискретизации широко применяются при обработке звуковых сигналов, радиосигналов и изображений.
В англоязычной литературе применяются также термины downsampling для обозначения понижения частоты дискретизации и upsampling для её повышения.
Понятие передискретизации не следует смешивать с процедурой дискретизации сигнала с запасом по частоте дискретизации (англ. oversampling).
Общие принципы
Вычисление промежуточного отсчёта дискретного сигнала с помощью идеального фильтра нижних частот. Синия кривая — исходный непрерывный сигнал, зелёная — импульсная характеристика идеального ФНЧ.Согласно теореме Котельникова любой непрерывный сигнал с финитным спектром (то есть таким спектром, что спектральные составляющие, соответствующие частотам выше некоторой частоты f0, отсутствуют) может быть представлен в виде отсчётов дискретного сигнала с частотой дискретизации fd > 2f0. При этом такое преобразование является взаимно однозначным, то есть при соблюдении условий теоремы Котельникова по дискретному сигналу можно восстановить исходный сигнал с финитным спектром без искажений.
При этом такое преобразование является взаимно однозначным, то есть при соблюдении условий теоремы Котельникова по дискретному сигналу можно восстановить исходный сигнал с финитным спектром без искажений.
При передискретизации отсчёты сигнала, соответствующие одной частоте дискретизации, вычисляются по имеющимся отсчётам этого же сигнала, соответствующим другой частоте дискретизации (при этом предполагается, что обе частоты дискретизации соответствуют условиям теоремы Котельникова). Идеальная передискретизация эквивалентна восстановлению непрерывного сигнала по его отсчётам с последующей дискретизацией его на новой частоте.
Точное вычисление значения исходного непрерывного сигнала в определённой точке производится следующим образом:
где s(ti) — i-й отсчёт сигнала, ti — момент времени, соответствующий этому отсчёту, s(t) — интерполированное значение сигнала в момент времени t.
Сложность практического применения этого выражения заключается в том, что функция не является финитной, поэтому для вычисления значения сигнала в определённый момент времени необходимо обработать бесконечное число его отсчётов (как в прошлом, так и в будущем). В реальной жизни интерполяция осуществляется с помощью других фильтров, при этом выражение для неё принимает следующий вид:
В реальной жизни интерполяция осуществляется с помощью других фильтров, при этом выражение для неё принимает следующий вид:
где h(t) — импульсная характеристика соответствующего восстанавливающего фильтра. Вид этого фильтра выбирается в зависимости от задачи.
Прямое вычисление новых отсчётов сигнала по вышеприведённым формулам требует значительных вычислительных ресурсов и нежелательно для приложений реального времени. Существуют важные частные случаи передискретизации, для которых вычисление новых отсчётов производится проще:
- децимация — уменьшение частоты дискретизации в целое число раз;
- интерполяция в узком смысле — увеличение частоты дискретизации в целое число раз.
При таких ограничениях становится удобным применение цифровых фильтров для передискретизации.
Передискретизация с помощью цифровых фильтров
Иллюстрация алгоритма децимации дискретного сигнала (с коэффициентом 2). Красные точки обозначают отсчеты, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал после фильтрации в цифровом фильтре нижних частот. Снизу — децимированный сигнал.
Сверху — исходный сигнал. В середине — этот же сигнал после фильтрации в цифровом фильтре нижних частот. Снизу — децимированный сигнал.
Иллюстрация алгоритма интерполяции дискретного сигнала (с коэффициентом 2). Красные точки обозначают исходные отсчеты сигнала, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал со вставленными нулевыми отсчётами (зеленые точки). Снизу — интерполированный сигнал (синие точки — интерполированные значения отсчётов).
Децимация
Децимацией называют уменьшение частоты дискретизации в целое число раз (далее N). Децимация цифрового сигнала производится в два этапа:
- Цифровая фильтрация сигнала с целью удаления высокочастотных составляющих, не удовлетворяющих условиям теоремы Котельникова для новой частоты дискретизации;
- Удаление (отбрасывание) лишних отсчетов (сохраняется каждый N-й отсчёт).
Первый этап необходим для исключения наложения спектров, природа которого аналогична наложению спектров при первоначальной дискретизации аналогового сигнала. Наложение спектров особенно заметно на тех участках сигнала, которые содержат значительные высокочастотные спектральные составляющие. Так, на приведённых в начале статьи фотографиях небо практически не подвергнулось наложению спектров, но эффект бросается в глаза, если обратить внимание на резкие переходы (такие как чёткие линии зданий и дорожной разметки).
При программной реализации алгоритма децимации «лишние» отсчёты не удаляются, а просто не вычисляются. При этом число обращений к цифровому фильтру уменьшается в N раз.
Интерполяция
Под интерполяцией в узком смысле понимают увеличение частоты дискретизации сигнала в целое число раз путем вычисления промежуточных отсчетов по уже имеющимся. Идеальная интерполяция позволяет точно восстановить значения сигнала в промежуточных отсчётах.
Стандартный алгоритм интерполяции заключается в следующем:
- вставка нулевых отсчетов на место отсчетов, которые необходимо вычислить;
- фильтрация сигнала цифровым фильтром нижних частот для того, чтобы убрать спектральные составляющие сигнала, которых заведомо не могло быть в исходном сигнале согласно теореме Котельникова.

Точность этого метода ограничивается невозможностью реализации фильтра нижних частот с идеально прямоугольной частотной характеристикой.
При программной реализации интерполяции нулевые отсчёты не участвуют в вычислении полинома, что позволяет оптимизировать процесс вычисления.
Комбинация интерполяции и децимации
Для того, чтобы изменить частоту дискретизации сигнала в раз (M и N — целые положительные числа), можно сначала провести интерполяцию, увеличив частоту дискретизации в M раз, а затем с помощью децимации уменьшить её в N раз. Фильтрацию сигнала достаточно произвести всего один раз — между интерполяцией и децимацией.
Недостатком данного метода является необходимость фильтрации сигнала на повышенной в M раз частоте дискретизации, что требует значительных вычислительных ресурсов. При этом соответствующая частота может во много раз превосходить как исходную, так и окончательную частоту передискретизации, особенно если M и N — близкие большие числа. Так, например, при передискретизации звукового сигнала с 44100 Гц до 48000 Гц этим методом необходимо увеличить частоту дискретизации в 160 раз до 7056000 Гц и затем уменьшить её в 147 раз до 48000 Гц. Таким образом, в данном примере вычисления приходится производить на частоте дискретизации более 7 МГц.
Так, например, при передискретизации звукового сигнала с 44100 Гц до 48000 Гц этим методом необходимо увеличить частоту дискретизации в 160 раз до 7056000 Гц и затем уменьшить её в 147 раз до 48000 Гц. Таким образом, в данном примере вычисления приходится производить на частоте дискретизации более 7 МГц.
Передискретизация с помощью полифазных фильтров
Метод передискретизации с помощью полифазных фильтров аналогичен предыдущему, с тем отличием, что в нём вместо одного фильтра, работающего на высокой частоте дискретизации, используется несколько фильтров, работающих на низкой частоте. При этом удаётся добиться сокращения количества необходимых вычислений, так как для каждого отсчёта необходимо вычислить выход только одного из этих фильтров.
Передискретизация с помощью дискретного преобразования Фурье
Передискретизация с помощью ДПФ используется для повышения частоты дискретизации в целое или дробное число раз. Алгоритм работает только с конечными отрезками сигнала. Пусть N — начальное число отсчётов, M — число отсчётов в передискретизованном сигнале. Алгоритм включает в себя следующие операции:
Пусть N — начальное число отсчётов, M — число отсчётов в передискретизованном сигнале. Алгоритм включает в себя следующие операции:
1. Вычисляется ДПФ исходного сигнала (чаще всего по алгоритму быстрого преобразования Фурье).
2. В середину спектра вставляется необходимое число нулевых компонент:
- 2.1. если N нечётное:
- 2.2. если N чётное
3. Вычисляется обратное ДПФ.
Ограничением этого метода является то, что, как и любой метод, основанный на ДПФ, он даёт точный результат только для периодического дискретного сигнала. Для обработки непериодических сигналов необходимо применять оконные функции и выбирать отрезки сигнала для вычисления ДПФ таким образом, чтобы их концы перекрывались.
Применения
Широко применяется как аппаратная (на основе специализированных микросхем или FPGA), так и программная (на базе процессоров общего назначения или сигнальных процессоров) реализация алгоритмов передискретизации.
Выбор конкретной реализации алгоритма передискретизации является результатом компромисса между качеством преобразования и его вычислительной сложностью. Основным параметром, влияющим на эти характеристики, является близость используемых цифровых фильтров к идеальным. Более качественные фильтры требуют больше ресурсов для вычисления.
На практике передискретизация в большинстве случаев ведёт к потере информации о сигнале по следующим причинам:
- при уменьшении частоты дискретизации сигнал необходимо отфильтровать с целью удаления высокочастотных спектральных составляющих, которые не соответствуют условиям теоремы Котельникова для новой частоты дискретизации;
- вычисления, производимые над цифровыми (квантованными по уровню) сигналами ведут к необратимым ошибкам округления.
Таким образом, при увеличении частоты дискретизации с последующим уменьшением её до исходного значения качество сигнала будет потеряно (если только высокая частота не кратна низкой).
При обработке звука
Оборудование, предназначенное для воспроизведения цифрового звука, как правило, рассчитано на вполне определённую частоту дискретизации сигнала непосредственно перед цифро-аналоговым преобразованием (для многих звуковых карт эта частота составляет 48000 Гц). Все звуковые сигналы с другими частотами дискретизации должны быть рано или поздно передискретизованы.
Передискретизация звукового сигнала на требуемую частоту может осуществляться мультимедиа-проигрывателем, драйвером звуковой карты или самой звуковой картой. Использование программы-проигрывателя для данной цели может быть оправдано, если есть желание избежать аппаратной передискретизации звука (или передискретизации драйвером) с целью добиться более высокого качества (при большей загрузке центрального процессора). Однако программная передискретизация воспроизводимого материала на частоту, отличную от частоты, поддерживаемой оборудованием, не имеет смысла и приводит только к потере качества сигнала.
Существуют программные передискретизаторы звуковых сигналов с открытым исходным кодом:
- SRC (Secret Rabbit Code) или libsamplerate[1] — существует плагин для [2] — существуют плагины для foobar2000.
Также передискретизация поддерживается программами-редакторами звука.
При обработке изображений
Изменение разрешения является одной из распространённых операций обработки изображений. Передискретизация, приближенная к идеальной (с минимизацией наложения спектров), не всегда является желательной. Выбор фильтра для передискретизации является результатом компромисса между типом и выраженностью артефактов и вычислительной сложностью преобразования (актуальной для приложений реального времени).
Типичные артефакты при изменении разрешения изображения:
Для передискретизации изображений применяется большое число фильтров, которые можно классифицировать следующим образом[3]:
- Фильтры интерполяционного типа, обладающие сравнительно узкой импульсной характеристикой. К ним относятся, в частности, треугольный фильтр, производящий билинейную интерполяцию и полином Лагранжа, с помощью которого можно реализовать бикубическую интерполяцию. Применение таких фильтров позволяет осуществить передискретизацию изображения достаточно быстро.
- Фильтры с колоколообразной характеристикой, такие как фильтр Гаусса. Эти фильтры хорошо справляются с пикселизацией, звоном и алиасингом, а также отфильтровывают высокочастотные шумы. Их недостаток — заметное размытие изображения.
- Оконные sinc-фильтры. Sinc-фильтр — это идеальный фильтр нижних частот. Как говорилось выше, он не может быть реализован. Однако если частотную характеристику sinc-фильтра умножить на оконную функцию, получится реализуемый фильтр с хорошими спектральными свойствами. При применении данных фильтров к изображениям удаётся сохранить относительно высокую чёткость (даже при увеличении разрешения), но может быть сильно заметен эффект звона. Одним из наиболее часто применяемых фильтров данного типа является фильтр Ланцоша.
 К ним относятся, в частности, треугольный фильтр, производящий билинейную интерполяцию и полином Лагранжа, с помощью которого можно реализовать бикубическую интерполяцию. Применение таких фильтров позволяет осуществить передискретизацию изображения достаточно быстро.
К ним относятся, в частности, треугольный фильтр, производящий билинейную интерполяцию и полином Лагранжа, с помощью которого можно реализовать бикубическую интерполяцию. Применение таких фильтров позволяет осуществить передискретизацию изображения достаточно быстро.
При обработке радиосигналов
При демодуляции цифровых сигналов желательно, чтобы частота дискретизации сигнала была кратна его скорости манипуляции (иначе говоря, чтобы на каждый символ приходилось одинаковое число отсчётов сигнала). Однако частота дискретизации входного сигнала с АЦП, как правило, фиксирована, а скорость манипуляции может меняться. Решением является передискретизация сигнала.
Примечания
- ↑ Secret Rabbit Code (aka libsamplerate)
- ↑ Shibatch Audio Tools
- ↑ Resize and Scaling на сайте программы
Литература
- Richard G. Lyons Understanding digital signal processing. — Addison Wesley, 1997. — 517 с. — ISBN 0-201-63467-8
- Л. Рабинер, Б. Гоулд Теория и применение цифровой обработки сигналов = Theory and Application of Digital Signal Processing. — М.: Мир, 1978. — 848 с.
- Романюк Ю.А. Основы цифровой обработки сигналов. В 3-х ч. Ч.1. Свойства и преобразования дискретных сигналов: Учебное пособие. — М.: МФТИ, 2005. — 332 с. — ISBN 5-74-170144-2
Wikimedia Foundation. 2010.
Ресемплинг — это… Что такое Ресемплинг?
Иллюстрация эффекта наложения спектров при децимации изображения. Сверху — исходное изображение. Слева снизу — уменьшенное в два раза с фильтрацией. Справа снизу — уменьшенное в два раза без фильтрации (с наложением спектров).
Передискретиза́ция (англ. resampling) в обработке сигналов — изменение частоты дискретизации дискретного (чаще всего цифрового) сигнала. Алгоритмы передискретизации широко применяются при обработке звуковых сигналов, радиосигналов и изображений.
В англоязычной литературе применяются также термины downsampling для обозначения понижения частоты дискретизации и upsampling для её повышения.
Понятие передискретизации не следует смешивать с процедурой дискретизации сигнала с запасом по частоте дискретизации (англ. oversampling).
Общие принципы
Вычисление промежуточного отсчёта дискретного сигнала с помощью идеального фильтра нижних частот. Синия кривая — исходный непрерывный сигнал, зелёная — импульсная характеристика идеального ФНЧ.Согласно теореме Котельникова любой непрерывный сигнал с финитным спектром (то есть таким спектром, что спектральные составляющие, соответствующие частотам выше некоторой частоты f0, отсутствуют) может быть представлен в виде отсчётов дискретного сигнала с частотой дискретизации fd > 2f0. При этом такое преобразование является взаимно однозначным, то есть при соблюдении условий теоремы Котельникова по дискретному сигналу можно восстановить исходный сигнал с финитным спектром без искажений.
При передискретизации отсчёты сигнала, соответствующие одной частоте дискретизации, вычисляются по имеющимся отсчётам этого же сигнала, соответствующим другой частоте дискретизации (при этом предполагается, что обе частоты дискретизации соответствуют условиям теоремы Котельникова). Идеальная передискретизация эквивалентна восстановлению непрерывного сигнала по его отсчётам с последующей дискретизацией его на новой частоте.
Точное вычисление значения исходного непрерывного сигнала в определённой точке производится следующим образом:
где s(ti) — i-й отсчёт сигнала, ti — момент времени, соответствующий этому отсчёту, s(t) — интерполированное значение сигнала в момент времени t.
Сложность практического применения этого выражения заключается в том, что функция не является финитной, поэтому для вычисления значения сигнала в определённый момент времени необходимо обработать бесконечное число его отсчётов (как в прошлом, так и в будущем). В реальной жизни интерполяция осуществляется с помощью других фильтров, при этом выражение для неё принимает следующий вид:
где h(t) — импульсная характеристика соответствующего восстанавливающего фильтра. Вид этого фильтра выбирается в зависимости от задачи.
Прямое вычисление новых отсчётов сигнала по вышеприведённым формулам требует значительных вычислительных ресурсов и нежелательно для приложений реального времени. Существуют важные частные случаи передискретизации, для которых вычисление новых отсчётов производится проще:
- децимация — уменьшение частоты дискретизации в целое число раз;
- интерполяция в узком смысле — увеличение частоты дискретизации в целое число раз.
При таких ограничениях становится удобным применение цифровых фильтров для передискретизации.
Передискретизация с помощью цифровых фильтров
Иллюстрация алгоритма децимации дискретного сигнала (с коэффициентом 2). Красные точки обозначают отсчеты, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал после фильтрации в цифровом фильтре нижних частот. Снизу — децимированный сигнал.
Иллюстрация алгоритма интерполяции дискретного сигнала (с коэффициентом 2). Красные точки обозначают исходные отсчеты сигнала, сплошные линии — непрерывный сигнал, представлением которого эти отсчеты являются. Сверху — исходный сигнал. В середине — этот же сигнал со вставленными нулевыми отсчётами (зеленые точки). Снизу — интерполированный сигнал (синие точки — интерполированные значения отсчётов).
Децимация
Децимацией называют уменьшение частоты дискретизации в целое число раз (далее N). Децимация цифрового сигнала производится в два этапа:
- Цифровая фильтрация сигнала с целью удаления высокочастотных составляющих, не удовлетворяющих условиям теоремы Котельникова для новой частоты дискретизации;
- Удаление (отбрасывание) лишних отсчетов (сохраняется каждый N-й отсчёт).
Первый этап необходим для исключения наложения спектров, природа которого аналогична наложению спектров при первоначальной дискретизации аналогового сигнала. Наложение спектров особенно заметно на тех участках сигнала, которые содержат значительные высокочастотные спектральные составляющие. Так, на приведённых в начале статьи фотографиях небо практически не подвергнулось наложению спектров, но эффект бросается в глаза, если обратить внимание на резкие переходы (такие как чёткие линии зданий и дорожной разметки).
При программной реализации алгоритма децимации «лишние» отсчёты не удаляются, а просто не вычисляются. При этом число обращений к цифровому фильтру уменьшается в N раз.
Интерполяция
Под интерполяцией в узком смысле понимают увеличение частоты дискретизации сигнала в целое число раз путем вычисления промежуточных отсчетов по уже имеющимся. Идеальная интерполяция позволяет точно восстановить значения сигнала в промежуточных отсчётах.
Стандартный алгоритм интерполяции заключается в следующем:
- вставка нулевых отсчетов на место отсчетов, которые необходимо вычислить;
- фильтрация сигнала цифровым фильтром нижних частот для того, чтобы убрать спектральные составляющие сигнала, которых заведомо не могло быть в исходном сигнале согласно теореме Котельникова.
Точность этого метода ограничивается невозможностью реализации фильтра нижних частот с идеально прямоугольной частотной характеристикой.
При программной реализации интерполяции нулевые отсчёты не участвуют в вычислении полинома, что позволяет оптимизировать процесс вычисления.
Комбинация интерполяции и децимации
Для того, чтобы изменить частоту дискретизации сигнала в раз (M и N — целые положительные числа), можно сначала провести интерполяцию, увеличив частоту дискретизации в M раз, а затем с помощью децимации уменьшить её в N раз. Фильтрацию сигнала достаточно произвести всего один раз — между интерполяцией и децимацией.
Недостатком данного метода является необходимость фильтрации сигнала на повышенной в M раз частоте дискретизации, что требует значительных вычислительных ресурсов. При этом соответствующая частота может во много раз превосходить как исходную, так и окончательную частоту передискретизации, особенно если M и N — близкие большие числа. Так, например, при передискретизации звукового сигнала с 44100 Гц до 48000 Гц этим методом необходимо увеличить частоту дискретизации в 160 раз до 7056000 Гц и затем уменьшить её в 147 раз до 48000 Гц. Таким образом, в данном примере вычисления приходится производить на частоте дискретизации более 7 МГц.
Передискретизация с помощью полифазных фильтров
Метод передискретизации с помощью полифазных фильтров аналогичен предыдущему, с тем отличием, что в нём вместо одного фильтра, работающего на высокой частоте дискретизации, используется несколько фильтров, работающих на низкой частоте. При этом удаётся добиться сокращения количества необходимых вычислений, так как для каждого отсчёта необходимо вычислить выход только одного из этих фильтров.
Передискретизация с помощью дискретного преобразования Фурье
Передискретизация с помощью ДПФ используется для повышения частоты дискретизации в целое или дробное число раз. Алгоритм работает только с конечными отрезками сигнала. Пусть N — начальное число отсчётов, M — число отсчётов в передискретизованном сигнале. Алгоритм включает в себя следующие операции:
1. Вычисляется ДПФ исходного сигнала (чаще всего по алгоритму быстрого преобразования Фурье).
2. В середину спектра вставляется необходимое число нулевых компонент:
- 2.1. если N нечётное:
- 2.2. если N чётное
3. Вычисляется обратное ДПФ.
Ограничением этого метода является то, что, как и любой метод, основанный на ДПФ, он даёт точный результат только для периодического дискретного сигнала. Для обработки непериодических сигналов необходимо применять оконные функции и выбирать отрезки сигнала для вычисления ДПФ таким образом, чтобы их концы перекрывались.
Применения
Широко применяется как аппаратная (на основе специализированных микросхем или FPGA), так и программная (на базе процессоров общего назначения или сигнальных процессоров) реализация алгоритмов передискретизации.
Выбор конкретной реализации алгоритма передискретизации является результатом компромисса между качеством преобразования и его вычислительной сложностью. Основным параметром, влияющим на эти характеристики, является близость используемых цифровых фильтров к идеальным. Более качественные фильтры требуют больше ресурсов для вычисления.
На практике передискретизация в большинстве случаев ведёт к потере информации о сигнале по следующим причинам:
- при уменьшении частоты дискретизации сигнал необходимо отфильтровать с целью удаления высокочастотных спектральных составляющих, которые не соответствуют условиям теоремы Котельникова для новой частоты дискретизации;
- вычисления, производимые над цифровыми (квантованными по уровню) сигналами ведут к необратимым ошибкам округления.
Таким образом, при увеличении частоты дискретизации с последующим уменьшением её до исходного значения качество сигнала будет потеряно (если только высокая частота не кратна низкой).
При обработке звука
Оборудование, предназначенное для воспроизведения цифрового звука, как правило, рассчитано на вполне определённую частоту дискретизации сигнала непосредственно перед цифро-аналоговым преобразованием (для многих звуковых карт эта частота составляет 48000 Гц). Все звуковые сигналы с другими частотами дискретизации должны быть рано или поздно передискретизованы.
Передискретизация звукового сигнала на требуемую частоту может осуществляться мультимедиа-проигрывателем, драйвером звуковой карты или самой звуковой картой. Использование программы-проигрывателя для данной цели может быть оправдано, если есть желание избежать аппаратной передискретизации звука (или передискретизации драйвером) с целью добиться более высокого качества (при большей загрузке центрального процессора). Однако программная передискретизация воспроизводимого материала на частоту, отличную от частоты, поддерживаемой оборудованием, не имеет смысла и приводит только к потере качества сигнала.
Существуют программные передискретизаторы звуковых сигналов с открытым исходным кодом:
- SRC (Secret Rabbit Code) или libsamplerate[1] — существует плагин для [2] — существуют плагины для foobar2000.
Также передискретизация поддерживается программами-редакторами звука.
При обработке изображений
Изменение разрешения является одной из распространённых операций обработки изображений. Передискретизация, приближенная к идеальной (с минимизацией наложения спектров), не всегда является желательной. Выбор фильтра для передискретизации является результатом компромисса между типом и выраженностью артефактов и вычислительной сложностью преобразования (актуальной для приложений реального времени).
Типичные артефакты при изменении разрешения изображения:
Для передискретизации изображений применяется большое число фильтров, которые можно классифицировать следующим образом[3]:
- Фильтры интерполяционного типа, обладающие сравнительно узкой импульсной характеристикой. К ним относятся, в частности, треугольный фильтр, производящий билинейную интерполяцию и полином Лагранжа, с помощью которого можно реализовать бикубическую интерполяцию. Применение таких фильтров позволяет осуществить передискретизацию изображения достаточно быстро.
- Фильтры с колоколообразной характеристикой, такие как фильтр Гаусса. Эти фильтры хорошо справляются с пикселизацией, звоном и алиасингом, а также отфильтровывают высокочастотные шумы. Их недостаток — заметное размытие изображения.
- Оконные sinc-фильтры. Sinc-фильтр — это идеальный фильтр нижних частот. Как говорилось выше, он не может быть реализован. Однако если частотную характеристику sinc-фильтра умножить на оконную функцию, получится реализуемый фильтр с хорошими спектральными свойствами. При применении данных фильтров к изображениям удаётся сохранить относительно высокую чёткость (даже при увеличении разрешения), но может быть сильно заметен эффект звона. Одним из наиболее часто применяемых фильтров данного типа является фильтр Ланцоша.
При обработке радиосигналов
При демодуляции цифровых сигналов желательно, чтобы частота дискретизации сигнала была кратна его скорости манипуляции (иначе говоря, чтобы на каждый символ приходилось одинаковое число отсчётов сигнала). Однако частота дискретизации входного сигнала с АЦП, как правило, фиксирована, а скорость манипуляции может меняться. Решением является передискретизация сигнала.
Примечания
- ↑ Secret Rabbit Code (aka libsamplerate)
- ↑ Shibatch Audio Tools
- ↑ Resize and Scaling на сайте программы
Литература
- Richard G. Lyons Understanding digital signal processing. — Addison Wesley, 1997. — 517 с. — ISBN 0-201-63467-8
- Л. Рабинер, Б. Гоулд Теория и применение цифровой обработки сигналов = Theory and Application of Digital Signal Processing. — М.: Мир, 1978. — 848 с.
- Романюк Ю.А. Основы цифровой обработки сигналов. В 3-х ч. Ч.1. Свойства и преобразования дискретных сигналов: Учебное пособие. — М.: МФТИ, 2005. — 332 с. — ISBN 5-74-170144-2
Wikimedia Foundation. 2010.
Ресемплинг. Цифровая кирпичная стена против теории заговора. Рождественская сказка для любителей чистого звука
Ни в одной области электроники не скопилось столько мифов,как в области Hi-Fi и Hi-End устройств для воспроизведения звука.
Ударим Рождественской Историей по одному из них!
Когда старый год уже проводили, Новый встретили сначала в узком семейном кругу, а затем с более дальними родственниками, когда закончились или пришли в негодность новогодние салаты и стало отпускать похмелье…
Те, кто не захотел или не смог встречать Новый Год в Дальнем Зарубежье, начинают ощущать на себе зов персонального компьютера.
Именно для них и предназначена моя рождественская история, об основах ресемплинга — технологии, позволившей значительно улучшить качество воспроизведения дисков формата Аудио CD в начале тысячелетия. Именно тогда для воспроизведения 16 битных записей начали применять 18 и даже 20 битные цифро-аналоговые преобразователи. С первого взгляда это выглядело как маркетинговая уловка производителей, направленная на извлечение дополнительной порции денег из кошельков доверчивых аудиофилов, но в этот раз сторонники теории заговоров могут курить в сторонке. На самом деле это было удачной попыткой улучшить качество воспроизведения и снизить цену дорогостоящей профессиональной аппаратуры. История старая, но поучительная, во многом актуальная и по сей день.
Цифро-аналоговый преобразователь digital-to-analog DAC является сердцем любой аудиовопроизводящей системы, использующей в качестве источника компакт диски. На него возложена сложная и деликатная задача раскодирования последовательности 16-битных чисел и преобразования её в формат, воспринимаемый человеческим ухом.
В далёком 1983 году появился первый культовый CD проигрыватель Magnavox со сдвоенным 14 битным конвертором, но уже к началу века многие системы высококачественного воспроизведения CD дисков имели 18, а то и 20 битные преобразователи. Почему?
Немного теории, почти без формул
Концепция цифро-аналоговых преобразований покоится на двух китах: частоте дискретизации
samplingи разрядности
quantization.
Для воспроизведения звука в PCM формате мы должны через равные промежутки времени преобразовывать цифровые значения в соответствующие им аналоговые величины напряжения или тока. Частота этих преобразований и является частотой дискретизации. Согласно теореме Найквиста, таким образом возможно воспроизводить сигналы с частотой не выше половины частоты дискретизации. Наиболее распространённые форматы, которые способны воспроизводить сигналы с частотой воспринимаемой человеческим ухом общепринята цифра 20 кГц, имеют частоты дискретизации в 44.1 и 48 КГц.
Первый до сих пор широко используется в звуковых компакт дисках (CDDA, англ. Compact Disc Digital Audio, также называемый англ. Audio CD и Red Book), а второй зародился в ряде стандартов для профессиональной звукозаписывающей аппаратуры.
Давайте вообразим себе что при записи звуковой сигнал попадает на идеальный аналогово-цифровой преобразователь. Он не имеет собственных шумов и искажений и преобразует мгновенное значение поступающего на него сигнала в цифровое с заданной разрядностью, ну например в 16 бит, как это принято в формате Audio CD. В таком случае, теоретически достижимый динамический диапазон сигнала (соотношение между оцифрованными сигналами с самым большим и маленьким уровнями) будет составлять 98.1 dB. Для вычисления этой величины часто используют приближённую формулу, согласно которой каждый лишний бит добавляет 6 децибел к теоретически достижимому динамическому диапазону. Для 16 битного сигнала мы получим:
6dB/bit*16bits=96dB.
Реальный музыкальный сигнал чаще всего состоит не из чистого тона, а из смеси большого количества быстро меняющих свою частоту и амплитуду гармоник. Для гармоник, имеющих амплитуду менее одного разряда АЦП, невозможно восстановить корреляцию с исходным сигналом и они в результате операции кодирования-декодирования превращаются в белый шум. Кроме этого, шумы генерируются быстро изменяющимися сигналами с большой амплитудой, которых много скажем в поп музыке.
От идеальных приближений к реальной жизни. Проблемы первых CD проигрывателей
Со времён начала использования цифровых технологий в звукозаписи ведётся постоянная гонка за увеличение их производительности и уменьшение стоимости. Первые CD проигрыватели имели единственный параллельный DAC и две входные цепи, которые поочерёдно подавали на него сигналы то правого, то левого каналов. Мгновенные уровни аналоговых сигналов на выходе DAC фиксировались с помощью специальных цепей на время между двумя считываниями и попеременно поступали на отдельные усилители правого и левого каналов. Это порождало дополнительные искажения, величина которых зависела от разности мгновенных звуковых уровней каналов. Под напором критики ауидофилов производители вынуждены были перейти на схему с отдельными DAC для каждого из каналов.
На выходе DAC присутствует ступенчатый сигнал, который не слишком похож на плавный исходный, в нём существуют неприятные на слух искажения. Давайте для упрощения представим что на вход была подана единственная гармоника с частотой 1 КГц. Операция восстановления оцифрованного сигнала приводит фактически к возникновению интермодуляционных искажений между исходным сигналом и частотой дискретизации — в нашем случае 44.1 КГц. (Механизм возникновения интермодуляционных искажений и ликбез по гармоникам при необходимости ищите в моей прошлой статье).
Несмотря на то, что паразитные гармоники лежат за пределами человеческого уха, они оказывают неблагоприятное воздействие на усилительный тракт и от них лучше избавиться.
В ранних моделях аппаратуры для воспроизведения цифрового контента для этого использовались фильтры, которые имели плоскую характеристику до частоты в 20 кГц, а далее резкое ослабление уровня на 80дБ и более. В английской терминологии такие фильтры называют brick-wall, на русском иногда именуют по аналогии “кирпичной стеной”. Проблема заключалась в том, что аналоговые ФНЧ высокого порядка очень чувствительны к точности значений пассивных компонентов, из которых они состоят. Ещё больше осложняют ситуацию требуемые номиналы выбивающиеся за пределы стандартного ряда и особые требования к качеству этих компонентов, которое необходимо для достижения минимального вклада в искажение сигнала. В результате, стоимость данных фильтров получалась запредельной, но самое печальное — они не смогли удовлетворить запросы аудиофилов, поскольку данные фильтры имели большие фазовые искажения, особенно на краях воспроизводимого диапазона. Поэтому звучание ранних версий CD проигрывателей несмотря на высокую стоимость аудиофилы характеризовали как “песочное” (gritty).
Цифровые фильтры спешат на помощь. Oversampling на пальцах
Серьёзным шагом в направлении улучшения качества звука
было внедрение технологии передискретизации сигнала, которой собственно и посвящена данная статья.
Для того, чтобы пояснить её сущность давайте представим процесс восстановления сигнала с так любимой ГОСТами частотой 1 КГц. На рисунке A представлен ряд сэмплов составляющих сигнал, которые появляются на выходе DAC, а правее спектральные составляющие второго и третьего порядков, содержащиеся в сигнале на выходе DAC. Можно заметить, что сигнал является ни чем иным, как продуктом интермодуляционных искажений между исходным тоном с частотой 1 КГц и частой оцифровки 44.1 КГц.
Увеличим частоту дискретизации сигнала в четыре раза путём элементарной операции — добавления лишних трёх сэмплов между двумя соседними, каждый из которых имеет нулевые значения, как показано на рисунке C. Одновременно с этим добавим два младших разряда в каждый сэмпл, также заполнив их нулями. Теперь мы получили 18 битные значения сэмплов. В результате этой операции спектр сигнала фактически не изменился, но на самом деле произошло фундаментальное изменение. Гармоники второго порядка, вызванные частотой дискретизации стали частью спектра основного сигнала. Производные же гармоники переместились выше частоты 44.1 кГц. Это показано на рисунке D.
В области же спектра основного сигнала с успехом можно применить цифровую фильтрацию, что мы и сделаем, использовав цифровой фильтр высокого порядка, с АЧХ показанный на рисунке F. Физически мы получаем дополнительные промежуточные точки между имеющимися сэмплами сигнала, которые сглаживают переходы между двумя значениями за счёт появления дополнительных двух разрядов в представлении амплитуды.
Теперь, когда всю тяжёлую и грязную работу выполнил цифровой фильтр мы подаём результирующий сигнал с частотой дискретизации в 44.1*4 =176.4 КГц, на DAC.
Осталось добавить вишенку на наш тортик — пропустить сигнал через простейший аналоговый фильтр третьего порядка, который отлично справится с подавлением гармоник в заданном диапазоне и не внесёт при этом заметных фазовых искажений.
Результат — спектр полученного сигнала стал гораздо ближе к исходному, паразитные составляющие в нём сильно ослаблены, а фазовые искажения сведены к минимуму благодаря возможностям цифровой фильтрации.
Аппаратная реализация
На рисунке представлена аппаратная реализация описанного выше решения. Операции передискретизации и цифровой фильтрации выполняет микросхема CXD1088Q производства фирмы SONY — одним из прародителей формата Audio CD. Несложная логическая схема поочерёдно запускает преобразование двух отдельных 18 битных DAC AD1860.
Какие же преимущества мы получили в результате наших цифровых фокусов?
- Снижение интермодуляционных искажений
- Низкие фазовые искажения, вносимые фильтром
- Отличное подавление высших гармоник, возникающий в процессе цифро-аналогового преобразования, которые могут служить источником возникновения интермодуляционных искажений в усилительном тракте
- Применение ЦАП с большей разрядностью позволяет уменьшить нелинейности преобразования и коэффициент гармонических искажений в силу того, что они имеют лучшие параметры
- Благодаря использованию специализированных чипов вместо сложных аналоговых фильтров, снизилась цена реализации, размеры и потребляемая мощность аппаратного решения.
Каждому яблоку место упасть, каждому вору возможность украсть…
Как любая хорошая рождественская история, эта имеет хэппиенд. От внедрения новой технологии кажется выиграли все:
Производители профессиональной аппаратуры и CD проигрывателей в сегменте Hi Fi смогли улучшить качество звука и значительно увеличить повторяемость параметров своих изделий в процессе производства.
Любители качественного звука получили проигрыватели дисков с улучшенными параметрами за разумную цену.
Законченные аудиофилы теперь могут ворчать о том, какой крутой звук был у старых аппаратов с аналоговыми фильтрами пока всё не испортила цифра и охотиться за винтажной техникой.
Ну а избранные производители хайэнда могут создавать единичные экземпляры устройств, тщательно подбирая компоненты аналогового фильтра с характерным названием “кирпичная стена”, получая при этом аппараты с индивидуальным звучанием обусловленным в основном вносимыми фильтрами фазовыми и не только искажениями и задирать их ценник до небес.
Более подробное сравнение работы аналоговых и цифровых фильтров и ответы на характерные вопросы читайте в следующей статье
.
При подготовке публикации были использованы материалы статьи DAC ICs: How Many Bits is Enought? под авторством Robert Adams
Что такое DPI и ресемплинг
Что такое DPI и ресемплингВернуться к разделу «Материалы по сканированию и оцифровке бумажных книг».
Что такое DPI и ресемплинг
По материалам книги Сибил и Эмиль
Айриг
«Сканирование — профессиональный подход».
Введение
Создавая электронные версии бумажных книг (в формате DjVu), необходимо знать некоторые основные базовые понятия из области сканирования и преобразования изображений. Это поможет создавать электронные книги лучшего качества, а также находить общий язык с единомышленниками.
К таким базовым понятиям относятся, например, «DPI» и «ресемплинг».
Виды разрешения
Исходная чёрно-белая или цветная страница бумажной книги имеет непрерывный тон — смежные цвета или оттенки плавно переходят друг в друга. Однако компьютеры не могут воспринять ничего непрерывного, для того, чтобы поместить в компьютер цифровую копию бумажной страницы, её нужно разбить на дискретные единицы — пикселы.
Пиксел, или элемент изображения, является минимальной единицей измерения данных изображения. Каждый пиксел имеет однородный цвет. Компьютер же воспроизводит цифровые изображения путём моделирования непрерывных тонов с помощью этих маленьких дискретных элементов.
Понятие «разрешение» имеет несколько различных значений:
Плотность информации, которую сканирующее устройство может вводить на дюйм (входное разрешение, или разрешение при сканировании).
Полный объём информации в растровом изображении (разрешение изображения).
Число дискретных горизонтальных и вертикальных элементов, которые может одновременно отображать компьютерный монитор (экранное разрешение).
Важно различать эти значения.
Во всех случаях разрешение описывает либо общее количество, либо плотность графической информации в пикселях на единицу площади цифрового изображения (при масштабе 100%).
Единицы разрешения
Все оцифровывающие устройства — сканеры, цифровые фото- и видеокамеры и т.д., имеют несколько общих функций:
— Преобразуют аналоговую (реальную) информацию в цифровые данные, которые могут использоваться компьютером.
— Генерируют растровые изображения, состоящие из матриц чёрно-белых, серых полутоновых или цветных пикселов (элементов изображения).
Примечание: Растровые изображения часто называют также битовыми изображениями, но между ними имеется важное различие. Термин «растровое изображение» описывает состоящие из пикселов изображения независимо от их цветовых характеристик. Битовые изображения (bitmap) содержат только чёрно-белые пикселы.
— Считывают или производят выборку исходного изображения, измеряя значения градаций серого или цвета для каждого элемента выборки.
Входное разрешение сканера описывает плотность, с которой сканирующее устройство производит выборку информации в данной области (обычно на дюйм или на сантиметр) в ходе оцифровки.
PPI (пикселы на дюйм)
Программные интерфейсы многих оцифровывающих устройств описывают частоту дискретизации в ppi или пикселах на дюйм. Многие цифровые фото- и видеокамеры имеют единое фиксированное входное разрешение, а в сканерах обычно имеется диапазон возможных разрешений. При этом с ростом частоты дискретизации сканирующего устройства размер генерируемых пикселов уменьшается. Это легко понять, если мысленно попробовать упаковать 50 сардин в банку, предназначенную для 25 сардин стандартного размера. 50 сардин поместятся в ней только в том случае, если они вдвое меньше стандартных 25.
Термин «пикселы» может также указывать полный объём информации, которую оцифрованное изображение содержит по горизонтали и по вертикали (например, 800 х 400 пикселов). Этот вариант использования описывает скорее разрешение изображения, чем входное разрешение. Наконец, многие используют термин «пикселы» для описания экранного разрешения — числа горизонтальных и вертикальных дискретных визуальных элементов, которые может отображать компьютерный монитор, — например, 1024 х 768 пикселов. В отличие от размера пикселов, которые вводит сканирующее устройство, размер пикселов на компьютерном мониторе остается постоянным. Следовательно, монитор отображает все пикселы каждого изображения с единым фиксированным размером. Это объясняет, почему изображение, сканированное с разрешением 300 ppi, отображается на мониторе компьютера Macintosh с разрешением всего 72 ppi и выглядит намного большим на экране, чем в печати.
DPI (точки на дюйм) Многие журналисты и некоторые программные интерфейсы сканирования всё ещё используют термин dpi (точки на дюйм) для описания разрешения при сканировании, или входного разрешения. Однако с технической точки зрения число точек на дюйм описывает выходное разрешение, представляя горизонтальную плотность меток, которые имиджсеттеры и лазерные принтеры типа PostScript делают в ходе печати. Будьте внимательны и не путайте эти два термина - подразумевайте «ppi» всякий раз, когда видите в интерфейсе сканера «dpi».
Виды разрешения сканера
Одним из важнейших критериев при выборе сканера или бесплёночной цифровой камеры должно быть максимальное входное разрешение конкретного сканирующего устройства. Изготовители определяют это максимальное значение двумя способами: как оптическое разрешение или как интерполированное разрешение.
Оптическое разрешение
Оптическое разрешение описывает объём реальной информации, который может ввести оптическая система сканирующего устройства. Факторы, определяющие оптическое разрешение, зависят от типа оцифровывающего устройства. В планшетных, листовых, ручных сканерах и многих сканерах для обработки слайдов и диапозитивов максимальное оптическое разрешение зависит от трёх факторов:
а). Количества отдельных датчиков в линейке ПЗС в перемещающейся сканирующей головке. ПЗС («приборы с зарядовой связью») — это твердотельный электронный компонент, состоящий из множества крошечных датчиков, которые регистрируют аналоговый электрический заряд, пропорциональный интенсивности падающего на них света).
b). Максимальной ширины оригинала, который может обработать сканер. Например, линейка ПЗС из 5100 ячеек в сканере, принимающем оригиналы шириной до 8,5 дюймов, позволяет получить максимальное горизонтальное оптическое разрешение 600 ppi.
с). Расстояние смещения сканирующей головки по оригинальному изображению. Оно определяет вертикальное разрешение, которое может быть выше, чем горизонтальное.
В цифровых фото- и видеокамерах, а также некоторых сканерах для обработки диапозитивов обычно используется прямоугольная матрица (а не перемещающаяся линейка) ПЗС, определяющая общее число пикселов, которые могут вводиться по любому направлению.
Примечание: Изготовители планшетных сканеров часто приводят вертикальное оптическое разрешение вдвое большее, чем горизонтальное, например, 600 х 1200 ppi. Механизм перемещения этих сканеров отрабатывает «полушаги», сдвигая головку на половину пиксела за шаг, что приводит к перекрыванию пикселов. Для получения окончательного значения уровней цвета или серого сканер должен выполнить математическое усреднение. «Истинное» оптическое разрешение этих сканеров ниже (например, 600 х 600 ppi), оно также приводит к наилучшей чёткости изображения и уменьшает шум.
Интерполированное разрешение
С другой стороны, максимальное интерполированное разрешение устройства представляет кажущийся объём информации, который сканер может вводить с помощью алгоритмов реализуемых процессором и/или программным обеспечением. Алгоритмы интерполяции не добавляют реальных деталей в изображение, они лишь добавляют пикселы, просто усредняя значения цвета или градаций серого в смежных пикселах и вставляя между ними новый пиксел. Интерполированное разрешение часто в два или более раз выше, чем оптическое.
Остерегайтесь маркетинговых уловок — там, где важно качество, имеет значение только оптическое разрешение. Интерполяция добавляет «псевдоинформацию», которая может быть приемлема для дешёвых публикаций или компаний с ограниченными средствами, но никогда не будет работать в цветных изображениях большого формата, где жизненно важны детальная структура и широкий тоновый диапазон. Интерполяция также приводит к «смягчению» изображения и необходимости более серьёзного увеличения контраста на границах между областями. Если вы часто сканируете для высококачественной печати, то лишь выиграете, вложив дополнительные деньги в сканер с более высоким оптическим разрешением.
Атрибуты пикселов
Каждый пиксел растрового изображения имеет четыре основные характеристики — размер, тоновое значение, глубину цвета и позицию. Эти четыре атрибута определяют разрешение, причем каждый это делает по-своему.
Размер пиксела (физический размер)
Все пикселы одного изображения имеют одинаковый размер. Изначально размер пиксела определён разрешением, с которым было сканировано или оцифровано изображение. Так, разрешение в 600 пикселов на дюйм указывает, что размер каждого пиксела равен 1/600 дюйма. При более высоком входном разрешении генерируются пикселы меньшего размера, что, в свою очередь, обеспечивает большее количество информации и вероятных деталей на единицу измерения, а также большую плавность тоновых переходов. При более низком разрешении пикселы имеют больший размер, наблюдается меньше деталей на единицу измерения и изображение имеет мозаичную структуру. Размер и количество пикселов определяют количество информации, содержащейся в изображении. Можно изменить размер пиксела в любой момент производственного процесса, изменив разрешение. При этом если изображение выводится на печать, то автоматически изменится размер отпечатка.
Значение цвета или тона (номер цвета)
Сканеры и цифровые камеры присваивают определенное значение цвета или оттенка серого каждому пикселу изображения. Эффект непрерывности тона возникает из-за того, что пикселы очень малы и соседние пикселы только немного отличаются друг от друга по цвету или тону. Изображения, сканированные с помощью устройств с широким динамическим диапазоном, наилучшим образом передают непрерывность тона. Динамический диапазон — это аппаратная чувствительность сканера к тончайшим цветовым оттенкам на сканируемом изображении. Динамический диапазон зависит от битовой разрядности сканера, соотношения сигнал/шум, типа лампы подсветки, непрерывной коррекции тона и т.д. Чем дороже сканер, тем шире его динамический диапазон.
Глубина цвета (битовая разрядность)
Конечно, каждому отдельному пикселу можно приписать лишь одно значение, но существует такая характеристика, как разрядность битового представления цвета (или глубина цвета) оцифровывающего устройства, определяющая количество возможных цветов или тонов. Каждый дополнительный бит приводит к росту размера графических файлов и, соответственно, потребности в свободном месте на жёстком диске, хотя при этом увеличивается гладкость переходов между смежными цветами и тонами.
Позиция пиксела (координаты)
Растровое изображение представляет собой сетку дискретных пикселов, каждый из которых имеет определенные горизонтальные и вертикальные координаты внутри сетки. В большинстве основных программ редактирования изображений можно узнать координаты любого пиксела, поместив над ним инструмент Eyedropper (пипетка). Физические размеры сетки, определяемой общим количеством пикселов и разрешением, задают относительное положение пикселов.
Повторная выборка изображений, или ресемплинг
Большинство цифровых изображений имеют следующие размерные характеристики:
1. Физические размеры (длина и ширина) в дюймах (миллиметрах, точках и т.д.). Это, в общем-то, довольно условная величина, которая показывает, какую площадь экрана монитора или страницы при печати на принтере будет занимать данное изображение при масштабе 100%.
2. Печатные (пиксельные) размеры (длина и ширина) в пикселях (процентах).
3. Разрешение (пикселы/дюймы, пикселы/сантиметры). Это определённое соотношение предыдущих величин.
Все 3 вида этих характеристик являются переменными величинами.
Многие профессионалы-графики не понимают, чем изменение физических размеров изображения отличается от повторной выборки. При изменении физических размеров пропорционально изменяется разрешение при неизменном информационном содержании (размере файла). С другой стороны, повторная выборка, или ресемплинг, всегда связана с изменением объёма информации в изображении и может включать независимые изменения любой из трёх (или всех) размерных характеристик файлов. Ресемплинг всегда изменяет количество пикселей и размер файла. Поскольку это влечет за собой интерполяцию и усреднение, повторную выборку следует использовать только в том случае, если сканированное изображение оригинала содержит или слишком много, или слишком мало информации для высококачественного вывода.
Профессионалы художественной графики используют термин субдискретизация (downsampling), или уменьшение размеров изображения, для описания уменьшения числа пикселов в изображении и термин интерполяция (upsampling), или увеличение размеров изображения, чтобы описать увеличение числа пикселов.
Усреднение значений пиксела происходит в обоих случаях. При правильном проведении субдискретизации устраняются ненужные детали, в то время как при увеличении пиксельных размеров изображения добавляются псевдодетали. Оба способа являются компромиссными и воздействуют на качество изображения, но субдискретизация редко приводит к видимому ухудшению качества изображения, потому что она обычно сопровождается уменьшением размера изображения, а увеличение пиксельных размеров изображения почти всегда приводит к ухудшению изображения.
Повторную выборку изображения можно провести с помощью двух базовых методов — ручного масштабирования или через диалоговое окно типа Image Size (размер изображения), где в цифровой форме определяется изменение разрешения или размеров. Второй метод намного точнее и дает возможность точно проконтролировать количество добавляемой или отбрасываемой информации.
Чем руководствоваться при повторной выборке
Используйте алгоритм повторной выборки самого высокого качества, поддерживаемый вашим пакетом редактирования изображений, чтобы минимизировать видимые потери. Так, например, Photoshop предлагает выбор трех опций: Bicubic (бикубическая), Bilinear (билинейная) и Nearest Neighbor (ближайший сосед). Опция Bicubic выполняет наиболее сложное усреднение значений пикселов; метод Bilinear производит более мягкий просмотр, уменьшающий вероятность артефактов; и Nearest Neighbor выполняется быстро, но приводит к более видимой ступенчатости изображения.
Не производите повторную выборку одного изображения более, чем один раз. Каждое изменение объёма информации в изображении связано с потерями, так что не стоит разбираться в причинах ухудшения второго, третьего (и далее) поколения.
Субдискретизация более надежна, чем увеличение пиксельных размеров изображения, с точки зрения уменьшения потерь качества изображения, особенно если физический размер выводимого изображения уменьшается. Детали, потерянные при проведении субдискретизации, все равно нельзя было вывести на печать.
Пример ресемплинга
Как уже было сказано, изменение разрешения не обязательно предполагает ресемплинг. Всего возможны 2 варианта:
1. Изменение разрешения с ресемплингом. При этом всегда изменяется количество пикселей и размер файла. Это часто связано с риском ухудшения качества изображения. Подварианты:
a). При чрезмерном уменьшении разрешения (с понижающим ресемплингом) может возникнуть угроза целостности и детальности изображения («нарастание мозаичности»).
b). При сильном увеличении разрешения (с повышающим ресемплингом) может ухудшиться чёткость и проработка деталей изображения (т.к. процесс интерполяции не добавляет «реальных» деталей). Этот дефект можно частично компенсировать с помощью фильтра наложения нерезкой маски. (Соблюдайте осторожность при наложении нерезкой маски на изображения низкого разрешения — во всех случаях, кроме светлых изображений, это может привести к нежелательным эффектам возникновения ореола).
2. Изменение разрешения без ресемплинга не меняет информационное содержание файла, а только автоматически и пропорционально меняет физические размеры изображения (в мм) так, чтобы оставить неизменными размеры в пикселях по длине и ширине. Можно наоборот — поменять физические размеры изображения — при этом пропорционально изменится разрешение. В любом случае количество пикселей, размер и качество изображения не изменятся.
Рассмотрим примеры повышения и понижения разрешения изображения с ресемплингом и без него (в Adobe Photoshop 5.0):
Исходная картинка:
Файл в формате Color TIFF LZW.
Пример 1. Повышение разрешения (в 2 раза):
a). Без ресемплинга:
Размер файла не изменился.
b). С ресемплингом:
Размер файла возрос в 2,87 раза (примерно в 3 раза).
Пример 2. Понижение разрешения (в 2 раза):
a). Без ресемплинга:
Размер файла не изменился.
b). С ресемплингом:
Размер файла уменьшился в 3,36 раза (примерно в 3 раза).
Ссылки
Связь между ppi, lpi и dpi
DPI в Википедии
Разрешение (компьютерная графика) в Википедии
Автор: monday2000.
24 мая 2006 г.
E-Mail (monday2000 [at] yandex.ru)
Метод пересчета (параметры среды)—Справка | ArcGIS for Desktop
Пересчет – это процесс интерполяции значений пикселов при трансформации набора растровых данных. Он используется, если входные и выходные данные не точно выровнены относительно друг друга, если изменяется размер пиксела, если данные смещаются, или если все это происходит одновременно.
Примечания по использованию
- Опцию ближайшей окрестности (nearest neighbor) следует использовать для категорийных данных, так как новые значения не создаются.
- Билинейная интерполяция и кубическая свертка не должны использоваться с категорийными данными, но они позволяют получить лучшие результаты для непрерывных данных.
Синтаксис диалога
- Метод пересчета – выберите, какой метод пересчета будет использоваться при создании выходных данных.
- Nearest – Выполняет присвоение значений по методу Ближайшая окрестность (nearest neighbor assignment) и является самым быстрым методом интерполирования. Он используется в основном для дискретных данных, таких как классификация землепользования, поскольку не будет изменять значения ячеек. Максимальная пространственная погрешность будет составлять половину размера ячейки.
- Bilinear – эта опция выполняет билинейную интерполяцию, и определяет новое значение ячейки на основе средневзвешенного расстояния между центрами четырех ближайших ячеек входного растра. Это полезно для непрерывных данных и вызовет некоторое сглаживание данных.
- Cubic – выполняет кубическую свертку и определяет новое значение ячейки на основе гладкой кривой, проведенной через 16 ближайших центров ячеек входного растра. Она подходит для непрерывных данных, хотя может привести к тому, что выходной растр будет содержать значения, выходящие за пределы радиуса входного растра. Геометрически менее искаженный, чем растр, запущенный путем запуска алгоритма изменения разрешения Ближайший сосед. Недостатком опции Кубической свертки является то, что она требует больше времени обработки. В некоторых случаях, значения выходных ячеек в результате могут выходить за пределы радиуса значений входных ячеек. Если это неприемлемо, используйте метод Билинейной интерполяции.
Синтаксис скриптов
arcpy.env.resamplingMethod = «interpolation_type»
| Parameters | Описание |
|---|---|
interpolation_type (Дополнительно) | Используемый метод изменения разрешения:
|
import arcpy
# Set the resampling method environment to bilinear interpolation.
arcpy.env.resamplingMethod = "BILINEAR"
Связанные темы
Отзыв по этому разделу?Метод пересчета (параметры среды)—ArcGIS Pro
В этом разделе
Инструменты, использующие параметр среды Пересчет, интерполируют значения пикселов при преобразовании набора растровых данных. Он используется, если входные и выходные данные не точно выровнены относительно друг друга, если изменяется размер пиксела, если данные смещаются, или если все это происходит одновременно.
Примечания по использованию
- Опцию ближайшей окрестности следует использовать для категорийных данных, так как новые значения не создаются.
- Билинейная интерполяция и кубическая свертка не должны использоваться с категорийными данными, но они позволяют получить лучшие результаты для непрерывных данных.
Синтаксис диалога
- Метод пересчета — выберите, какой метод пересчета будет использоваться при создании выходных данных.
- Ближайший – Выполняет присвоение значений по методу Ближайшая окрестность и является самым быстрым методом интерполирования. Он используется в основном для дискретных данных, таких как классификация землепользования, поскольку не будет изменять значения ячеек. Максимальная пространственная погрешность будет составлять половину размера ячейки.
- Билинейный – эта опция выполняет билинейную интерполяцию, и определяет новое значение ячейки на основе средневзвешенного расстояния между центрами четырех ближайших ячеек входного растра. Это полезно для непрерывных данных и вызовет некоторое сглаживание данных.
- Кубический – выполняет кубическую свертку и определяет новое значение ячейки на основе гладкой кривой, проведенной через 16 ближайших центров ячеек входного растра. Она подходит для непрерывных данных, хотя может привести к тому, что выходной растр будет содержать значения, выходящие за пределы диапазона входного растра. Если это неприемлемо, используйте метод Билинейной интерполяции. Результирующие значения кубической свертки геометрически менее искажены, чем растр, полученный после изменения разрешения методом ближайшего соседа. Недостатком опции Кубической свертки является то, что она требует больше времени обработки.
Синтаксис скриптов
arcpy.env.resamplingMethod = «interpolation_type»
| Параметры | Объяснение |
|---|---|
interpolation_type (Необязательное) | Используются следующие методы изменения разрешения:
|
Пример скрипта
import arcpy
# Set the resampling method environment to bilinear interpolation
arcpy.env.resamplingMethod = "BILINEAR"Связанные разделы
Отзыв по этому разделу?
Сравнение размера изображения и передискретизации в Photoshop: объяснение
Автор Стив Паттерсон.
Есть два способа изменить размер изображения в Photoshop. Вы можете либо изменить размер изображения, либо изменить его размер. Многие люди используют термины изменение размера и передискретизация , как будто они означают одно и то же, но это не так. Между ними есть важное различие.
Как мы увидим в этом руководстве, разница, сколь бы важной она ни была, контролируется не чем иным, как одним флажком в нижней части диалогового окна Размер изображения .
Как я только что упомянул, выбор изменения размера или передискретизации вашего изображения осуществляется в диалоговом окне «Размер изображения», которое находится в меню «Изображение» в верхней части экрана. Разница между изменением размера и передискретизацией связана с тем, изменяете ли вы количество пикселей в изображении или, как это называет Photoshop, изменяете размер пикселей изображения на пикселей.Если вы сохраняете количество пикселей в изображении одинаковым и просто меняете размер, при котором изображение будет печататься, или, в терминологии Photoshop, измените размер документа на изображения, это называется , изменяя размер . Если, с другой стороны, вы физически меняете количество пикселей в изображении, это называется передискретизацией .
Загрузите это руководство в виде готового к печати PDF-файла!
Опять же, просто чтобы убедиться, что мы пока на одной странице:
- Изменение размера изображения: При изменении размера изображения будет напечатано без изменения количества пикселей в изображении.
- Передискретизация изображения: Изменение количества пикселей в изображении.
Смотрите? Вы уже знаете достаточно, чтобы в следующий раз, когда кто-то назовет изменение количества пикселей в изображении , изменив размер изображения , вы можете с гордостью посмотреть им в глаза и сказать: «Я думаю, что вы действительно хотели сказать здесь, Боб. , заключается в том, что вы собираетесь выполнить повторную выборку изображения, не изменяя его размер «. Если, конечно, этого человека зовут Боб. И если предположить, что вы больше не хотите, чтобы Боб сильно любил вас, потому что вы думаете, что все это знаете.
Давайте более подробно рассмотрим разницу между изменением размера и повторной выборкой.
Изменение размера и изменение размера изображения
Для начала нам понадобится фото. Этот будет хорошо работать:
Давайте посмотрим, что диалоговое окно «Размер изображения» сообщает нам об этом изображении. Чтобы получить к нему доступ, я перейду в меню Image вверху экрана и выберу Image Size :
.Как упоминалось ранее в разделах «Разрешение изображения» и «Изменение размера изображения», диалоговое окно «Размер изображения» в Photoshop разделено на два основных раздела — раздел «Размер пикселей» вверху и раздел «Размер документа » под ним.Раздел Pixel Dimensions сообщает нам ширину и высоту нашего изображения в пикселях, а также сообщает нам размер файла нашего изображения. Раздел «Размер документа» сообщает нам, насколько большое или маленькое изображение будет напечатано, в зависимости от разрешения изображения, которое мы также установили в разделе «Размер документа». Вы можете думать о разделе «Размеры в пикселях» как о разделе, который вы хотели бы изменить, если бы вы работали над изображением для Интернета или просто для отображения на экране компьютера, в то время как раздел «Размер документа» используется, когда вам нужно контролировать размер ваше изображение будет напечатано.
Итак, в общем:
- Размер пикселей = web
- Размер документа = печать
Давайте взглянем на часть Pixel Dimensions диалогового окна Image Size, чтобы увидеть, насколько велико наше изображение в пикселях.
Здесь мы видим, что фотография довольно большая, с шириной 3456 пикселей и высотой 2304 пикселей. В сумме это почти 8 миллионов пикселей (использовалась камера на 8 Мп, отсюда и 8 миллионов пикселей на фотографии), что дает нам много информации об изображении для работы в Photoshop.
Теперь посмотрим на раздел «Размер документа»:
Раздел «Размер документа» показывает нам текущее разрешение печати изображения, которое в данном случае составляет 72 пикселя на дюйм, и показывает, насколько большое изображение будет напечатано при этом разрешении, которое при 72 пикселях на дюйм даст нам изображение 48 дюймов в ширину и 32 дюйма в высоту. Если вы читали раздел о том, как разрешение печати влияет на качество изображения, вы знаете, что даже если при печати фотографии мы получим очень большое изображение, разрешение всего 72 пикселя на дюйм просто недостаточно. чтобы обеспечить качество изображения, близкое к профессиональному.Для этого нам пришлось бы изменить разрешение как минимум до 240 пикселей на дюйм, в то время как 300 пикселей на дюйм считаются профессиональным стандартом печати.
Прежде чем мы продолжим, в диалоговом окне «Размер изображения» под разделом «Размер документа» есть еще три параметра:
- Стили масштабирования
- Сохранение пропорций
- Увеличить изображение
Первый, Scale Styles , имеет отношение к стилям слоя и тому, как на них влияет изменение размера или передискретизация изображения.Мы проигнорируем этот вариант, поскольку он не имеет отношения к данной теме. Второй параметр, Constrain Proportions , который включен по умолчанию, связывает ширину и высоту изображения вместе, так что если вы, например, измените ширину изображения, Photoshop автоматически изменит высоту и наоборот. наоборот, чтобы пропорции изображения остались прежними и не искажались. Обычно это именно то, что вам нужно, но если по какой-то причине вы хотите иметь возможность изменять ширину и высоту независимо друг от друга, просто снимите флажок «Сохранить пропорции».
Важнейшая опция «Resample Image»
Наконец, мы подошли к одной из наиболее важных опций в диалоговом окне «Размер изображения» — Resample Image . Помните, в начале этого руководства я сказал, что разница между изменением размера и передискретизацией изображения контролируется не более чем одним параметром флажка? Это оно! Это параметр, который определяет, ли мы изменяем размер нашего изображения или передискретизируем его . Опять же, изменение размера сохраняет размеры в пикселях (количество пикселей в изображении) одинаковыми и просто изменяет размер, при котором изображение будет печататься, в то время как передискретизация физически изменяет количество пикселей в изображении.По умолчанию опция Resample Image отмечена, что означает, что диалоговое окно Image Size теперь по сути является диалоговым окном Image Resample , хотя вверху по-прежнему просто написано «Image Size».
Чтобы лучше понять разницу между тем, что мы называем версией «Изменение размера изображения» и версией «Изменение размера изображения» диалогового окна «Размер изображения», вот скриншот диалогового окна «Размер изображения» с помощью «Изменить размер изображения». опция отмечена, а ниже приведен снимок экрана, на котором показано, как выглядит размер изображения при снятом флажке «Resample Image»:
Во-первых, с установленной опцией «Resample Image», как это по умолчанию:
И вот он с снятым флажком «Resample Image»:
Вы заметите разницу? Если флажок «Resample Image» снят, если вы посмотрите на раздел «Pixel Dimensions» диалогового окна, вы увидите, что, хотя Photoshop все еще сообщает нам, сколько пикселей находится в изображении для ширины и высоты, мы больше не в состоянии изменить эти числа.Они указаны только для информации, и все, что мы можем сделать на этом этапе, — это изменить размер нашего изображения, которое будет печататься, с помощью раздела «Размер документа». Однако при установленном флажке «Resample Image» размеры в пикселях отображаются внутри белых полей ввода, внутри которых мы можем щелкнуть и ввести новые значения, эффективно изменяя количество пикселей в нашем изображении.
Также обратите внимание, что параметры «Масштабировать стили» и «Ограничить пропорции» в нижней части диалогового окна «Размер изображения» неактивны, если флажок «Изменить размер изображения» не установлен:
Scale Styles выделен серым цветом, потому что это вызывает беспокойство только при изменении количества пикселей в изображении.Поскольку у нас нет возможности изменять количество пикселей в изображении, если флажок «Изменить размер изображения» снят, параметр «Масштабировать стили» не имеет значения ни для нас, ни для Photoshop.
«Ограничить пропорции» отображается серым цветом, когда флажок «Изменить размер изображения» не установлен, потому что мы больше не можем физически изменять количество пикселей в изображении, поэтому пропорции изображения фиксированы. Если изображение имеет ширину 20 пикселей и высоту 10 пикселей, то независимо от того, насколько большим или маленьким мы его распечатываем, ширина всегда будет в два раза больше высоты.Если вы измените значение ширины в разделе «Размер документа», изменится и высота, и значение разрешения. Измените значение высоты, и значения ширины и разрешения изменятся. Измените значение разрешения, и, как вы уже догадались, изменятся значения ширины и высоты. Все, что мы можем сделать сейчас, это изменить размер изображения, которое будет напечатано, либо введя новые значения для размера документа, либо изменив разрешение. Опять же, как и в случае с параметром «Масштабировать стили», параметр «Сохранить пропорции» не имеет значения ни для нас, ни для Photoshop, когда все, что мы делаем, это изменение размера печати изображения.
Параметры интерполяции изображения при передискретизации изображений
Наконец, есть еще одна опция, которая неактивна при снятом флажке Resample Image, и это раскрывающийся список справа от опции Resample Image:
В этом раскрывающемся списке вы можете выбрать один из «алгоритмов интерполяции» Photoshop. Это причудливая фраза для того, что по сути означает, как Photoshop обрабатывает отбрасывание пикселей при передискретизации изображения до меньшего размера и как он обрабатывает добавление пикселей при передискретизации изображения до большего размера.Что касается Photoshop CS2, есть три основных варианта на выбор — бикубическая, бикубическая резкость и бикубическая сглаживание, и знание того, когда использовать, какой вариант может иметь большое значение для качества изображения. Мы подробно рассмотрим различия между ними в другом уроке, а пока вот общее правило:
- Бикубическая резкость: Используйте этот параметр при передискретизации изображения на меньше для наилучшего качества изображения
- Bicubic Smoother: Используйте этот параметр при передискретизации изображения на больше для наилучшего качества изображения
- Bicubic: На самом деле мало используется сейчас, когда доступны Bicubic Sharper и Bicubic Smoother
Опять же, эти параметры здесь неактивны, потому что они применяются только к изображениям, которые подвергаются повторной дискретизации.Если все, что вы делаете, — это изменение размера изображения, которое будет печататься на бумаге, эти параметры не применяются.
Сводка
- Изменение размера изображения сохраняет количество пикселей в вашем изображении одинаковым и влияет только на размер вашего изображения при печати (размер документа).
- Передискретизация изображения физически изменяет количество пикселей в вашем изображении (размеры пикселей).
- Параметр « Resample Image» в нижней части диалогового окна «Размер изображения» определяет, изменяете ли вы размер или передискретизируете изображение.
- Если для параметра Resample Image выбрано значение , вы передискретизируете изображение. С снятым флажком вы просто изменяете размер изображения.
- Передискретизация изображений путем изменения значений ширины и высоты в разделе «Размеры в пикселях» диалогового окна «Размер изображения» в основном используется при оптимизации изображений для Интернета.
- Изменение размера изображения путем изменения значений ширины, высоты и / или разрешения в разделе «Размер документа» диалогового окна «Размер изображения» используется для печати.
И вот оно!
Передискретизация — Статистические решения
Передискретизация — это метод, который состоит из отрисовки повторяющихся отсчетов из исходных отсчетов данных. Метод повторной выборки — это непараметрический метод статистического вывода. Другими словами, метод повторной выборки не включает использование общих таблиц распределения (например, таблиц нормального распределения) для вычисления приблизительных значений вероятности p.
Повторная выборка включает в себя выборку случайных наблюдений с заменой исходной выборки данных таким образом, чтобы каждое число выбранной выборки имело количество наблюдений, аналогичных исходной выборке данных. Из-за замены отобранное количество выборок, используемых методом ресэмплинга, состоит из повторяющихся случаев.
Узнайте, как мы помогаем редактировать главы вашей диссертации
Согласование теоретической основы, сбор статей, обобщение пробелов, формулирование четкой методологии и плана данных, а также описание теоретических и практических последствий вашего исследования — это часть наших комплексных услуг по редактированию диссертаций.
- Своевременно вносить экспертизу по редактированию диссертаций на главы 1-5.
- Отслеживайте все изменения, а затем работайте с вами, чтобы писать научные статьи.
- Постоянная поддержка по обратной связи с комитетом, сокращение количества исправлений.
Resampling создает уникальное распределение выборки на основе фактических данных. Метод повторной выборки использует экспериментальные методы, а не аналитические, для создания уникального распределения выборки.Метод повторной выборки дает объективные оценки, поскольку он основан на объективных выборках всех возможных результатов данных, изучаемых исследователем.
Передискретизация также известна как начальная загрузка или оценка Монте-Карло. Чтобы понять концепцию повторной выборки, исследователь должен понимать термины бутстрапирование и оценка Монте-Карло:
- Метод начальной загрузки, который эквивалентен методу повторной выборки, использует повторяющиеся выборки из исходной выборки данных для вычисления статистики теста.
- Оценка Монте-Карло, которая также эквивалентна методу начальной загрузки, используется исследователем для получения результатов повторной выборки.
Допущения
Этот метод повторной выборки обычно игнорирует параметрические допущения, которые касаются игнорирования характера основного распределения данных. Таким образом, метод основан на непараметрических предположениях.
При повторной выборке конкретных требований к размеру выборки нет. Следовательно, чем больше выборка, тем надежнее доверительные интервалы, полученные методом повторной выборки.
Существует повышенная опасность искажения данных. Проблемы такого типа можно легко решить, объединив метод повторной выборки с процессом перекрестной проверки.
Передискретизация в SPSS
В SPSS исследователь может выполнить метод повторной выборки следующим образом:
Выбрав «Непараметрические тесты» в меню анализа, исследователь нажимает «Два независимых выборочных теста», где исследователь находит кнопку «Точный».Это позволяет исследователю делать выбор между типами оценок значимости. Один из таких вариантов, который может сделать исследователь, включает метод «Монте-Карло», который также является методом начальной загрузки и повторной выборки.
Statistics Solutions может помочь с определением размера выборки / анализа мощности для вашего исследования. Чтобы узнать больше, посетите нашу веб-страницу, посвященную анализу размера выборки / мощности, или свяжитесь с нами сегодня.
Дополнительные страницы ресурсов, связанные с передискретизацией:
Статистическое обучение (II): выборка данных и повторная выборка | Дениз Чен
источник: Iconic Bestiary, через shutterstockСтатистическая выборка предполагает использование подмножества примеров из всего населения.В настоящее время модели машинного обучения становятся более сложными и состоят из миллионов параметров, вводимых в последнюю модель, такую как модель BERT или ResNet, содержащую миллионы параметров. С подвыборкой набора данных обучение такой сложной модели относительно эффективно по времени, хотя часто это занимает от пары дней до недели. Выборка данных помогает определить лучшую производительность поиска в сетке по параметрам. С другой стороны, с точки зрения повторной выборки данных, метод создает синтетические данные для второстепенной группы среди совокупности данных или использует реплицированные данные из исходного набора данных.Это помогает модели не перегружаться по основному классу, который содержит существенные выборки данных.
В этой статье вы узнаете:
(1) Каковы популярные методы выборки данных
(2) Какие популярные методы повторной выборки данных
(3) Применение выборки и повторной выборки данных в Python
Существует два основных метода выборки данных:
- Случайная выборка: Подмножеству данных дается равная вероятность быть выбранным.
На графике 1 ниже видно, что есть 3 отдельные группы выборок разного размера, подвыборки выбираются с равной вероятностью 1 / n.
Участок 1: случайная выборка- Стратифицированная выборка: Учитывая различный размер набора данных в каждом классе, подмножество выбирается из каждой группы на основе процентного отношения к генеральной совокупности.
На графике2 ниже видно, что есть 3 отдельные группы выборок разного размера, подвыборки выбираются с относительной вероятностью для каждой группы.Поскольку имеется 12, 12 и 6 точек данных, разбросанных по группе A, группе B и группе C. Подвыборки выбираются с вероятностью 2: 2: 1, определяемой размером группы.
График 2: стратифицированная выборкаЭффективным способом создания копии набора данных является оценка параметров модели. И процесс повторяется несколько раз.
Два популярных метода повторной выборки:
- Перекрестная проверка методом K-Fold: Набор данных разделен на k групп, и определенное количество наборов данных будет распределено в обучающий набор данных, тогда как удерживаемый набор данных будет назначен для тестового набора данных.Этот метод применяется, когда набор обучающих данных довольно мал, чтобы избежать проблемы переобучения.
- BootStrap: Хотя набор данных не следует какому-либо определенному распределению, например нормальному, X-квадрату и T-ученику, BootStrap применяется для оценки статистики и потенциального распределения, лежащего под набором данных. На приведенном ниже графике сначала берется группа подвыборки из исходного набора данных. Затем мы передискретизируем исходную подвыборку B раз с фиксированной длиной (n) независимо от повторяющихся выборок, взятых из экстракции.Для каждой бутстраповой выборки она оценивается параметром (θ). Следовательно, бутстрап — это метод, используемый для аппроксимации распределения вероятностей , когда одним из распространенных подходов является принятие эмпирической функции распределения с помощью оценок (θ).
Учитывая несбалансированный набор данных, мы часто сталкиваемся с проблемой, когда большая часть данных попадает в основной класс, тогда как некоторые данные попадают в класс меньшинства.Чтобы преодолеть низкую производительность обучения модели для таких несбалансированных данных, в первую очередь предлагается использовать методы избыточной и недостаточной выборки для получения равномерно распределенных данных, попадающих в каждый класс.
Теперь я рассмотрю пример набора данных
(A) Недостаточная выборка с использованием пакета Python
Есть несколько алгоритмов недостаточной выборки для применения в имблеарне python. (1) ClusterCentroids: Используйте центроид метода K-средних , чтобы синтезировать размер каждого класса для сокращения данных.Обратите внимание, что данные должны быть сгруппированы в кластер для применения метода ClusterCentroid.
(2) RandomUnderSampler: Выберите подмножество данных для целевого класса, чтобы сбалансировать набор данных. Он включает метод bootstrap , задав для параметра замены значение True, в то время как подвыборка рисуется независимо от каждого класса.
Дополнительную ссылку на метод недостаточной выборки с использованием Python можно найти здесь
(B) Передискретизация (метод синтетической передискретизации меньшинства SMOTE)
Этот метод используется для выбора ближайших соседей в пространстве функций, разделенных примерами добавление строки и создание новых примеров вдоль строки.Метод не просто генерирует дубликаты из превосходящего по численности класса, но применяет K-ближайших соседей для генерации синтетических данных. На графике 3 ниже синий кружок — это исходные данные, еще одна синяя точка, обведенная красным, — ближайший сосед, а розовая точка — синтетический. Ссылка на статью для более подробной информации об алгоритме SMOTE.
Сюжет 3: Как работает SMOTEПопробуй применить метод повторной выборки для кредита Данные о мошенничестве:
Данные используются для определения того, является ли это обычной или мошеннической транзакцией от Kaggle Challenge.Чтобы защитить индивидуальную конфиденциальность информации о кредитной карте, функции были масштабированы с помощью метода анализа основных компонентов (PCA) , а имя функций было переименовано с V1 в V28 вместе с общим количеством и классами с 0 и 1, а также 1 означает мошенническую транзакцию и 0 в противном случае.
Процент несбалансированных классов среди данных транзакцийИз гистограммы, показанной ниже, мы видим, что данных без мошенничества составляет 99,82% , тогда как данных о мошенничестве составляет 0.17% .
Гистограмма распределения классовКак поступать с таким несбалансированным набором данных?
Подвыборка. Равномерно распределите классы между 50 и 50, чтобы модель могла изучить один и тот же размер выборки для каждого класса.
Недостаточно выборки основного класса и сопоставить размер данных с классом меньшинства Гистограмма равномерно распределенных классовПримечание: Разделение данных для обучения модели и оценки
Нам необходимо разделить исходный фрейм данных перед тем, как приступить к случайной недостаточной или избыточной выборке.Цель состоит в том, чтобы протестировать на исходных данных, а не из ручного синтетического набора данных .
Из статьи мы рассмотрим некоторые популярные методы выборки и повторной выборки данных. Часто возникает проблема с несбалансированным набором данных или с огромным набором данных. Чтобы преодолеть проблему переобучения, это действительно эффективный способ применения метода выборки данных для получения из них подвыборок, в то время как повторная выборка данных, такая как методы передискретизации и понижающей выборки, является хорошим подходом для балансировки данных из каждого класса.Наконец, в коде Python показано, как сгенерировать метод повторной выборки данных для каждого алгоритма и применить его к набору данных. Приятных выходных 🙂
Источник: memeshappen.comСпасибо за интерес к статье. Не стесняйтесь оставлять комментарии ниже и приветствовать любые отзывы. Как новичок, пишущий этот пост в блоге, я буду публиковать больше статей, связанных с наукой о данных. Если вы энтузиаст данных, следуйте моему Medium . Оставайтесь с нами 🙂
Нежное введение в статистическую выборку и повторную выборку
Последнее обновление 8 августа 2019 г.
Данные — это валюта прикладного машинного обучения.Поэтому важно как собирать, так и эффективно использовать.
Выборка данных относится к статистическим методам отбора наблюдений из области с целью оценки параметра совокупности. В то время как передискретизация данных относится к методам экономичного использования собранных данных для улучшения оценки параметра совокупности и помощи в количественной оценке неопределенности оценки.
Как выборка данных, так и повторная выборка данных являются методами, которые требуются в задаче прогнозного моделирования.
В этом руководстве вы познакомитесь с методами статистической выборки и статистической повторной выборки для сбора и наилучшего использования данных.
После прохождения этого руководства вы будете знать:
- Выборка — это активный процесс сбора данных наблюдений с целью оценки переменной совокупности.
- Повторная выборка — это методология экономичного использования выборки данных для повышения точности и количественной оценки неопределенности параметра генеральной совокупности.
- Методы передискретизации фактически используют вложенный метод передискретизации.
Начните свой проект с моей новой книги «Статистика для машинного обучения», включающей пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
Нежное введение в статистическую выборку и повторную выборку
Фотография Эда Дуненса, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на 2 части; их:
- Статистическая выборка
- Статистическая передискретизация
Нужна помощь со статистикой для машинного обучения?
Пройдите бесплатный 7-дневный ускоренный курс по электронной почте (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
Статистическая выборка
Каждая строка данных представляет собой наблюдение о чем-то в мире.
При работе с данными мы часто не имеем доступа ко всем возможным наблюдениям. Это могло быть по многим причинам; например:
- Проведение дополнительных наблюдений может быть трудным или дорогостоящим.
- Может быть сложно собрать все наблюдения вместе.
- Ожидается, что в будущем будет сделано больше наблюдений.
Наблюдения, сделанные в домене, представляют собой образцы некоторой более широкой идеализированной и неизвестной совокупности всех возможных наблюдений, которые могут быть сделаны в домене. Это полезная концептуализация, поскольку мы можем видеть разделение и взаимосвязь между наблюдениями и идеализированной совокупностью.
Мы также можем видеть, что даже если мы намерены использовать инфраструктуру больших данных для всех доступных данных, эти данные по-прежнему представляют собой выборку наблюдений из идеализированной совокупности.
Тем не менее, мы можем захотеть оценить свойства населения. Мы делаем это, используя образцы наблюдений.
Выборка состоит из отбора некоторой части популяции для наблюдения, чтобы можно было что-то оценить обо всей популяции.
— Страница 1, Выборка, Третье издание, 2012 г.
Как взять образец
Статистическая выборка — это процесс отбора подмножеств примеров из совокупности с целью оценки свойств совокупности.
Отбор проб — активный процесс. Существует цель оценки свойств совокупности и контроля над тем, как будет происходить отбор проб. Этот контроль не влияет на процесс, который генерирует каждое наблюдение, например, на проведение эксперимента. Таким образом, выборка как поле находится между чистым неконтролируемым наблюдением и контролируемым экспериментированием.
Выборка обычно отличается от тесно связанной области экспериментального дизайна тем, что в экспериментах сознательно возмущают некоторую часть популяции, чтобы увидеть, каков эффект этого действия.[…] Отбор выборки также обычно отличается от наблюдательных исследований, в которых практически нет контроля над тем, как были получены наблюдения за популяцией.
— Страницы 1-2, выборка, третье издание, 2012 г.
Выборка дает множество преимуществ по сравнению с работой с более полными или полными наборами данных, включая меньшую стоимость и большую скорость.
Для выполнения выборки требуется, чтобы вы тщательно определили свою популяцию и метод, с помощью которого вы будете выбирать (и, возможно, отклонять) наблюдения, которые будут частью вашей выборки данных.Это вполне может быть определено параметрами совокупности, которые вы хотите оценить с помощью выборки.
Некоторые аспекты, которые следует учитывать перед сбором выборки данных, включают:
- Пример цели . Свойство населения, которое вы хотите оценить с помощью выборки.
- Население . Объем или область, из которой теоретически могут быть сделаны наблюдения.
- Критерии отбора . Методология, которая будет использоваться для принятия или отклонения наблюдений в вашей выборке.
- Размер выборки . Количество наблюдений, составляющих выборку.
Некоторые очевидные вопросы […] заключаются в том, как лучше всего получить выборку и провести наблюдения, и, когда данные выборки будут под рукой, как лучше всего использовать их для оценки характеристик всей совокупности. Получение результатов наблюдений включает вопросы о размере выборки, о том, как ее выбрать, какие методы наблюдения использовать и какие измерения записывать.
— Страница 1, Выборка, Третье издание, 2012 г.
Статистическая выборка — это обширная область исследований, но в прикладном машинном обучении вы, вероятно, будете использовать три типа выборки: простая случайная выборка, систематическая выборка и стратифицированная выборка.
- Простая случайная выборка : Выборки берутся с равномерной вероятностью из области.
- Систематическая выборка : образцы берутся с использованием заранее заданного шаблона, например, с интервалами.
- Стратифицированная выборка : Выборки отбираются в рамках заранее определенных категорий (т.е. страты).
Хотя это наиболее распространенные типы выборки, с которыми вы можете столкнуться, существуют и другие методы.
Ошибки выборки
Выборка требует, чтобы мы сделали статистический вывод о совокупности на основе небольшого набора наблюдений.
Мы можем обобщить свойства от выборки до генеральной совокупности. Этот процесс оценки и обобщения намного быстрее, чем работа со всеми возможными наблюдениями, но он будет содержать ошибки. Во многих случаях мы можем количественно оценить неопределенность наших оценок и добавить полосы ошибок, такие как доверительные интервалы.
Есть много способов внести ошибки в вашу выборку данных.
Два основных типа ошибок включают систематическую ошибку выборки и ошибку выборки.
- Смещение выбора . Возникает, когда метод построения наблюдений каким-либо образом искажает выборку.
- Ошибка выборки . Это вызвано случайным характером наблюдений при рисовании, которые каким-то образом искажают выборку.
Могут присутствовать другие типы ошибок, такие как систематические ошибки в способах проведения наблюдений или измерений.
В этих и других случаях статистические свойства выборки могут отличаться от того, что можно было бы ожидать от идеализированной совокупности, что, в свою очередь, может повлиять на свойства оцениваемой совокупности.
Простые методы, такие как просмотр необработанных наблюдений, сводной статистики и визуализаций, могут помочь выявить простые ошибки, такие как искажение измерений и неполнота или недопредставленность класса наблюдений.
Тем не менее, следует проявлять осторожность как при отборе проб, так и при составлении выводов о популяции во время отбора проб.
Статистическая передискретизация
Когда у нас есть выборка данных, ее можно использовать для оценки параметра совокупности.
Проблема в том, что у нас есть только одна оценка параметра популяции, при этом мы мало знаем об изменчивости или неопределенности оценки.
Один из способов решения этой проблемы — многократная оценка параметра совокупности по нашей выборке данных. Это называется передискретизацией.
Статистические методы повторной выборки — это процедуры, которые описывают, как с экономической точки зрения использовать доступные данные для оценки параметра совокупности.Результатом может быть как более точная оценка параметра (например, взятие среднего из оценок), так и количественная оценка неопределенности оценки (например, добавление доверительного интервала).
Методы передискретизации очень просты в использовании и не требуют больших математических знаний. Это методы, которые легко понять и реализовать по сравнению со специализированными статистическими методами, для выбора и интерпретации которых могут потребоваться глубокие технические навыки.
Методы передискретизации […] просты в освоении и просты в применении.Они не требуют математики, кроме вводной алгебры в средней школе, и применимы в исключительно широком диапазоне предметных областей.
— Страница xiii, Методы повторной выборки: Практическое руководство по анализу данных, 2005.
Обратной стороной методов является то, что они могут быть очень дорогими в вычислительном отношении, требуя десятков, сотен или даже тысяч повторных выборок для получения надежной оценки параметра совокупности.
Ключевой идеей является повторная выборка исходных данных — либо напрямую, либо с помощью подобранной модели — для создания репликационных наборов данных, из которых можно оценить изменчивость интересующих квантилей без долгих и подверженных ошибкам аналитических расчетов.Поскольку этот подход включает в себя повторение исходной процедуры анализа данных с множеством реплицируемых наборов данных, их иногда называют компьютерными методами.
— Стр. 3, Методы начальной загрузки и их применение, 1997.
Каждая новая подвыборка из исходной выборки данных используется для оценки параметра совокупности. Затем выборку оцененных параметров совокупности можно рассмотреть с помощью статистических инструментов, чтобы количественно оценить ожидаемое значение и дисперсию, обеспечивая меры неопределенности оценки.
Статистические методы выборки могут использоваться при выборе подвыборки из исходной выборки.
Ключевое отличие состоит в том, что процесс необходимо повторять несколько раз. Проблема заключается в том, что между выборками как наблюдениями будет некоторая взаимосвязь, которая будет использоваться в нескольких подвыборках. Это означает, что подвыборки и оценочные параметры совокупности не являются строго идентичными и независимо распределенными. Это имеет значение для статистических тестов, выполняемых на выборке предполагаемых параметров популяции ниже по течению, т.е.е. могут потребоваться парные статистические тесты.
Два часто используемых метода передискретизации, с которыми вы можете столкнуться, — это k-кратная перекрестная проверка и бутстрап.
- Загрузочный . Выборки берутся из набора данных с заменой (позволяя одной и той же выборке появляться в выборке более одного раза), где те экземпляры, которые не вошли в выборку данных, могут использоваться для набора тестов.
- k-кратная перекрестная проверка . Набор данных делится на k групп, где каждой группе предоставляется возможность использовать ее в качестве тестового набора, оставив оставшиеся группы в качестве обучающего набора.
Метод k-кратной перекрестной проверки, в частности, пригоден для использования при оценке моделей прогнозирования, которые многократно обучаются на одном подмножестве данных и оцениваются на втором удерживаемом подмножестве данных.
Как правило, методы повторной выборки для оценки производительности модели работают аналогично: подмножество выборок используется для соответствия модели, а оставшиеся выборки используются для оценки эффективности модели. Этот процесс повторяется несколько раз, а результаты обобщаются и суммируются.Различия в методах обычно связаны с методом отбора подвыборок.
— стр. 69, Прикладное прогнозное моделирование, 2013 г.
Метод начальной загрузки может использоваться для той же цели, но это более общий и простой метод, предназначенный для оценки параметра совокупности.
Расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- Перечислите два примера, когда в проекте машинного обучения требуется статистическая выборка.
- Перечислите два примера, когда в проекте машинного обучения требуется статистическая передискретизация.
- Найдите статью, в которой используется метод повторной выборки, который, в свою очередь, использует метод вложенной статистической выборки (подсказка: k-кратная перекрестная проверка и стратифицированная выборка).
Если вы изучите какое-либо из этих расширений, я хотел бы знать.
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Книги
Статьи
Сводка
В этом руководстве вы открыли для себя методы статистической выборки и статистической повторной выборки для сбора и наилучшего использования данных.
В частности, вы выучили:
- Выборка — это активный процесс сбора данных наблюдений с целью оценки переменной совокупности.
- Повторная выборка — это методология экономичного использования выборки данных для повышения точности и количественной оценки неопределенности параметра генеральной совокупности.
- Методы передискретизации фактически используют вложенный метод передискретизации.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Получите доступ к статистике для машинного обучения!
Развить рабочее понимание статистики
… путем написания строк кода на Python
Узнайте, как это сделать, в моей новой электронной книге:
Статистические методы для машинного обучения
Он предоставляет самоучителей по таким темам, как:
Проверка гипотез, корреляция, непараметрическая статистика, повторная выборка и многое другое …
Узнайте, как преобразовать данные в знания
Пропустить академики.Только результаты.
Посмотрите, что внутриResample (Управление данными) —ArcGIS Pro | Документация
Размер ячейки можно изменить, но экстент набора растровых данных останется прежним.
Вы можете сохранить вывод в BIL, BIP, BMP, BSQ, DAT, Esri Grid, GIF, IMG, JPEG, JPEG 2000, PNG, TIFF, MRF, CRF или в любой набор растровых данных базы геоданных.
Параметр «Размер выходной ячейки» может повторно дискретизировать выходные данные до того же размера ячейки, что и существующий растровый слой, или он может выводить ячейки определенного размера X и Y.
Существует четыре варианта параметра «Метод повторной выборки»:
- Ближайший — выполняет назначение ближайшего соседа и является самым быстрым из методов интерполяции. Он используется в основном для дискретных данных, таких как классификация землепользования, поскольку он не изменяет значения ячеек. Максимальная пространственная ошибка будет составлять половину размера ячейки.
- Большинство — выполняет алгоритм большинства и определяет новое значение ячейки на основе наиболее популярных значений в окне фильтра.Он в основном используется с дискретными данными как метод ближайшего соседа; Параметр «Большинство» дает более гладкий результат, чем параметр «Ближайший». Метод передискретизации большинства будет находить соответствующие ячейки 4 на 4 во входном пространстве, которые находятся ближе всего к центру выходной ячейки, и использовать большинство соседей 4 на 4.
- Билинейная — Выполняет билинейную интерполяцию и определяет новое значение ячейки на основе взвешенного среднего расстояния от четырех ближайших центров входных ячеек. Это полезно для непрерывных данных и вызывает некоторое сглаживание данных.
- Кубический — Выполняет кубическую свертку и определяет новое значение ячейки на основе подгонки плавной кривой через 16 ближайших центров входных ячеек. Это подходит для непрерывных данных, хотя может привести к тому, что выходной растр будет содержать значения за пределами диапазона входного растра. Если это неприемлемо, используйте вместо этого билинейный. Выходные данные кубической свертки геометрически менее искажены, чем растр, полученный с помощью алгоритма передискретизации ближайшего соседа. Недостатком варианта Cubic является то, что он требует больше времени на обработку.
Параметры «Билинейный» и «Кубический» не следует использовать с категориальными данными, поскольку значения ячеек могут быть изменены.
Если центр пикселя в выходном пространстве находится точно так же, как один из пикселей во входных ячейках, это конкретное значение ячейки получает все веса, в результате чего выходной пиксель совпадает с центром ячейки. Это повлияет на результат билинейной интерполяции и кубической свертки.
Нижний левый угол выходного набора растровых данных будет тем же расположением координат в пространстве карты, что и нижний левый угол входного набора растровых данных.
Количество строк и столбцов в выходном растре определяется следующим образом:
столбцов = (xmax - xmin) / размер ячейки строки = (ymax - ymin) / размер ячейки Если есть для любого остатка от приведенных выше уравнений выполняется округление количества столбцов и строк.
Этот инструмент поддерживает многомерные растровые данные. Чтобы запустить инструмент на каждом срезе многомерного растра и создать выходной многомерный растр, обязательно сохраните выходные данные в CRF.
Поддерживаемые типы входных многомерных наборов данных включают многомерный растровый слой, набор данных мозаики, сервис изображений и CRF.
Передискретизация растра для дискретных и непрерывных данных
Методы передискретизации в ГИС
При переходе от размера ячейки 5 метров к размеру ячейки 10 метров размер ячейки сетки выходного растра будет другим. При преобразовании растровых данных между разными системами координат центры ячеек не совпадают.
В обеих ситуациях необходимо использовать метод повторной выборки, чтобы указать, как будет формироваться выходная сетка.Но не всегда легко выбрать метод повторной выборки, потому что существует несколько способов пересчета значений ячеек.
Мы выделим, какой метод передискретизации подходит для использования в данных сценариях. Мы также коснемся того, как мы используем эти методы повторной выборки в среде ГИС. Существует четыре распространенных способа пересчета растровых сеток в ГИС.
- Ближайший сосед
- Билинейный
- Кубическая свертка
- Большинство
1.Передискретизация ближайшего соседа
Метод ближайшего соседа не изменяет никаких значений из входного набора растровых данных. Для определения ближайшего центра ячейки выходного растра требуется центр ячейки из набора входных растровых данных. По скорости обработки он обычно самый быстрый из-за своей простоты.
Поскольку повторная выборка ближайшего соседа не изменяет никаких значений в выходном наборе растровых данных, она идеально подходит для категориальных, номинальных и порядковых данных.
Когда следует использовать повторную выборку ближайшего соседа?
Часто вы используете ближайшего соседа для дискретных данных, таких как классификация земного покрова, здания и типы почв, которые имеют четкие границы, а их границы дискретны.
Когда вы передискретизируете этот тип данных, вы должны использовать передискретизацию ближайшего соседа. Например, если у вас есть растровая сетка классификации земного покрова, ближайший сосед будет принимать значение центра ячейки.
Если сельское хозяйство имеет дискретное значение 7, метод ближайшего соседа никогда не присвоит ему значение 7.2. Он просто включает в себя получение выходного значения из центра ближайшей ячейки входного слоя.
2. Билинейная интерполяция
Билинейная интерполяция — это метод вычисления значений местоположения сетки на основе четырех соседних ячеек сетки . Он присваивает значение выходной ячейки, беря средневзвешенное значение четырех соседних ячеек в изображении для генерации новых значений.
Сглаживает сетку выходного растра, но не так сильно, как кубическая свертка.Это полезно при работе с непрерывными наборами данных, не имеющими четких границ.
Когда следует использовать билинейную передискретизацию?
Растры температурных градиентов, цифровые модели высот и сетки годовых осадков являются примерами того, когда следует использовать билинейную интерполяцию.
Например, растры шумовых расстояний не имеют дискретных ограничений. В этом случае этот тип данных непрерывно изменяется от ячейки к ячейке, чтобы сформировать поверхность.
ПОДРОБНЕЕ: Билинейная интерполяция: изменение размера ячейки изображения с 4 ближайшими соседями
3.Кубическая свертка интерполяции
Интерполяция кубической сверткой похожа на билинейную интерполяцию в том, что она берет среднее значение окружающих ячеек. Вместо использования четырех ближайших ячеек выходное значение основывается на усреднении 16 ближайших ячеек. В результате время обработки для этого метода имеет тенденцию к увеличению.
Этот метод обычно используется для сплошных поверхностей, где присутствует много шума. Поскольку для этого требуется больше соседних ячеек по сравнению с билинейной передискретизацией, он хорошо подходит для сглаживания данных из входной растровой сетки.
Когда следует использовать интерполяцию кубической сверткой?
Кубическая свертка идеально подходит для зашумленных растров, таких как сглаживание радиолокационного изображения или модели поверхности.
Обычно мы используем кубическую свертку гораздо реже, чем билинейную интерполяцию. В частности, он хорош для снижения шума. Например, радиолокационное изображение с синтезированной апертурой может выиграть от метода интерполяции кубической свертки, поскольку он снижает шум, который обычно наблюдается в радаре.
4.Передискретизация большинства
В то время как повторная выборка ближайшего соседа берет центр ячейки из входных растровых данных, алгоритм большинства использует наиболее распространенных значений в окне фильтра.
Подобно алгоритму ближайшего соседа, этот метод обычно используется для дискретных данных, таких как классификация земного покрова и другие типы растровых сеток с четкими границами.
Когда следует использовать мажоритарную передискретизацию?
Мы часто используем фильтр большинства для земного покрова, поэтому самый популярный класс остается в выходном растре.
Например, если окно фильтра находит 3 ячейки сельскохозяйственных угодий и 2 ячейки дорог, набор выходных данных будет классифицирован как сельское хозяйство. Это связано с тем, что класс земельного покрова сельскохозяйственного назначения является наиболее популярной ячейкой в окне фильтра. По сравнению с передискретизацией ближайшего соседа результирующий набор данных часто будет более гладким.
Передискретизация растра: главный вывод
Обработка изображений стала более важной для создания изображений с различным разрешением и преобразованием систем координат.Вот почему мы используем методы передискретизации изображения, такие как ближайший сосед, билинейная интерполяция, кубическая свертка и мажоритарная интерполяция.
В ГИС повторная выборка ближайший сосед не изменяет ни одно из значений выходных ячеек из входного набора растровых данных. Это делает ближайшего соседа подходящим для дискретных данных, таких как карты классификации земного покрова. В то время как передискретизация ближайшего соседа брала центр ячейки из входного набора растровых данных, передискретизация большинства основана на наиболее общих значениях, найденных в окне фильтра.
Метод билинейной интерполяции лучше всего подходит для непрерывных данных. Это связано с тем, что выходные ячейки вычисляются на основе относительного положения четырех ближайших значений из входной сетки.
Когда у вас есть еще больше шума во входной растровой сетке, это когда кубическая свертка может быть более выгодным. Он сглаживает выходную сетку, поскольку берет 16 ближайших ячеек из набора входных данных.
Как изменить размер изображения в Photoshop (и когда вместо этого следует изменить размер изображения)
Изменение размера изображения звучит как одна из самых простых вещей, которые вы можете сделать в Photoshop, но на самом деле есть несколько распространенных ошибок, которых следует избегать.В сегодняшнюю цифровую эпоху вы, вероятно, захотите изменить размер изображения, чтобы оно хорошо помещалось на экране компьютера, однако, если вы профессиональный дизайнер или фотограф, это становится немного сложнее, когда вам нужно учитывать размер и разрешение печати. . В сегодняшнем руководстве я расскажу об основах изменения размера изображения в Adobe Photoshop и объясню, когда вам следует (или не следует) выбирать опцию Resample .
Неограниченное количество загрузок более 2000000 кистей, шрифтов, графики и шаблонов дизайна Объявление
Изменение размера и повторная выборка — два термина, которые сбивают с толку, потому что мы склонны использовать их неправильно.Мы часто говорим об изменении размера изображения, тогда как на самом деле мы делаем его повторную выборку! В Photoshop выберите «Изображение»> «Размер изображения» или нажмите сочетание клавиш CMD (или CTRL в Windows) + ALT + I.
По умолчанию опция Resample в Photoshop отмечена, что означает, что размеры изображения будут изменяться путем добавления или вычитания пикселей из ширины и высоты. Это называется передискретизацией, и обычно это то, что мы делаем при изменении размера цифрового изображения.
Если опция Resample не отмечена, вы изменяете размер изображения. Photoshop теперь перераспределит существующие пиксели, чтобы изменить физический размер или разрешение изображения. Обычно это предназначено для графических дизайнеров и фотографов, занимающихся печатью.
Фотографии с фотоаппаратов в наши дни довольно большие, они содержат миллионы пикселей, что делает как размеры, так и размер файла очень большими. Уменьшение изображения называется Даунсэмплинг .
В окне «Размер изображения» в Photoshop отображается текущий размер изображения. Измените единицы измерения на Пиксели, если они еще не установлены. Пиксели — это стандартная единица измерения для цифровых экранов.
Введите желаемый размер в пикселях в поле «Ширина» или «Высота». Значок цепочки «Ограничить соотношение сторон» по умолчанию настроен на автоматический расчет другого измерения, чтобы изображение не сжималось и не растягивалось. Photoshop предоставляет некоторую информацию в верхней части окна, показывая новый размер файла по сравнению с исходным размером изображения.
Изображения состоят из пикселей. Количество пикселей по ширине и высоте изображения определяет его размер. Уменьшить изображение легко, потому что любые лишние пиксели можно выбросить, но если вы хотите увеличить изображение, Photoshop должен создать несколько новых пикселей, чтобы создать больший размер. Это называется Интерполяция . Общее практическое правило — никогда не делать изображение больше, чем его текущий размер, потому что это приведет к ухудшению качества с нечетким или пиксельным внешним видом.Однако технология, лежащая в основе Photoshop, может умно повышать разрешение изображения с наилучшими возможными результатами.
По умолчанию Photoshop сам выберет наиболее подходящий метод интерполяции с параметром «Автоматически», но вы можете более точно контролировать результат, выбрав один из нескольких вариантов. Каждый из них разработан специально для увеличения или уменьшения. Повышающая дискретизация изображения никогда не будет идеальной, но вы можете минимизировать деградацию изображения, сглаживая или сохраняя детали, в зависимости от того, что лучше всего подходит для вашего конкретного изображения.
Традиционно 72ppi — это стандартное разрешение для экрана, а 300ppi — стандартное для печати. PPI (пикселей на дюйм) относится к цифровому файлу, который переводится в DPI (точек на дюйм), когда изображение воспроизводится в виде отпечатка. Эти термины часто используются как синонимы. Высококачественная стандартная фотография 300 пикселей на дюйм идеально подходит для печати, поскольку в ней сочетаются большие размеры и высокое разрешение. Напротив, изображение 72ppi может выглядеть огромным на экране, но максимальный размер, который он может быть напечатан при 300ppi, будет довольно мал, потому что эти 72 пикселя на каждый дюйм скоро закончатся, когда вам нужно заполнить каждый дюйм 300 пикселями … в результате в меньшем размере печати.
Мы знаем, что следует избегать повышения частоты дискретизации, чтобы предотвратить ухудшение качества изображения, но вы можете увеличить разрешение изображения, если ОТКЛЮЧИТЕ параметр Resample . Если вы этого не сделаете, изображение будет иметь 300 пикселей на дюйм, но тысячи новых пикселей будут интерполированы Photoshop, что приведет к ужасному качеству. Чтобы правильно изменить разрешение, изображение должно быть изменено (не пересчитано).
Снимите отметку с опции Resample , которая не позволяет вам изменять размер изображения в пикселях.Затем вы можете превратить свое изображение 72ppi в изображение 300ppi, но заметили, как уменьшился физический размер в дюймах? Изменение размера работает только с существующими пикселями, без интерполяции новых. У вас будет четкое, высококачественное изображение 300 пикселей на дюйм без потери качества, но общий размер печати невелик, потому что на каждый дюйм добавляется 300 пикселей, а не только 72, поэтому вы не можете заполнить столько дюймов!
Вам не нужно физически изменять разрешение всех ваших изображений при создании дизайна.Если вы создаете холст с желаемыми размерами и разрешением, всякий раз, когда вы вставляете изображение в холст, оно будет автоматически масштабироваться относительно разрешения документа. Не забудьте также масштабировать слои больше, чем их исходный размер.