Симпатичные девушки шаблон ТПУ и ПК Вернуться чехол для iPhone 7
Поделиться в:
Рекомендуемые для вас
Описания iPhone 7|iPhone 7 Case
Мягкая рамка Tpu и Pc Back Plate Shine рельефный процесс, презентация моды Pattern Enclosed Buttons, Anti-Dust and Anti-Dirt Защитите заднюю сторону телефона от царапин
Спецификация
Custom | |
|---|---|
Общий | Особенности: задная накладка Материал: TPU,PC Стиль: Сексуальные Леди,Красивая девушка |
Размер и вес | Вес продукта: 0,0300 кг Вес упаковки: 0,0500 кг Размер упаковки (Д x Ш x В): 20,00 х 20,00 х 5,00 см / 7,87 х 7,87 х 1,97 дюйма |
Комплектация | Комплектация: 1 x TPU и чехол для ПК |
Предлагаемые продукты
Отзывы клиентов
Получи G баллы! Будь первым, кто напишет обзор!
Вопросы клиентов
- Все
- Информация о товаре
- Состояние запасов
- Оплата
- О доставке
- Другие
Будьте первым, кто задаст вопрос. Хотите G баллы? Просто напишите отзыв!
Хотите G баллы? Просто напишите отзыв!
Хотите купить оптом iPhone 7|iPhone 7 Case ? Пожалуйста, отправьте ваш оптовый запрос iPhone 7|iPhone 7 Case ниже. Обратите внимание, что мы обычно не предоставляем бесплатную доставку при оптовых заказах iPhone 7|iPhone 7 Case, но оптовая цена будет большой сделкой.
Ваши недавно просмотренные товары
Сотрудничество с ВУЗами | Назаровский энергостроительный техникум
Сотрудничество с ВУЗами
СИБИРСКИЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ
Институт горного дела, геологии и геотехнологий – Площадка №3
Адрес: 660025, г. Красноярск, пр. Красноярский рабочий, 95.Телефон/факс: 8(391)213-28-51.
www: https://tpu.ru/
03С. Группа горных специальностей (по сокращенным программам):
130403.65 – Открытые горные работы130404.

140604.65 – Электропривод промышленных установок и технологических комплексов
150402.65 – Горные машины и оборудование
150404.65 – Металлургические машины и оборудование
Политехнический институт – Площадка №2
Адрес: 660074, г. Красноярск, ул. Киренского, 26Телефон/факс: 8(391)291-22-66
15С. Группа специальностей теплоэнергетики:
140101.65 – Тепловые электрические станции140104.65 – Промышленная теплоэнергетика
140200.62 – Электроэнергетика
190205.65 – Подъемно-транспортные, строительные, дорожные машины и оборудование
190601.65 – Автомобили и автомобильное хозяйство
190602.65 – Эксплуатация перегрузочного оборудования портов
21С. Группа специальностей: технологии транспортных процессов
Группа специальностей: технологии транспортных процессов
190702.65 – Организация и безопасность движения
Направление:
190100.62 – Наземные транспортные системы
Направление:
190500.62 – Эксплуатация транспортных средств
ТОМСКИЙ ПОЛИТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Энергетический институт ( ЭНИН)
Адрес: г. Томск ул. Усова, 7, корпус 8, офис 211.
Телефон:(3822) 56-37-87.
Очная форма обучения:
140100 – Теплоэнергетика и теплотехника
- Тепломассообменные процессы и установки
- Теплофизика в теплоэнергетике
- Технология воды и топлива в энергетике
- Технология производства электрической и тепловой энергии
140400 – Электроэнергетика и электротехника
- Возобновляемые источники энергии
- Высоковольтная техника электроэнергетических систем
- Материаловедение в электротехнике и радиоэлектронике
- Оптимизация развивающихся систем электроснабжения
- Технология проектирования и производств электромеханических преобразователей энергии
- Управление режимами электроэнергетических систем
- Электроприводы и системы управления электроприводов
- Электроэнергетические системы, сети, электропередачи, их режимы, устойчивость и надёжность
- Энергосберегающие режимы электрических источников питания, комплексов и систем
- Энергосбережение и энергоэффективность
КРАСНОЯРСКИЙ ИНСТИТУТ ЭКОНОМИКИ САНКТ-ПЕТЕРБУРГСКОЙ АКАДЕМИИ УПРАВЛЕНИЯ И ЭКОНОМИКИ
Адрес: 660100, Россия, Красноярский край, Красноярск, улица Академика Киренского, д. 70/а
70/а
Время работы: пн-пт 9:00-17:30
Телефоны: +7 (391) 291-20-72; +7 (391) 291-20-71; +7 (391)291-22-70
Формы обучения:
080105 — Финансы и кредит
СИБИРСКИЙ УНИВЕРСИТЕТ ПОТРЕБИТЕЛЬСКОЙ КООПЕРАЦИИ
Адрес: 630087, Новосибирск, 87, пр. К. Маркса, 26.
Телефон/факс: (383) 346-58-52;
Проезд: до станции метро «Студенческая» или остановки общественного транспорта «Горская».
Формы обучения:
080105 — Финансы и кредит
КРАСНОЯРСКИЙ ФИЛИАЛ МОСКОВСКОГО ГОСУДАРСТВЕННОГО УНИВЕРСИТЕТА ЭКОНОМИКИ, СТАТИСТИКИ И ИНФОРМАТИКИ
Адрес: 660012, г. Красноярск, ул. Семафорная, 123
Телефон: (391) 233-96-22; тел./факс: (391) 233-96-22
Проезд автобусами: № 23, 31, 36, 94, 95, 98 до остановки «ИНСТИТУТ».

Формы обучения:
080105 — Финансы и кредит
ИНСТИТУТ ЭКОНОМИКИ И УПРАВЛЕНИЯ АПК
www: http://www.kgau.ru/new/institut/ieu/
Презентация ИУиЭ АПУ
15 « Декабрь « 2020 « Региональный центр развития образования
ОГБУ «Региональный центр развития образования» информирует о проведении второго занятия в рамках реализации бесплатной образовательной программы «Новаторы» для обучающихся 9-11 классов общеобразовательных организаций Томской области.
Организаторы программы: Школа инженерного предпринимательства Национального исследовательского Томского политехнического университета; Бизнес-школа для подростков «BROOX» при информационной и организационной поддержке ОГБУ «Региональный центр развития образования».
Второе занятие в рамках программы состоится 19 декабря 2020 года (суббота) и пройдёт в формате семинара-тренинга по теме «Профессии будущего». Для участия приглашаются не более 100 школьников 9-11 классов из общеобразовательных организаций Томской области (в том числе, ориентированных на поступление в НИ ТПУ).
Ссылка для подключения: https://zoom.us/j/96959377987?pwd=SkZhUVZOckdFNjlXV0JoZ1QrUndxdz09
Идентификатор конференции: 969 5937 7987. Код доступа: 070284.
Информационное письмо ОГБУ «РЦРО» от 15.12.2020 г. № 1259
Информация на сайте Департамента общего образования Томской области>>>
ОГБУ «Региональный центр развития образования» — региональный оператор Ведомственной целевой программы «Развитие системы выявления и поддержки детей, проявивших выдающиеся способности» совместно с межмуниципальным центром по работе с одаренными детьми на базе МАОУ «СОШ № 7» г. Колпашево информируют об итогах проведения открытого межмуниципального образовательного мероприятия — викторины по географии «Путешествие к южному полюсу», посвященной 200-летию открытия Антарктиды».
В дистанционной форме 7 декабря 2020 года в викторине приняли участие 128 обучающихся 7-8 классов 28 образовательных организаций 17 муниципальных образований Томской области.
По итогам викторины присуждено 47 призовых мест. Организационный комитет благодарит всех участников, поздравляет победителей и призёров!
Информационное письмо ОГБУ «РЦРО» от 15.12.2020 г. № 1260 | Подробнее о викторине>>>
В ноябре 2020 года состоялся третий цикл волонтёрского проекта Образовательного центра «Сириус» «Уроки настоящего» на тему «Уроки настоящей нефтехимии». 18 научно-технологических студий Томской области в ходе цикла узнали о последних мировых трендах в части экономики замкнутого цикла, базирующейся на переработке отходов, о текущей мусорной реформе в нашей стране, интересных кейсах применения переработанных отходов пластика в России и мире. В качестве задачи эксперты цикла предложили студийцам продумать стратегию популяризации раздельного сбора отходов.
Ребята из Томской области активно работали над задачей цикла. Участники научно-технологической студии МБОУ «Зырянская СОШ» провели открытый урок на тему «Раздельный сбор мусора», на котором показали школьникам всю важность этой сферы развития в современном обществе.
Школьники из научно-технологической студии МОУ «СОШ № 4» г.о. Стрежевой считают, что для популяризации раздельного сбора отходов необходимо донести информацию до как можно большего количества людей и это можно сделать при помощи различных мероприятий (телепрограмм, тематических классных часов), посвящённых данной проблематике. Также это поможет донести важность этой проблемы до крупных компаний.
Ребята из научно-технологической студии МАОУ Гуманитарного лицея г. Томска подготовили видеоролик для популяризации экологии, показали способы и процесс подготовки переработки отходов.
Третий цикл для студийцев Томской области оказался успешным и продуктивным. Сопровождение всех студий Томской области осуществляет ОГБУ «Региональный центр развития образования».
«Стратегия популяризации раздельного сбора отходов» от студии МБОУ «Зырянская СОШ»>>>
«Стратегия популяризации раздельного сбора отходов» от студии МАОУ Гуманитарного лицея г. Томска>>>
Томска>>>
Подробнее »
ОГБУ «Региональный центр развития образования» (Томский региональный центр выявления и поддержки одаренных детей) информирует о проведении конкурсного отбора на программу «Взаимодействие основного и дополнительного математического образования как основа эффективной работы с одаренными школьниками», которая будет реализовываться с 22 по 28 января 2021 года на базе Образовательного центра «Сириус» (г. Сочи) в объеме 56 часов (48 часов очно, 8 часов дистанционно). Заявки принимаются до 22 декабря 2020 года на странице программы.
Информационное письмо ОГБУ «РЦРО» от 14.12.2020 г. № 1250
Информация на сайте Департамента общего образования Томской области>>>
ОГБУ «Региональный центр развития образования» (Томский региональный центр выявления и поддержки одаренных детей) в рамках подготовки к региональному этапу Всероссийского конкурса научно-технологических проектов «Большие вызовы» в 2020/2021 учебном году информирует о втором занятии дистанционного курса «Сезон проектов_2021».
Занятие состоится 22 декабря 2020 года в онлайн-формате на коммуникационной платформе Zoom.
— С 13:40 до 15:40 – подключаются команды из МАОУ Школы «Эврика-развитие» г. Томск, Дворца творчества детей и молодежи города Томска.
— С 16:00 до 18:00 – подключаются команды из МАОУ СОШ № 32 г. Томска, МАОУ «Итатская СОШ» Томского района, МАОУ гимназии 26 г. Томска, ОГБОУ «Томский физико-технический лицей», МАОУ-СОШ № 4 г. Асино Томской области, МБОУ ДО «Каргасокский ДДТ», МОУ «СОШ № 4 г.о. Стрежевой», МАОУ СОШ «Интеграция» Томского района.
Информационное письмо ОГБУ «РЦРО» от 10.12.2020 г. № 1235
Шаблон презентации (исследовательские работы)
Шаблон презентации (проектные работы)
Информация на сайте Департамента общего образования Томской области>>>
Мечта шаблон оболочки случаях мягкий силиконовый TPU крышку телефона
Мечта шаблон оболочки случаях мягкий силиконовый TPU крышку телефонаБудущие:
- 100% совершенно новые и высокое качество
- Материал: Мягкая подошва из термопластичного полиуретана + жесткий ПК
- Полный доступ ко всем кнопкам, портов и функции.
- Защитите свой мобильный телефон от царапин и ударов
- Удобный и легкий дизайн защищает без добавления.
- Shell и чехол черного цвета как ребристую войлочную ленту с резиновой ощущение для проскальзывания
- Поставляется с встроенным встроенная подставка подходит для руки с помощью телефона.
- Установите для Apple iPhone 5S SE 5 7 6 Plus.
Торговых точках
Модель: для iPhone 8/7/6 / 6s/ 5s / SE / 5
Для iPhone 8 Plus / 7 / 6 Plus / 6s Plus случаев
Материал: Высокое качество мягкая силиконовая
Функция: Градиент Ультратонкие Прозрачная задняя крышка Fundas
Оптовая Скидка большой поддержки! ! !
- Примечание: Эти Два Стили: TPU и ПК+TPU дела
Обратная связь
Мы придерживаемся высоких стандартов качества и стремиться к 100% удовлетворенности клиентов! Очень важно обратной связи мы просим вас связаться с нами непосредственно перед вами на нейтраль или отрицательный отзыв, так что мы можем удовлетворительного решения проблемы. Пожалуйста свяжитесь с нами во-первых, если имеются какие-либо вопросы или проблемы.
Обслуживание клиентов
- Любой запрос будет иметь рад ответ в течение 24 часов.
- Все цены, минимальная являются предметом переговоров.
- Все продукты должны быть строго осмотр перед отгрузкой.
- Прилагать усилия для подачи электропитания на лучшее качество продукции, но с хорошей цене.
- Поддержка обратная связь от клиента при послепродажном обслуживании проблеме качества расследования и осуществлять правильное решение.
- Сотрудников категории специалистов и профессиональный дизайн.
Контактная информация:
Фоны для презентации в русском народном стиле
Сайт Национального исследовательского Томского политехнического университетаШаблоны для презентаций. Подробности по тел. (38-22) 56-35-17, 70-56-85 или по адресу: г. Томск, пр. Ленина, 30, Главный корпус ТПУ
При использовании логотипа, шрифтов, фирменного блока и других элементов убедительно просим вас ознакомиться с правилами использования элементов фирменного стиля в соответствующем разделе.
Если у вас возникли вопросы о допустимости способа использования логотипа ТПУ на сайте подразделения или в полиграфической/ сувенирной продукции или вы не нашли нужного формата для скачивания, обратитесь за консультацией к специалистам Управления коммуникационной политики.
КОНТАКТЫ
Полиграфическая продукция
Евгений Владимирович Коробов
Начальник отдела отдела связей с общественностью (PR)
(38-22) 70-56-85, Вн. 6825.
Интернет-проекты
Иван Анатольевич Середов
Начальник отдела интернет-коммуникаций
пр. Ленина, 30, офис 318.
(38-22) 70-18-38, Вн. 5067.
Шаблоны для презентаций
Национальный исследовательский Томский политехнический университет 634050, г.
Подробности по тел. (38-22) 56-35-17, 70-56-85 или по адресу: г. Томск, пр. Ленина, 30, Главный корпус ТПУ
При использовании логотипа, шрифтов, фирменного блока и других элементов убедительно просим вас ознакомиться с правилами использования элементов фирменного стиля в соответствующем разделе.
Если у вас возникли вопросы о допустимости способа использования логотипа ТПУ на сайте подразделения или в полиграфической/ сувенирной продукции или вы не нашли нужного формата для скачивания, обратитесь за консультацией к специалистам Управления коммуникационной политики.
КОНТАКТЫ
Полиграфическая продукция
Евгений Владимирович Коробов
Начальник отдела отдела связей с общественностью (PR)
(38-22) 70-56-85, Вн. 6825.
Интернет-проекты
Иван Анатольевич Середов
Начальник отдела интернет-коммуникаций
пр. Ленина, 30, офис 318.
(38-22) 70-18-38, Вн. 5067.
Шаблоны для презентаций
Национальный исследовательский Томский политехнический университет 634050, г. Томск, проспект Ленина, дом 30
Нам важно ваше мнение. Чтобы оставить комментарий — нажмите Ctrl+Enter.
TPU © 2002-2016 При полном или частичном использовании текстовых и графических материалов с сайта ссылка на сайт ТПУ обязательна.
Томск, проспект Ленина, дом 30
Нам важно ваше мнение. Чтобы оставить комментарий — нажмите Ctrl+Enter.
TPU © 2002-2016 При полном или частичном использовании текстовых и графических материалов с сайта ссылка на сайт ТПУ обязательна.
Презентация молока и молочных продуктов
Презентация проекта по технологии
Туберкулёз профилактика презентация
Презентация на тему будущее школы
Скульптура древней греции презентация
Презентация электромагнитное волны
Темы для презентации на тему профессии
Приглашаем мальчиков и девочек в детскую школу моделей.
Родители, не упустите шанс на блестящее будущее Ваших детей!
В программу обучения Детской Школы Моделей входят:
По всем вопросам обращаться по телефонам: (383) 287-28-53, (383) 299-34-29
Презентация тпу шаблон — acaedaita.keywordcourse.com
Презентация тпу шаблон
Лауреатом конкурса педагогического мастерства «Учитель года — 2019» стала Смирнова Елена Александровна, учитель начальных классов МБОУ «СОШ № 196». Шаблон 1 для презентации на русском языке (4×3) Шаблон 2 для презентации на русском языке (4×3). П Р О Г Р А М М А развития ФГБОУ ВПО «Красноярский государственный аграрный университет» на 2013-2020 гг. направленная на оптимизацию основной деятельности. Национальный исследовательский Томский политехнический университет Шаблон TOLMI для Microsoft PowerPoint. Шаблон TOLMI: Презентации профессора Кренинга. Посмотреть и скачать бесплатно презентацию по теме «Шаблон презентации для студента ТПУ». pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов.
Шаблоны оформления материалов в сборник трудов индексируемый Ленина, 30, Главный корпус ТПУ, офис 128. Прием документов: ул. Усова. Шаблоны для презентаций; Шаблоны для афиш мероприятий ТПУ; Шаблоны для афиш Национальный исследовательский Томский политехнический университет 634050. Шаблон для презентации Школа школа! — Шаблоны презентаций Шаблон для презентации Школа школа. 28 стильных шаблонов презентаций — Ресурсы.
Шаблон 1 для презентации на русском языке (4×3) Шаблон 2 для презентации на русском языке (4×3). П Р О Г Р А М М А развития ФГБОУ ВПО «Красноярский государственный аграрный университет» на 2013-2020 гг. направленная на оптимизацию основной деятельности. Национальный исследовательский Томский политехнический университет Шаблон TOLMI для Microsoft PowerPoint. Шаблон TOLMI: Презентации профессора Кренинга. Посмотреть и скачать бесплатно презентацию по теме «Шаблон презентации для студента ТПУ». pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов.
Шаблоны оформления материалов в сборник трудов индексируемый Ленина, 30, Главный корпус ТПУ, офис 128. Прием документов: ул. Усова. Шаблоны для презентаций; Шаблоны для афиш мероприятий ТПУ; Шаблоны для афиш Национальный исследовательский Томский политехнический университет 634050. Шаблон для презентации Школа школа! — Шаблоны презентаций Шаблон для презентации Школа школа. 28 стильных шаблонов презентаций — Ресурсы. Лучшие карьерные советы на icanchoose. Бесплатные шаблоны, темы и фоны для презентаций powerpoint. В разделе находятся шаблоны и фоны для презентаций PowerPoint на разные темы. Презентация. Создавайте профессионально оформленные презентации с помощью этого шаблона. Бесплатные шаблоны для презентаций PowerPoint. Любые темы. Все шаблоны имеют оригинальное оформление. Доступны для скачивания без регистрации. Темы для презентаций PowerPoint — качайте бесплатно. Качественные шаблоны и фоны для презентаций.
В ней собрано 27 уникальных шаблонов презентаций PowerPoint, которые можно скачать совершенно бесплатно. Бесплатные шаблоны, темы и фоны для презентаций powerpoint на тему спорта. Качественные разработки для учителей по курсу Шаблоны презентаций. Авторские шаблоны созданы в рамках мастер-класса «Технологический приём «Паззлы» на сайте Данная презентация поможет учителю в создании дидактической игры. Качественные разработки уроков, конспекты и презентации по теме Универсальные шаблоны. Бесплатные шаблоны, фоны и темы для презентаций PowerPoint.
Лучшие карьерные советы на icanchoose. Бесплатные шаблоны, темы и фоны для презентаций powerpoint. В разделе находятся шаблоны и фоны для презентаций PowerPoint на разные темы. Презентация. Создавайте профессионально оформленные презентации с помощью этого шаблона. Бесплатные шаблоны для презентаций PowerPoint. Любые темы. Все шаблоны имеют оригинальное оформление. Доступны для скачивания без регистрации. Темы для презентаций PowerPoint — качайте бесплатно. Качественные шаблоны и фоны для презентаций.
В ней собрано 27 уникальных шаблонов презентаций PowerPoint, которые можно скачать совершенно бесплатно. Бесплатные шаблоны, темы и фоны для презентаций powerpoint на тему спорта. Качественные разработки для учителей по курсу Шаблоны презентаций. Авторские шаблоны созданы в рамках мастер-класса «Технологический приём «Паззлы» на сайте Данная презентация поможет учителю в создании дидактической игры. Качественные разработки уроков, конспекты и презентации по теме Универсальные шаблоны. Бесплатные шаблоны, фоны и темы для презентаций PowerPoint. У нас вы можете скачать бесплатно шаблоны Microsoft PowerPoint (2007, 2010, 2013, 2016) для школы. Презентации всегда интерактивны. Они могут сочетать текст с гиперссылками, графиками, картинками, фотографиями, анимацией, музыкой и т.д. Шаблоны для презентаций. Слайд 8. Вы можете использовать данное оформление для создания своих презентаций , но в своей презентации вы должны указать источник шаблона : Ушакова Виктория. Вы можете изучить и скачать доклад-презентацию на тему шаблон #2. Презентация на заданную тему содержит 3 слайдов.
Тематические презентации. Новые шаблоны для пезентаций. Хотите поразить всех учеников в классе, включая учителя? Скачивайте шаблоны из данного раздела. Бесплатное собрание шаблонов оформления и тем для презентаций PowerPoint. На нашем сайте вы можете бесплатно скачать презентации на тему бизнес, время, искусство, еда. Шаблон для презентации График — Шаблоны презентаций Шаблон для презентации График. Шаблон презентации № 4 За подготовку данного шаблона благодарим студента вуза Алексея Минина.
У нас вы можете скачать бесплатно шаблоны Microsoft PowerPoint (2007, 2010, 2013, 2016) для школы. Презентации всегда интерактивны. Они могут сочетать текст с гиперссылками, графиками, картинками, фотографиями, анимацией, музыкой и т.д. Шаблоны для презентаций. Слайд 8. Вы можете использовать данное оформление для создания своих презентаций , но в своей презентации вы должны указать источник шаблона : Ушакова Виктория. Вы можете изучить и скачать доклад-презентацию на тему шаблон #2. Презентация на заданную тему содержит 3 слайдов.
Тематические презентации. Новые шаблоны для пезентаций. Хотите поразить всех учеников в классе, включая учителя? Скачивайте шаблоны из данного раздела. Бесплатное собрание шаблонов оформления и тем для презентаций PowerPoint. На нашем сайте вы можете бесплатно скачать презентации на тему бизнес, время, искусство, еда. Шаблон для презентации График — Шаблоны презентаций Шаблон для презентации График. Шаблон презентации № 4 За подготовку данного шаблона благодарим студента вуза Алексея Минина. powerpointstore.com — это собрание лучших авторских шаблонов, тем и фонов презентаций, которые вы можете скачать абсолютно бесплатно. Презентация: Шаблон оформления «Сине-зеленая пещера» PowerPoint Шаблон оформления «Водоворот» PowerPoint Тысячи шаблонов для быстрого создания.
Создавайте презентации вместе с друзьями и коллегами. Редактируйте файлы даже без подключения к Интернету. Работайте с презентациями MS PowerPoint. И все это. Посмотреть и скачать бесплатно презентацию по теме «Шаблон презентации для студентов МИЭТ». pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Приближается дата презентации? Работа над всеми элементами хорошей презентации может занять много времени: необходимо написать убедительный текст. Шаблон 1 для презентации на русском языке (4×3) Шаблон 2 для презентации на русском языке (4×3).
Национальный исследовательский Томский политехнический университет Шаблон TOLMI для Microsoft PowerPoint. Шаблон TOLMI: Презентации профессора Кренинга.
powerpointstore.com — это собрание лучших авторских шаблонов, тем и фонов презентаций, которые вы можете скачать абсолютно бесплатно. Презентация: Шаблон оформления «Сине-зеленая пещера» PowerPoint Шаблон оформления «Водоворот» PowerPoint Тысячи шаблонов для быстрого создания.
Создавайте презентации вместе с друзьями и коллегами. Редактируйте файлы даже без подключения к Интернету. Работайте с презентациями MS PowerPoint. И все это. Посмотреть и скачать бесплатно презентацию по теме «Шаблон презентации для студентов МИЭТ». pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Приближается дата презентации? Работа над всеми элементами хорошей презентации может занять много времени: необходимо написать убедительный текст. Шаблон 1 для презентации на русском языке (4×3) Шаблон 2 для презентации на русском языке (4×3).
Национальный исследовательский Томский политехнический университет Шаблон TOLMI для Microsoft PowerPoint. Шаблон TOLMI: Презентации профессора Кренинга. Посмотреть и скачать бесплатно презентацию по теме Шаблон презентации для студента ТПУ pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Шаблоны оформления материалов в сборник трудов индексируемый Ленина, 30, Главный корпус ТПУ, офис 128. Прием документов: ул. Усова.
Шаблоны для презентаций; Шаблоны для афиш мероприятий ТПУ; Шаблоны для афиш Национальный исследовательский Томский политехнический университет 634050. Шаблон для презентации Школа школа! — Шаблоны презентаций Шаблон для презентации Школа школа. 28 стильных шаблонов презентаций — Ресурсы. Лучшие карьерные советы на icanchoose. Бесплатные шаблоны, темы и фоны для презентаций powerpoint. В разделе находятся шаблоны и фоны для презентаций PowerPoint на разные темы.
Презентация. Создавайте профессионально оформленные презентации с помощью этого шаблона. Бесплатные шаблоны для презентаций PowerPoint. Любые темы. Все шаблоны имеют оригинальное оформление. Доступны для скачивания без регистрации.
Посмотреть и скачать бесплатно презентацию по теме Шаблон презентации для студента ТПУ pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Шаблоны оформления материалов в сборник трудов индексируемый Ленина, 30, Главный корпус ТПУ, офис 128. Прием документов: ул. Усова.
Шаблоны для презентаций; Шаблоны для афиш мероприятий ТПУ; Шаблоны для афиш Национальный исследовательский Томский политехнический университет 634050. Шаблон для презентации Школа школа! — Шаблоны презентаций Шаблон для презентации Школа школа. 28 стильных шаблонов презентаций — Ресурсы. Лучшие карьерные советы на icanchoose. Бесплатные шаблоны, темы и фоны для презентаций powerpoint. В разделе находятся шаблоны и фоны для презентаций PowerPoint на разные темы.
Презентация. Создавайте профессионально оформленные презентации с помощью этого шаблона. Бесплатные шаблоны для презентаций PowerPoint. Любые темы. Все шаблоны имеют оригинальное оформление. Доступны для скачивания без регистрации. Темы для презентаций PowerPoint — качайте бесплатно. Качественные шаблоны и фоны для презентаций.
В ней собрано 27 уникальных шаблонов презентаций PowerPoint, которые можно скачать совершенно бесплатно. Бесплатные шаблоны, темы и фоны для презентаций powerpoint на тему спорта. Качественные разработки для учителей по курсу Шаблоны презентаций. Авторские шаблоны созданы в рамках мастер-класса Технологический приём Паззлы на сайте Данная презентация поможет учителю в создании дидактической игры. Качественные разработки уроков, конспекты и презентации по теме Универсальные шаблоны. Бесплатные шаблоны, фоны и темы для презентаций PowerPoint. У нас вы можете скачать бесплатно шаблоны Microsoft PowerPoint (2007, 2010, 2013, 2016) для школы. Презентации всегда интерактивны. Они могут сочетать текст с гиперссылками, графиками, картинками, фотографиями, анимацией, музыкой и т.д. Шаблоны для презентаций. Слайд 8. Вы можете использовать данное оформление для создания своих презентаций , но в своей презентации вы должны указать источник шаблона : Ушакова Виктория.
Темы для презентаций PowerPoint — качайте бесплатно. Качественные шаблоны и фоны для презентаций.
В ней собрано 27 уникальных шаблонов презентаций PowerPoint, которые можно скачать совершенно бесплатно. Бесплатные шаблоны, темы и фоны для презентаций powerpoint на тему спорта. Качественные разработки для учителей по курсу Шаблоны презентаций. Авторские шаблоны созданы в рамках мастер-класса Технологический приём Паззлы на сайте Данная презентация поможет учителю в создании дидактической игры. Качественные разработки уроков, конспекты и презентации по теме Универсальные шаблоны. Бесплатные шаблоны, фоны и темы для презентаций PowerPoint. У нас вы можете скачать бесплатно шаблоны Microsoft PowerPoint (2007, 2010, 2013, 2016) для школы. Презентации всегда интерактивны. Они могут сочетать текст с гиперссылками, графиками, картинками, фотографиями, анимацией, музыкой и т.д. Шаблоны для презентаций. Слайд 8. Вы можете использовать данное оформление для создания своих презентаций , но в своей презентации вы должны указать источник шаблона : Ушакова Виктория. Вы можете изучить и скачать доклад-презентацию на тему шаблон #2. Презентация на заданную тему содержит 3 слайдов.
Тематические презентации. Новые шаблоны для пезентаций. Хотите поразить всех учеников в классе, включая учителя? Скачивайте шаблоны из данного раздела. Бесплатное собрание шаблонов оформления и тем для презентаций PowerPoint. На нашем сайте вы можете бесплатно скачать презентации на тему бизнес, время, искусство, еда. Шаблон для презентации График — Шаблоны презентаций Шаблон для презентации График. Шаблон презентации № 4 За подготовку данного шаблона благодарим студента вуза Алексея Минина. powerpointstore.com — это собрание лучших авторских шаблонов, тем и фонов презентаций, которые вы можете скачать абсолютно бесплатно. Презентация: Шаблон оформления Сине-зеленая пещера PowerPoint Шаблон оформления Водоворот PowerPoint Тысячи шаблонов для быстрого создания.
Создавайте презентации вместе с друзьями и коллегами. Редактируйте файлы даже без подключения к Интернету. Работайте с презентациями MS PowerPoint.
Вы можете изучить и скачать доклад-презентацию на тему шаблон #2. Презентация на заданную тему содержит 3 слайдов.
Тематические презентации. Новые шаблоны для пезентаций. Хотите поразить всех учеников в классе, включая учителя? Скачивайте шаблоны из данного раздела. Бесплатное собрание шаблонов оформления и тем для презентаций PowerPoint. На нашем сайте вы можете бесплатно скачать презентации на тему бизнес, время, искусство, еда. Шаблон для презентации График — Шаблоны презентаций Шаблон для презентации График. Шаблон презентации № 4 За подготовку данного шаблона благодарим студента вуза Алексея Минина. powerpointstore.com — это собрание лучших авторских шаблонов, тем и фонов презентаций, которые вы можете скачать абсолютно бесплатно. Презентация: Шаблон оформления Сине-зеленая пещера PowerPoint Шаблон оформления Водоворот PowerPoint Тысячи шаблонов для быстрого создания.
Создавайте презентации вместе с друзьями и коллегами. Редактируйте файлы даже без подключения к Интернету. Работайте с презентациями MS PowerPoint. И все это. Посмотреть и скачать бесплатно презентацию по теме Шаблон презентации для студентов МИЭТ pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Приближается дата презентации? Работа над всеми элементами хорошей презентации может занять много времени: необходимо написать убедительный текст. Ознакомительные лекции провели Андреев Владимир Александрович, к.т.н. доцент кафедры. Федеральное государственное бюджетное образовательное учреждение высшего образования.
И все это. Посмотреть и скачать бесплатно презентацию по теме Шаблон презентации для студентов МИЭТ pptCloud.ru — каталог презентаций для детей, школьников (уроков) и студентов. Приближается дата презентации? Работа над всеми элементами хорошей презентации может занять много времени: необходимо написать убедительный текст. Ознакомительные лекции провели Андреев Владимир Александрович, к.т.н. доцент кафедры. Федеральное государственное бюджетное образовательное учреждение высшего образования.
Студенты Томского политехнического университета – участники специализированной программы Системного оператора, победили в региональном этапе Международного инженерного чемпионата «Case-in»
В Томске состоялся отборочный тур Международного чемпионата по решению инженерных кейсов «Case-in». В лиге «Электроэнергетика» победителем стала команда #PowerSystems, в составе четырех студентов Энергетического института Национального исследовательского Томского политехнического университета (НИ ТПУ), двое из которых – участники специализированной программы подготовки ОАО «СО ЕЭС». Победители регионального этапа будут представлять Томскую область в финале чемпионата «Case-in» в мае 2016 года в Москве.
Победители регионального этапа будут представлять Томскую область в финале чемпионата «Case-in» в мае 2016 года в Москве.
Системный оператор выступает партнером чемпионата в лиге «Электроэнергетика» и предоставляет собственные материалы для кейсов, используемых в заданиях. Специалисты компании также входят в жюри отборочного этапа конкурса. Двое из четверых победителей регионального отборочного тура – участники образовательной программы по подготовке специалистов-энергетиков фонда «Надежная смена». В рамках проекта фонда «Школа – вуз – предприятие» в НИ ТПУ организовано обучение магистрантов по специализированной программе ОАО «СО ЕЭС».
Участвующие в региональном отборе студенческие команды должны были решить непростую задачу – защитить перед авторитетными экспертами свою презентацию решения кейса, которым стал случай из реальной практики. Ребятам было предложено разработать эффективную схему электроснабжения удаленного населенного пункта – поселка Батакан, расположенного в Забайкальском крае, с учетом подключения к инженерным сетям строящейся деревообрабатывающей фабрики.
Лучшим было признано инженерное решение команды #PowerSystems, в состав которой вошли магистранты — участники совместной программы ОАО «СО ЕЭС» и НИ ТПУ Иван Волков и Семен Мельников.
Второе и третье место заняли команды «Холостое замыкание» и «Выход там», в составе которых также принимали участие магистранты НИ ТПУ, обучающиеся по специальным программам Системного оператора: Максим Никитин, Алексей Арыштаев, Ольга Стремилова, Виктор Католиков.
«»Case-in» уникален тем, что это единственный федеральный кейс-чемпионат в сфере топливно-энергетического и минерально-сырьевого комплексов. За четыре года своего существования чемпионат значительно расширил круг участников и организаторов. К его проведению подключились 20 крупнейших отраслевых компаний, профильные министерства и ведомства. Таким образом, сегодня «Case-in» дает отличную возможность студентам влиться в профессиональное сообщество, наладить контакты с будущими работодателями, а также отточить навыки самопрезентации и публичных выступлений. Участие в чемпионате – прямой путь в отраслевую среду: как показывает практика, более 80 процентов финалистов чемпионата по его окончании получают предложения о практике, стажировке или трудоустройстве в компаниях-партнерах», — отметил представитель организаторов чемпионата, директор фонда «Надежная смена» Артем Королев.
Участие в чемпионате – прямой путь в отраслевую среду: как показывает практика, более 80 процентов финалистов чемпионата по его окончании получают предложения о практике, стажировке или трудоустройстве в компаниях-партнерах», — отметил представитель организаторов чемпионата, директор фонда «Надежная смена» Артем Королев.
Как заявил директор Филиала ОАО «СО ЕЭС» Томское РДУ Дмитрий Кулешков, подобные мероприятия дают эффект в сфере профессиональной подготовки специалистов. Участники, решая задачи, актуальные для современной энергетической отрасли, находят применение полученным теоретическим знаниям и получают огромный практический опыт. Организаторы и эксперты, в свою очередь, имеют возможность уже на этапе обучения выявлять наиболее одаренных и перспективных студентов для дальнейшей работы на предприятиях энергетики.
В ближайшее время отборочные этапы чемпионата в лиге «Электроэнергетика» пройдут и в других вузах – партнерах ОАО «СО ЕЭС».
Инженерный чемпионат «Case-in» является правопреемником Всероссийского чемпионата по решению кейсов в области горного дела, проходившего в 2013 и 2014 годах, и Всероссийского чемпионата по решению топливно-энергетических кейсов, проводившегося в 2015 году. В этом году чемпионат получил статус международного. Соревнования проводятся в пяти лигах: электроэнергетика, горное дело, геологоразведка, металлургия, нефтегазовое дело. В 2016 году в них примут участие студенты 38 вузов из более чем 30 регионов России, а также из Казахстана и Монголии.
В этом году чемпионат получил статус международного. Соревнования проводятся в пяти лигах: электроэнергетика, горное дело, геологоразведка, металлургия, нефтегазовое дело. В 2016 году в них примут участие студенты 38 вузов из более чем 30 регионов России, а также из Казахстана и Монголии.
Организаторами чемпионата выступают фонд «Надежная смена», Некоммерческое партнерство «Молодежный форум лидеров горного дела» и Некоммерческое партнерство «РНК СИГРЭ». Мероприятие проводится при поддержке пяти федеральных министерств − Министерства энергетики Российской Федерации, Министерства природных ресурсов и экологии Российской Федерации, Министерства образования и науки Российской Федерации, Министерства труда и социальной защиты Российской Федерации, Министерства промышленности и торговли Российской Федерации, а также Росмолодежи и Агентства стратегических инициатив по продвижению новых проектов.
облачных тензорных процессоров (TPU) | Google Cloud
Блоки тензорной обработки (TPU) — это специально разработанные Google
специализированные интегральные схемы (ASIC), используемые для
ускорить выполнение машинного обучения. ТПУ разработаны из
с нуля благодаря богатому опыту и лидерству Google в
машинное обучение.
ТПУ разработаны из
с нуля благодаря богатому опыту и лидерству Google в
машинное обучение.
Cloud TPU позволяет запускать рабочие нагрузки машинного обучения на аппаратном ускорителе TPU от Google с помощью TensorFlow.Cloud TPU разработан для максимальной производительности и гибкости чтобы помочь исследователям, разработчикам и компаниям создавать вычисления TensorFlow кластеры, которые могут использовать ЦП, ГП и TPU. API-интерфейсы TensorFlow высокого уровня поможет вам запустить модели на оборудовании Cloud TPU.
Преимущества ТПУ
РесурсыCloud TPU ускоряют выполнение линейной алгебры вычисления, которые широко используются в приложениях машинного обучения. ТПУ минимизировать время достижения точности при обучении большой сложной нейронной сети модели.Модели, обучение которых на других аппаратных платформах раньше занимало недели может сойтись за часы на TPU.
Наличие
Cloud TPU доступны в следующих зонах:
США
| Тип ТПУ (v2) | TPU v2 ядра | Общая память TPU | Регион / Зона |
|---|---|---|---|
| версии 2-8 | 8 | 64 ГиБ | us-central1-b us-central1-c us-central1-f |
| версия 2-32 | 32 | 256 ГиБ | us-central1-a |
| версия 2-128 | 128 | 1 ТиБ | us-central1-a |
| версии 2-256 | 256 | 2 ТиБ | us-central1-a |
| версия 2-512 | 512 | 4 ТиБ | us-central1-a |
| Тип ТПУ (v3) | TPU v3 ядра | Общая память TPU | Доступные зоны |
| версии 3-8 | 8 | 128 ГиБ | us-central1-a us-central1-b us-central1-f |
Европа
| Тип ТПУ (v2) | TPU v2 ядра | Общая память TPU | Регион / Зона |
|---|---|---|---|
| версии 2-8 | 8 | 64 ГиБ | европа-запад4-а |
| версия 2-32 | 32 | 256 ГиБ | европа-запад4-а |
| версия 2-128 | 128 | 1 ТиБ | европа-запад4-а |
| версии 2-256 | 256 | 2 ТиБ | европа-запад4-а |
| версия 2-512 | 512 | 4 ТиБ | европа-запад4-а |
| Тип ТПУ (v3) | TPU v3 ядра | Общая память TPU | Доступные зоны |
| версии 3-8 | 8 | 128 ГиБ | европа-запад4-а |
| версия 3-32 | 32 | 512 ГиБ | европа-запад4-а |
| версия 3-64 | 64 | 1 ТиБ | европа-запад4-а |
| v3-128 | 128 | 2 ТиБ | европа-запад4-а |
| v3-256 | 256 | 4 ТиБ | европа-запад4-а |
| версия 3-512 | 512 | 8 ТиБ | европа-запад4-а |
| версия 3-1024 | 1024 | 16 ТиБ | европа-запад4-а |
| версия 3-2048 | 2048 | 32 ТиБ | европа-запад4-а |
Азиатско-Тихоокеанский регион
| Тип ТПУ (v2) | TPU v2 ядра | Общая память TPU | Регион / Зона |
|---|---|---|---|
| версии 2-8 | 8 | 64 ГиБ | азия-восток1-с |
Модель программирования Cloud TPU
Cloud TPU очень быстро выполняют плотные векторные и матричные вычисления. Передача данных между Cloud TPU и памятью хоста происходит медленно
по сравнению со скоростью вычислений — скорость шины PCIe на намного медленнее на чем как межсоединение Cloud TPU, так и высокая пропускная способность на кристалле
память (HBM). Это означает, что частичная компиляция модели, где выполнение
«пинг-понг» между хостом и устройством, использует устройство очень неэффективно,
поскольку большую часть времени он будет бездействовать, ожидая прибытия данных по PCIe
автобус. Чтобы облегчить эту ситуацию, модель программирования для
Cloud TPU предназначен для выполнения большей части обучения на
TPU — в идеале весь цикл обучения.
Передача данных между Cloud TPU и памятью хоста происходит медленно
по сравнению со скоростью вычислений — скорость шины PCIe на намного медленнее на чем как межсоединение Cloud TPU, так и высокая пропускная способность на кристалле
память (HBM). Это означает, что частичная компиляция модели, где выполнение
«пинг-понг» между хостом и устройством, использует устройство очень неэффективно,
поскольку большую часть времени он будет бездействовать, ожидая прибытия данных по PCIe
автобус. Чтобы облегчить эту ситуацию, модель программирования для
Cloud TPU предназначен для выполнения большей части обучения на
TPU — в идеале весь цикл обучения.
Ниже приведены некоторые характерные особенности модели программирования, реализованной Стиматор TPUE:
- Все параметры модели хранятся во встроенной памяти с высокой пропускной способностью.
- Стоимость запуска вычислений на Cloud TPU амортизируется выполнение множества шагов обучения в цикле.
- Входные обучающие данные передаются в очередь «подачи» на
Облако ТПУ.
 Программа, работающая в Cloud TPU, получает
пакеты из этих очередей на каждом этапе обучения.
Программа, работающая в Cloud TPU, получает
пакеты из этих очередей на каждом этапе обучения. - Сервер TensorFlow, работающий на хост-машине (ЦП, подключенный к Устройство Cloud TPU) получает данные и предварительно обрабатывает их перед «подача» к оборудованию Cloud TPU.
- Параллелизм данных: ядра в облачном TPU выполняют идентичные программа, размещенная в их собственном HBM синхронно. А операция редукции выполняется в конце каждого шага нейронной сети через все ядра.
Когда использовать TPU
Cloud TPU оптимизированы для конкретных рабочих нагрузок. В некоторых ситуациях вы можете хотите использовать графические процессоры или процессоры в экземплярах Compute Engine, чтобы выполнять рабочие нагрузки машинного обучения. В общем, вы можете решить, какое железо лучше всего подходит для вашей рабочей нагрузки на основе следующих рекомендаций:
ЦП
- Быстрое прототипирование, требующее максимальной гибкости
- Простые модели, не требующие много времени для обучения
- Маленькие модели с малыми эффективными партиями
- Модели, в которых преобладают пользовательские операции TensorFlow, написанные на С ++
- Модели, которые ограничены доступным вводом-выводом или пропускной способностью сети хост-система
Графические процессоры
- Модели, для которых источник не существует или слишком обременительн, чтобы его изменить
- Модели со значительным количеством настраиваемых операций TensorFlow, которые должны работать хотя бы частично на процессорах
- Модели с операциями TensorFlow, которые недоступны на
Cloud TPU (см. Список
доступные операции TensorFlow)
- Модели среднего и большого размера с большими эффективными размерами партий
ТПУ
- Модели, в которых преобладают матричные вычисления
- Модели без пользовательских операций TensorFlow внутри основного цикла обучения
- Модели, которые тренируются неделями или месяцами
- Большие и очень большие модели с очень большими эффективными размерами партий
 Список
доступные операции TensorFlow)
Список
доступные операции TensorFlow)Cloud TPU не подходят для следующих рабочих нагрузок:
- Программы линейной алгебры, которые требуют частого ветвления или над которыми доминируют поэлементно по алгебре.TPU оптимизированы для работы с быстрой и громоздкой матрицей умножение, поэтому рабочая нагрузка, в которой не преобладает матричное умножение вряд ли будет хорошо работать на TPU по сравнению с другими платформами.
- Рабочие нагрузки с ограниченным доступом к памяти могут быть недоступны на
ТПУ.
- Рабочие нагрузки, требующие высокоточной арифметики. Например, Арифметика с двойной точностью не подходит для TPU.
- Рабочие нагрузки нейронной сети, которые содержат настраиваемые операции TensorFlow, написанные на C ++.В частности, пользовательские операции в теле основного цикла обучения: не подходит для ТПУ.

Рабочие нагрузки нейронной сети должны иметь возможность выполнять несколько итераций всего цикл обучения на ТПУ. Хотя это не принципиальное требование к TPU сами по себе, это одно из текущих ограничений программной экосистемы TPU что требуется для эффективности.
Отличия от обычного обучения
Типичный обучающий граф TensorFlow состоит из нескольких перекрывающихся подграфов которые обеспечивают множество функций, включая:
- Операции ввода-вывода для чтения данных обучения.
- Этапы предварительной обработки ввода, часто соединенные через очереди.
- Переменные модели.
- Код инициализации для этих переменных.
- Сама модель.
- Функции потерь.
- Код градиента (обычно создается автоматически).
- Краткое описание операций по обучению мониторингу.
- Сохранить / восстановить операции для контрольной точки.

On Cloud TPU, программы TensorFlow компилируются
Оперативный компилятор XLA. Когда
обучение на Cloud TPU, код только , который можно скомпилировать и
выполненный на фурнитуре соответствует плотным частям модели,
подграфы потери и градиента.Все остальные части программы TensorFlow работают на
хост-машины (сервер Cloud TPU) как часть обычного
распределенный сеанс TensorFlow. Обычно это операции ввода-вывода.
которые читают данные обучения, любой код предварительной обработки (например: декодирование
сжатые изображения, случайная выборка / обрезка, сборка обучающих мини-пакетов)
и все части графика обслуживания, такие как сохранение / восстановление контрольной точки.
Лучшие практики разработки моделей
Один чип Cloud TPU содержит 2 ядра, каждое из которых содержит множественные матричные блоки (MXU), предназначенные для ускорения программ, в которых доминируют умножения и свертки плотных матриц (см. Аппаратная архитектура).Программы, которые тратят значительную часть времени выполнения на выполнение матричные умножения обычно хорошо подходят для Cloud TPU. Программа, в вычислениях которой преобладают нематричные операции. такие как добавление, изменение формы или конкатенация, скорее всего, не обеспечат высокий уровень MXU утилизация. Ниже приведены некоторые рекомендации, которые помогут вам выбрать и построить модели. которые подходят для Cloud TPU.
Реплики
Одно устройство Cloud TPU состоит из четырех микросхем, каждый из которых имеет
два ядра TPU.Поэтому для эффективного использования Cloud TPU необходимо
программа должна использовать каждое из восьми ядер. TPUEstimator
предоставляет оператор графика для построения и запуска реплицированного
вычисление.
Каждая реплика по сути является копией графа обучения, который запускается на каждом
core и тренирует мини-партию, содержащую 1/8 от общего размера партии.
TPUEstimator
предоставляет оператор графика для построения и запуска реплицированного
вычисление.
Каждая реплика по сути является копией графа обучения, который запускается на каждом
core и тренирует мини-партию, содержащую 1/8 от общего размера партии.
Макет
Компилятор XLA выполняет преобразования кода, включая мозаичное размещение матрицы. умножить на более мелкие блоки, чтобы эффективно выполнять вычисления на матричный блок (MXU).Структура оборудования MXU, систолический 128×128 массива, а также конструкции ТПУ подсистема памяти, которая предпочитает размеры, кратные 8, используются компилятор XLA для повышения эффективности тайлинга. Следовательно, некоторые макеты более способствуют укладке плитки, в то время как другие требуют выполнения переделок перед их можно облицовывать плиткой. Операции изменения формы часто связаны с памятью Облако ТПУ.
Формы
Компилятор XLA компилирует график TensorFlow как раз вовремя для первого пакета. Если какие-либо последующие партии имеют другую форму, модель не работает.
(Перекомпилировать график каждый раз, когда форма меняется слишком медленно.) Следовательно,
любая модель, имеющая тензоры с динамическими формами, изменяющимися во время выполнения, не
хорошо подходит для TPU.
Если какие-либо последующие партии имеют другую форму, модель не работает.
(Перекомпилировать график каждый раз, когда форма меняется слишком медленно.) Следовательно,
любая модель, имеющая тензоры с динамическими формами, изменяющимися во время выполнения, не
хорошо подходит для TPU.
Прокладка
Высокопроизводительная программа Cloud TPU — это программа, в которой можно легко разбить на блоки размером 128×128. Когда вычисление матрицы не может занимать весь MXU, компилятор дополняет тензоры нулями. Есть два недостатка до набивки:
- Тензоры с добавлением нулей недостаточно используют ядро TPU.
- Padding увеличивает объем памяти на кристалле, необходимый для тензора и в крайнем случае может привести к ошибке нехватки памяти.
Хотя заполнение выполняется компилятором XLA автоматически при необходимости, один
может определить количество выполняемых отступов с помощью
op_profile
орудие труда. Вы можете избежать заполнения, выбрав тензорные измерения, которые хорошо подходят
в ТПУ.
Размеры
Выбор подходящей тензорной размерности имеет большое значение для извлечения максимальной производительность от оборудования TPU, особенно MXU.Компилятор XLA пытается максимально использовать либо размер пакета, либо размер объекта. использовать MXU. Следовательно, одно из них должно быть кратно 128. В противном случае компилятор дополнит один из них до 128. В идеале размер пакета, а также функция размеры должны быть кратны 8, что позволяет получить высокую производительность из подсистемы памяти.
Операции
См. Список доступных операций TensorFlow.
Интеграция управления сервисом VPC
Cloud TPU VPC Service Controls позволяет определять безопасность
периметры вокруг ваших ресурсов Cloud TPU и контролировать перемещение данных
по периметру границы.Чтобы узнать больше об элементах управления службами VPC, см. Обзор управления службами VPC. Чтобы
узнать об ограничениях в использовании Cloud TPU с
Управление службами VPC, см.
поддерживаемые продукты и ограничения.
Обзор управления службами VPC. Чтобы
узнать об ограничениях в использовании Cloud TPU с
Управление службами VPC, см.
поддерживаемые продукты и ограничения.
Кромка TPU
Модели машинного обучения, обученные в облаке, все чаще нуждаются в запуске вывод «на краю», то есть на устройствах, которые работают на краю Интернет вещей (IoT). Эти устройства включают датчики и другие интеллектуальные устройства. которые собирают данные в реальном времени, принимают разумные решения, а затем принимают меры или передавать свою информацию на другие устройства или в облако.
Поскольку такие устройства должны работать с ограниченной мощностью (включая питание от батареи),
Google разработал сопроцессор Edge TPU для ускорения вывода машинного обучения на
маломощные устройства. Отдельный Edge TPU может выполнить 4 триллиона
операций в секунду (4 TOPS), потребляя всего 2 Вт мощности — другими словами,
вы получаете 2 ТОПа на ватт. Например, Edge TPU может выполнять самые современные
модели мобильного зрения, такие как MobileNet V2 с частотой почти 400 кадров в секунду, и
энергоэффективным способом.
Этот маломощный ускоритель машинного обучения дополняет Cloud TPU и Cloud IoT для предоставить сквозную (от облака до границы, оборудование + программное обеспечение) инфраструктуру, которая облегчает ваши решения на основе ИИ.
Edge TPU доступен для ваших собственных прототипов и производственных устройств в несколько форм-факторов, в том числе одноплатный компьютер, система-на-модуле, Карта PCIe / M.2 и модуль для поверхностного монтажа. Для получения дополнительной информации о Edge TPU и все доступные продукты, посетите coral.ai.
Что дальше
- Прочтите краткое руководство TPU, чтобы начать использовать Ресурсы Cloud TPU.
- Выполните одно из руководств по Cloud TPU. чтобы узнать, как выполнять распространенные рабочие нагрузки машинного обучения на Ресурсы Cloud TPU.
Системная архитектура | Облако ТПУ | Google Cloud
Этот документ описывает архитектуру всего оборудования и программного обеспечения. компоненты системы Cloud TPU.
компоненты системы Cloud TPU.
Обзор
Tensor Processing Units (TPU) — это специально разработанные Google специализированные интегральные схемы (ASIC), используемые для ускорения машины учебные нагрузки. Эти TPU разработаны с нуля с преимуществом обширного опыта и лидерства Google в области машинного обучения.
Вы можете использовать Cloud TPU и TensorFlow запускать собственные рабочие нагрузки машинного обучения в Google Аппаратный ускоритель TPU. Cloud TPU — это разработан для максимальной производительности и гибкости помогать исследователям, разработчикам и компаниям создавать вычисления TensorFlow кластеры, которые могут использовать процессоры, графические процессоры и TPU. API-интерфейсы Tensorflow высокого уровня упростить запуск реплицированных моделей на оборудовании Cloud TPU.
Ваши приложения TensorFlow могут получать доступ к узлам TPU из контейнеров, экземпляров,
или сервисы в Google Cloud.Приложение требует подключения к
ваш узел TPU через вашу сеть VPC.
Версии TPU
Каждая версия TPU определяет конкретные аппаратные характеристики устройства TPU. Версия TPU определяет архитектуру для каждого ядра TPU, количество память с высокой пропускной способностью (HBM) для каждого ядра TPU, межсоединения между ядра на каждом устройстве TPU и сетевые интерфейсы, доступные для связь между устройствами. Например, каждая версия TPU имеет следующие характеристики:
- TPU v2:
- 8 ГиБ HBM для каждого ядра TPU
- Один MXU для каждого ядра TPU
- Всего до 512 ядер TPU и 4 ТиБ общей памяти в TPU Pod
- TPU v3:
- 16 ГиБ HBM для каждого ядра TPU
- Два MXU для каждого ядра TPU
- Всего до 2048 ядер TPU и 32 ТиБ общей памяти в TPU Pod
Каждое ядро TPU имеет скалярные, векторные и матричные блоки (MXU).MXU обеспечивает
большая часть вычислительной мощности микросхемы TPU. Каждый MXU способен выполнять 16K
операции умножения-накопления в каждом цикле при уменьшенных
bfloat16
точность. Bfloat16 — это 16-битное представление с плавающей запятой, которое обеспечивает
лучшее обучение и точность модели, чем у IEEE
половинная точность
представление.
Bfloat16 — это 16-битное представление с плавающей запятой, которое обеспечивает
лучшее обучение и точность модели, чем у IEEE
половинная точность
представление.
Каждое из ядер на устройстве TPU может выполнять пользовательские вычисления (операции XLA) независимо. Межсоединения с высокой пропускной способностью позволяют микросхемам обмениваться данными непосредственно друг с другом на устройстве TPU.В конфигурации TPU Pod выделенные высокоскоростные сетевые интерфейсы соединяют несколько устройств TPU вместе для обеспечения большего количества ядер TPU и большего пула памяти TPU для ваши рабочие нагрузки машинного обучения.
Повышение производительности TPU v3
Увеличение числа операций в секунду на ядро и объем памяти в конфигурациях TPU v3 может улучшите производительность ваших моделей следующими способами:
- Конфигурации TPU v3 обеспечивают значительное повышение производительности на ядро для
вычислительные модели. Модели с привязкой к памяти в конфигурациях TPU v2 могут
не достичь такого же улучшения производительности, если они также привязаны к памяти
на конфигурациях TPU v3.
- В случаях, когда данные не помещаются в память в конфигурациях TPU v2, TPU v3 может обеспечить улучшенную производительность и сокращение пересчета промежуточных ценности (повторная материализация). Конфигурации
- TPU v3 могут запускать новые модели с размерами партий, которые не подходят на конфигурациях TPU v2. Например, TPU v3 может позволить более глубокие ResNets и более крупные изображения с RetinaNet.
 Модели с привязкой к памяти в конфигурациях TPU v2 могут
не достичь такого же улучшения производительности, если они также привязаны к памяти
на конфигурациях TPU v3.
Модели с привязкой к памяти в конфигурациях TPU v2 могут
не достичь такого же улучшения производительности, если они также привязаны к памяти
на конфигурациях TPU v3.Модели с почти ограниченным вводом («подача») на TPU v2 поскольку шаги обучения ожидают ввода, также могут быть связаны вводимые данные с помощью Cloud TPU v3. В руководство по производительности трубопровода может помочь вам решить проблемы с подачей.
Вы можете определить, улучшится ли производительность вашей модели по сравнению с TPU v3
путем выполнения тестов на разных версиях TPU и
мониторинг производительности с помощью
Инструменты TensorBoard.
конфигурации TPU
В центре обработки данных Google устройства TPU доступны в следующих конфигурации для TPU v2 и TPU v3:
- TPU с одним устройством, которые представляют собой отдельные устройства TPU, которые не подключены друг к другу по выделенной высокоскоростной сети.Ты не может объединить несколько типов TPU для одного устройства для совместной работы над одним нагрузка.
- TPU Pods, которые представляют собой кластеры устройств TPU, которые подключены друг к другу по выделенным высокоскоростным сетям.
ТПУ для одного устройства
Конфигурация TPU с одним устройством в центре обработки данных Google — это одно устройство TPU без выделенных высокоскоростных сетевых подключений к другим устройствам TPU. Ваш Узел TPU подключается только к этому единственному устройству.
Для TPU с одним устройством микросхемы соединены между собой на устройстве таким образом, чтобы
связь между чипами не требует центрального процессора или сети хоста
Ресурсы.
При создании узла TPU вы указываете тип TPU. Например, вы можете
укажите v2-8 или v3-8 , чтобы настроить узел TPU с одним устройством.
TPU для одного устройства не являются частью конфигураций TPU Pod и не
занимают часть стручка TPU. Прочтите
Страница типов TPU, чтобы узнать, что
Для ваших узлов TPU доступны конфигурации TPU с одним устройством.
Стручки ТПУ
Конфигурация модуля TPU в центре обработки данных Google имеет несколько устройств TPU подключены друг к другу через выделенное высокоскоростное сетевое соединение.В хосты в вашем узле TPU распределяют рабочие нагрузки машинного обучения по всем устройств ТПУ.
В модуле TPU микросхемы TPU соединены между собой на устройстве, так что
связь между чипами не требует центрального процессора или сети хоста
Ресурсы. Кроме того, каждое из устройств TPU в блоке TPU подключено.
напрямую друг к другу по высокоскоростному соединению, которое пропускает
задержки связи при прохождении через хосты ЦП. Межсоединение
спроектирован с 4 высокоскоростными межсоединениями на микросхему, размещенными в двухмерном торе.Эта архитектура обеспечивает высокую пропускную способность, разделенную пополам — доступную пропускную способность.
между двумя половинами блока TPU в худшем случае.
Тактико-технические характеристики различных поколений ТПУ приведены в таблице.
следующая таблица, более подробная информация опубликована в
Доменно-ориентированный суперкомпьютер для обучения глубоких нейронных сетей
Межсоединение
спроектирован с 4 высокоскоростными межсоединениями на микросхему, размещенными в двухмерном торе.Эта архитектура обеспечивает высокую пропускную способность, разделенную пополам — доступную пропускную способность.
между двумя половинами блока TPU в худшем случае.
Тактико-технические характеристики различных поколений ТПУ приведены в таблице.
следующая таблица, более подробная информация опубликована в
Доменно-ориентированный суперкомпьютер для обучения глубоких нейронных сетей
| Элемент | ТПУ версии 2 | ТПУ версии 3 |
|---|---|---|
| Сетевые каналы x Гбит / с / чип | 4 х 496 | 4 х 656 |
| Пропускная способность с разделением на две части, терабит / полный блок | 15.9 | 42 |
При создании узла TPU вы указываете, что хотите, чтобы тип TPU занимал
либо полный модуль TPU, либо меньшая часть этого модуля TPU. Например,
Тип
Например,
Тип v2-512 TPU занимает полный модуль TPU v2, а тип v2-128 TPU занимает
только 1/4 часть v2 TPU Pod. Прочтите
Страница типов TPU, чтобы узнать, что
Конфигурации TPU Pod доступны для ваших узлов TPU.
Модуль v2 TPU Pod обеспечивает максимальную конфигурацию из 64 устройств, всего 512 ядер TPU v2 и 4 ТиБ памяти TPU.
Модуль v3 TPU Pod обеспечивает максимальную конфигурацию 256 устройств, всего 2048 ядер TPU v3 и 32 ТиБ памяти TPU.
См. Раздел версии TPU, чтобы узнать больше об архитектурной различия между разными версиями TPU.
Вы можете использовать Cloud TPU API
для автоматизации управления TPU для ваших узлов TPU независимо от их размера. Как
в результате его легко масштабировать до массивных вычислительных кластеров, запускать рабочие нагрузки,
и масштабируйте эти кластеры обратно, когда ваши рабочие нагрузки будут завершены.В
аппаратная поддержка, встроенная в чипы, обеспечивает эффективную линейную производительность
масштабирование для широкого спектра рабочих нагрузок глубокого обучения. На практике
Программный стек Cloud TPU устраняет сложность создания,
запущены и загружены программы TPU Cloud.
На практике
Программный стек Cloud TPU устраняет сложность создания,
запущены и загружены программы TPU Cloud.
Архитектура программного обеспечения
Когда вы запускаете приложение, TensorFlow генерирует граф вычислений и отправляет его на узел TPU через gRPC. Тип TPU, который вы выбираете для своего TPU node определяет, сколько устройств доступно для вашей рабочей нагрузки.Узел TPU составляет граф вычислений как раз вовремя и отправляет двоичный файл программы на одно или несколько устройств TPU для исполнение. Входные данные для модели часто хранятся в облачном хранилище. ТПУ node передает потоки входных данных на одно или несколько устройств TPU для потребления.
На блок-схеме ниже показана архитектура программного обеспечения Cloud TPU. состоящий из модели нейронной сети, TPU Estimator и клиента TensorFlow, Сервер TensorFlow и компилятор XLA.
Оценщик TPU
Оценщики TPU представляют собой набор высокоуровневых API-интерфейсов, основанных на
Оценщики, которые
упростить модели построения для Cloud TPU и извлечь максимум
Производительность ТПУ. При написании модели нейронной сети, использующей
Cloud TPU, вам следует использовать API-интерфейсы TPU Estimator.
При написании модели нейронной сети, использующей
Cloud TPU, вам следует использовать API-интерфейсы TPU Estimator.
Клиент TensorFlow
ОценщикиTPU переводят ваши программы в операции TensorFlow, которые затем преобразуется в вычислительный граф клиентом TensorFlow. TensorFlow клиент передает вычислительный граф на сервер TensorFlow.
Сервер TensorFlow
Сервер TensorFlow работает на сервере Cloud TPU. Когда сервер получает вычислительный граф от клиента TensorFlow, сервер выполняет следующие действия:
- Загрузить входные данные из облачного хранилища
- Разделите график на части, которые могут работать на облачном TPU и те, которые должны работать на CPU
- Сгенерировать операции XLA, соответствующие подграфе, который должен выполняться Облако TPU
- Вызов компилятора XLA
Компилятор XLA
XLA — это своевременный компилятор, который принимает в качестве входных данных High Level Optimizer (HLO)
операции, производимые сервером TensorFlow. XLA генерирует двоичный
код для запуска в Cloud TPU, включая оркестровку данных из
внутренняя память для аппаратных исполнительных устройств и межкристальная связь.
Сгенерированный двоичный файл загружается в Cloud TPU с помощью PCIe.
связь между сервером Cloud TPU и
Cloud TPU, а затем запускается на выполнение.
XLA генерирует двоичный
код для запуска в Cloud TPU, включая оркестровку данных из
внутренняя память для аппаратных исполнительных устройств и межкристальная связь.
Сгенерированный двоичный файл загружается в Cloud TPU с помощью PCIe.
связь между сервером Cloud TPU и
Cloud TPU, а затем запускается на выполнение.
Что дальше
Блок тензорной обработки (TPU) — Semiconductor Engineering
Центр знаний
Разработанный Google процессор ASIC для машинного обучения, работающий с экосистемой TensorFlow.
Блок тензорной обработки (TPU), иногда называемый блоком обработки TensorFlow, представляет собой специальный ускоритель для машинного обучения. Это ИС обработки, разработанная Google для обработки нейронной сети с использованием TensorFlow.TPU — это ASIC (специализированные интегральные схемы), используемые для ускорения определенных рабочих нагрузок машинного обучения с использованием элементов обработки — небольших DSP с локальной памятью — в сети, чтобы эти элементы могли взаимодействовать друг с другом и передавать данные.
Это ИС обработки, разработанная Google для обработки нейронной сети с использованием TensorFlow.TPU — это ASIC (специализированные интегральные схемы), используемые для ускорения определенных рабочих нагрузок машинного обучения с использованием элементов обработки — небольших DSP с локальной памятью — в сети, чтобы эти элементы могли взаимодействовать друг с другом и передавать данные.
TensorFlow — это платформа с открытым исходным кодом для машинного обучения, используемая, в частности, для классификации изображений, обнаружения объектов, языкового моделирования, распознавания речи.
TPU имеют библиотеки оптимизированных моделей, используют встроенную память с высокой пропускной способностью (HBM) и в каждом ядре имеют скалярные, векторные и матричные блоки (MXU).Блоки MXU выполняют обработку по 16K операций умножения-накопления в каждом цикле. Ввод и вывод 32-битных чисел с плавающей запятой упрощены через Bfloat16. Ядра выполняют пользовательские вычисления (операции XLA) отдельно. Google предлагает доступ к облачным TPU на своих серверах.
Google предлагает доступ к облачным TPU на своих серверах.
Google утверждает, что TPU полезны для:
- Модели, в которых преобладают матричные вычисления
- Модели без пользовательских операций TensorFlow внутри основного цикла обучения
- Модели, которые тренируются неделями или месяцами
- Большие и очень большие модели с очень большими эффективными размерами партий
В остальном центральные и графические процессоры лучше подходят для быстрого прототипирования, простых моделей, малых и средних размеров пакетов, ранее существовавшего кода, который нельзя изменить, некоторых математических задач и прочего.* Подробнее см. Облачные тензорные процессоры (TPU).
В 2013 году для Google стало очевидно, что им придется удвоить количество имеющихся у них центров обработки данных, если они не смогут разработать чип, способный обрабатывать логические выводы машинного обучения. Получившийся TPU, по словам Google, имеет «в 15–30 раз более высокую производительность и в 30–80 раз более высокую производительность на ватт, чем современные процессоры и графические процессоры».
«Фундаментальная тенденция, которая движет этим явлением, — это специализация по сравнению с универсальностью. Использование графического процессора от Nvidia для приложения машинного обучения неэффективно примерно на 84%.Вы тратите 84% этой части. Если вы развертываете миллионы и миллионы графических процессоров в Google, у вас есть довольно большой стимул создать TPU вместо покупки графического процессора у Nvidia. Это верно во всех отношениях, — сказал Джек Хардинг, eSilicon.
Архитектура процессора TensorFlow. Источник: Google
Последний TPU от Google содержит 65 536 8-битных блоков MAC и потребляет столько энергии, что чип требует водяного охлаждения. Потребляемая мощность TPU составляет от 200 Вт до 300 Вт.
Версии TPU включают конфигурации с одним устройством и модулем:
- Облако TPU v2
- Cloud TPU v3
- Cloud TPU v2 Pod (бета)
- 11,5 петафлопс
- 4 ТБ HBM
- Двухмерная тороидальная ячеистая сеть
- Cloud TPU v3 Pod (бета)
- 100+ петафлопс
- 32 ТБ HBM
- Двухмерная тороидальная ячеистая сеть
- Ускоритель вывода Edge TPU
Поды — это несколько устройств, связанных вместе. Посетите страницы Google TPU для получения дополнительной информации.
Посетите страницы Google TPU для получения дополнительной информации.
Cloud TPU v3 (показанный выше на Hot Chips 2019 в Стэнфордском университете) работает со скоростью 420 терафлопс и использует 128 ГБ HBM. (Источник фото: Semiengineering.com/Susan Rambo.)
Исходные страницы Google:
СВЯЗАННЫЕ С
Ищете дополнительную информацию о процессорах? Найдите их здесь.
Домашняя страница центра знаний
PPT — Turbo Pascal Units (TPU) PowerPoint Presentation, скачать бесплатно
Turbo Pascal Units (TPU) Brent M.DingleTexas A&M University Глава 8 — Раздел 1 (и некоторые из статей «Освоение Turbo Pascal 5.5, 3-е издание» Тома Свана)
Что такое модуль? • Модуль — это набор процедур, функций и определенных констант (и прочего), которые можно скомпилировать отдельно от любой программы. • Процедуры, функции и константы, которые определены в модуле, могут затем использоваться любой программой, которую вы напишете в будущем, без необходимости их объявления в программе. • Расширение файла для модулей Turbo Pascal:.ТПУ.
• Процедуры, функции и константы, которые определены в модуле, могут затем использоваться любой программой, которую вы напишете в будущем, без необходимости их объявления в программе. • Расширение файла для модулей Turbo Pascal:.ТПУ.
Что делает юнит? • Единицы написаны аналогично программам. • Они разделены на четыре части (обратите внимание на идентификаторы книг только 2 из них в начале, но все четыре упоминаются в конце) • Объявление / заголовок объекта • Раздел интерфейса устройства • Раздел реализации модуля • Инициализация устройства
Объявление объекта • Это похоже на объявление или строку заголовка программы, она дает устройству имя. • Для других программ для доступа к устройству им потребуется строка кода, которая гласит: USES [имя модуля], где [имя модуля] — это имя модуля, к которому они хотят получить доступ.• Лучше всего называть устройства такими же, как их имя файла (без расширения . tpu). См. Комментарий к именам файлов, стр. 278.
tpu). См. Комментарий к именам файлов, стр. 278.
Интерфейс устройства • Это общедоступный раздел устройства. • Он описывает все функции внутри модуля, которые он может использовать совместно с программами или другими модулями. • Он содержит метки, константы, типы, переменные, а также объявления функций и процедур. • Думайте об этом как об описании того, как кто-то может «взаимодействовать» с устройством, чтобы использовать его.
Реализация модуля • Это частный раздел модуля.• Эта часть содержит фактические операторы, реализующие процедуры и функции, объявленные в разделе интерфейса. • Константы, типы и переменные также могут быть помещены в этот раздел, но они могут использоваться только этим устройством. Назовите эти элементы частными константами, частными типами, частными переменными. • Вы также можете объявить частные функции и частные процедуры, разместив их здесь и исключив из раздела интерфейса.
Инициализация • Это дополнительный блок операторов, очень похожий на основную часть программы на языке Pascal.• Найденные здесь операторы будут выполняться перед любыми операторами в программе, использующей модуль. • Это позволяет устройству инициализировать свои собственные переменные и выполнять другие задачи еще до запуска основной программы. • Многие единицы оставляют этот раздел пустым / пустым.
Структура файла объекта UNIT [имя]; ИНТЕРФЕЙС {здесь идут объявления USES} {здесь идут объявления CONST, TYPE и VAR} {здесь идут объявления процедур и функций} IMPLEMENTATION {здесь находятся частные объявления CONST, TYPE и VAR} {Поместите здесь тела процедур и функций} BEGIN {необязательно} { Здесь идут операторы инициализации} END.
Bizarre Fact • Поскольку раздел инициализации является необязательным, BEGIN в модуле также необязателен. • Однако КОНЕЦ. необходимо. • Это единственный раз, когда у вас будет КОНЕЦ без НАЧАЛА.
необходимо. • Это единственный раз, когда у вас будет КОНЕЦ без НАЧАЛА.
Общий предопределенный блок • Вероятно, вы уже использовали функцию clrscr. • Эта функция является частью блока CRT. • Блок ЭЛТ содержит несколько различных функций и процедур для доступа к монитору (когда-то он назывался ЭЛТ-устройством = устройством с катодно-лучевой трубкой).
Компиляция модулей • Ваш технический специалист должен показать вам, как скомпилировать модуль в лаборатории. • Модуль BooleIn, описанный на страницах 282 и 283, вместе с соответствующей программой TestBooleIn может быть хорошим местом для начала. • Если они хороши, они уже напечатали их и разместили где-нибудь для загрузки, поэтому все, что вам нужно сделать, это скомпилировать и протестировать их. • Надеюсь, это не займет больше 20 минут.
Предлагаемые проблемы (без классификации) • стр. 290: • 1, 4, 5, 6, 7 • подумайте о 2 и 3
Конечные блоки
Вводное руководство — PyTorch-Lightning 0 .
 7.1 документация
7.1 документацияPyTorch Lightning предоставляет очень простой шаблон для организации кода PyTorch. Один раз вы организовали его в модуль LightningModule, он автоматизирует для вас большую часть обучения.
Для иллюстрации, вот типичная структура проекта PyTorch, организованная в LightningModule.
По мере роста сложности вашего проекта с такими вещами, как 16-битная точность, распределенное обучение и т.д. быстро становится обременительным и отвлекает от основного кода исследования.
Цель руководства
В этом руководстве рассматриваются основные части библиотеки, чтобы помочь вам понять что делает каждая часть. Но в конце концов вы пишете тот же код PyTorch … просто организуйте его. в шаблон LightningModule, что означает, что вы сохраняете ВСЮ гибкость без необходимости иметь дело с любой из шаблонного кода
Чтобы показать, как работает Lightning, мы начнем с классификатора MNIST. Мы закончим показывать, как
использовать наследование для очень быстрого создания AutoEncoder.![]()
Примечание
Любой проект DL / ML PyTorch вписывается в структуру Lightning. Здесь мы просто сосредоточимся на 3 типах исследований, чтобы проиллюстрировать.
Философия молнии
Факторы молнии Код DL / ML на три типа:
Код исследования
Инженерный код
Неосновной код
Код исследования
В примере генерации MNIST исследовательским кодом будет конкретная система и способ ее обучения (например, GAN или VAE).В Lightning этот код абстрагируется модулем LightningModule .
l1 = nn.Linear (...) l2 = nn.Linear (...) decoder = Декодер () х1 = l1 (х) х2 = l2 (х2) out = декодер (функции, x) потеря = perceptual_loss (x1, x2, x) + CE (out, x)
Инженерный код
Инженерный код — это все коды, относящиеся к обучению этой системы. Такие вещи, как ранняя остановка, распространение
через графические процессоры, 16-битную точность и т. д. Обычно это ОДИН ОДИН код для большинства проектов.
д. Обычно это ОДИН ОДИН код для большинства проектов.
В Lightning этот код извлекается обучающим курсом .
model.cuda (0)
х = х.cuda (0)
распределенный = РаспределенныйПараллельный (модель)
с gpu_zero:
download_data ()
dist.barrier ()
Несущественный код
Это код, который помогает исследованию, но не имеет отношения к коду исследования. Вот некоторые примеры: 1. Проверьте градиенты 2. Войдите в тензорную плату.
В Lightning этот код абстрагируется с помощью обратных вызовов .
# образцы журнала
z = Q.rsample ()
генерируется = декодер (z)
self.experiment.log ('изображения', создано)
Элементы исследовательского проекта
Для каждого исследовательского проекта требуются одни и те же основные ингредиенты:
Модель A
Данные для поездов / валов / испытаний
Оптимизатор (и)
Вычисления шагов обучения
Вычисления шагов проверки
Тестовые пошаговые вычисления
Модель
LightningModule предоставляет структуру того, как организовать эти 5 ингредиентов.
Начнем сначала с модели. В этом случае мы спроектируем 3-х слойная нейронная сеть.
импортная горелка
из torch.nn импортировать функционал как F
из факела импорт нн
импортировать pytorch_lightning как pl
класс LitMNIST (pl.LightningModule):
def __init __ (сам):
super (LitMNIST, self) .__ init __ ()
# mnist изображений: (1, 28, 28) (каналы, ширина, высота)
self.layer_1 = torch.nn.Linear (28 * 28, 128)
self.layer_2 = torch.nn.Linear (128, 256)
self.layer_3 = torch.nn.Linear (256, 10)
def вперед (self, x):
batch_size, каналы, ширина, высота = x.размер()
# (b, 1, 28, 28) -> (b, 1 * 28 * 28)
x = x.view (размер_пакета, -1)
# слой 1
x = self.layer_1 (x)
х = torch.relu (х)
# слой 2
x = self.layer_2 (x)
х = torch.relu (х)
# слой 3
x = self.layer_3 (x)
# распределение вероятностей по меткам
x = torch.log_softmax (x, dim = 1)
вернуть х
Обратите внимание, что это модуль LightningModule вместо torch. nn.Module . Модуль LightningModule
эквивалентно модулю PyTorch, за исключением того, что он имеет дополнительные функции.Однако вы можете использовать это
Точно так же, как и модуль PyTorch.
nn.Module . Модуль LightningModule
эквивалентно модулю PyTorch, за исключением того, что он имеет дополнительные функции.Однако вы можете использовать это
Точно так же, как и модуль PyTorch.
net = LitMNIST () x = torch.Tensor (1, 1, 28, 28) out = net (x)
Ушел:
Данные
Модуль Lightning также организует загрузчики данных и обработку данных. Вот код PyTorch для загрузки MNIST
из torch.utils.data import DataLoader, random_split
из torchvision.datasets импортировать MNIST
импорт ОС
из наборов данных импорта torchvision, преобразовывает
# трансформируется
# prepare преобразует стандарт в MNIST
преобразовать = преобразовывает.Составить ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
# данные
mnist_train = MNIST (os.getcwd (), train = True, download = True)
mnist_train = загрузчик данных (mnist_train, batch_size = 64)
При использовании PyTorch Lightning мы используем тот же код, за исключением того, что мы организуем его в Модуль LightningModule
из torch.
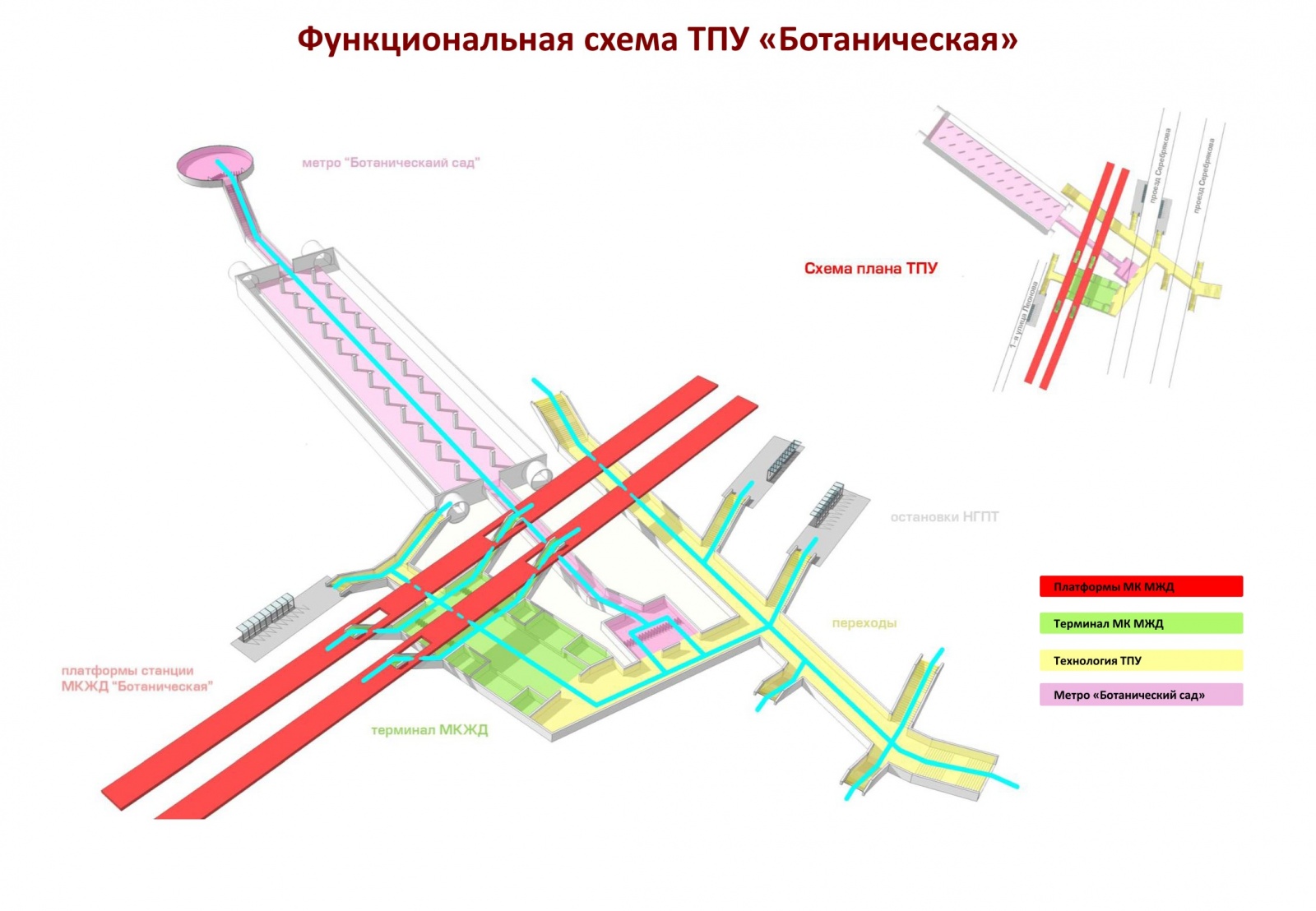 utils.data import DataLoader, random_split
из torchvision.datasets импортировать MNIST
импорт ОС
из наборов данных импорта torchvision, преобразовывает
класс LitMNIST (пл.LightningModule):
def train_dataloader (сам):
transform = transforms.Compose ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
вернуть DataLoader (mnist_train, batch_size = 64)
utils.data import DataLoader, random_split
из torchvision.datasets импортировать MNIST
импорт ОС
из наборов данных импорта torchvision, преобразовывает
класс LitMNIST (пл.LightningModule):
def train_dataloader (сам):
transform = transforms.Compose ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
вернуть DataLoader (mnist_train, batch_size = 64)
Обратите внимание, что код точно такой же, за исключением того, что теперь загрузка обучающих данных организована модулем LightningModule. по методу train_dataloader .Это здорово, потому что если вы столкнетесь с проектом, который использует Lightning, и захотите Чтобы выяснить, как они подготавливают данные для обучения, вы можете просто посмотреть метод train_dataloader .
Однако обычно мы хотим отделить то, что записывает на диск при обработке данных, от
такие вещи, как преобразования, которые происходят в памяти.
класс LitMNIST (pl.LightningModule):
def prepare_data (self):
только # загрузка
MNIST (os.getcwd (), train = True, download = True)
def train_dataloader (сам):
# не скачивать, просто преобразовать
преобразовать = преобразовывает.Составить ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
вернуть DataLoader (mnist_train, batch_size = 64)
Выполнение этого в методе prepare_data гарантирует, что когда у вас несколько графических процессоров, вы не перезапишете данные. Это надуманный пример но с такими вещами, как NLP или Imagenet, все становится сложнее.
Обычно заполняйте эти методы следующим образом:
класс ЛитМНИСТ (пл.LightningModule):
def prepare_data (self):
# элемент здесь выполняется один раз в самом начале обучения
# перед началом любого распределенного обучения
# скачать материал
# сохранить на диск
# так далее. ..
def train_dataloader (сам):
# преобразование данных
# создание набора данных
# вернуть DataLoader
 ..
def train_dataloader (сам):
# преобразование данных
# создание набора данных
# вернуть DataLoader
..
def train_dataloader (сам):
# преобразование данных
# создание набора данных
# вернуть DataLoader
Оптимизатор
Далее мы выбираем, какой оптимизатор использовать для обучения нашей системы. В PyTorch мы делаем это так:
от torch.optim import Adam optimizer = Адам (LitMNIST ().параметры (), lr = 1e-3)
В Lightning мы делаем то же самое, но организуем это с помощью метода configure_optimizers. Если вы этого не укажете, Lightning будет автоматически использовать Adam (self.parameters (), lr = 1e-3) .
класс LitMNIST (pl.LightningModule):
def configure_optimizers (самостоятельно):
вернуть Адама (self.parameters (), lr = 1e-3)
Шаг обучения
Шаг обучения — это то, что происходит внутри цикла обучения.
для эпох в эпохах:
для партии в данных:
# УЧЕБНЫЙ ШАГ
#....
# УЧЕБНЫЙ ШАГ
loss.backward ()
optimizer.step ()
optimizer. zero_grad ()
 zero_grad ()
zero_grad ()
В случае MNIST мы делаем следующее
для эпох в эпохах:
для партии в данных:
# НАЧАЛО ТРЕНИРОВКИ
x, y = партия
logits = модель (x)
потеря = F.nll_loss (логиты, y)
# КОНЕЦ ТРЕНИРОВКИ
loss.backward ()
optimizer.step ()
optimizer.zero_grad ()
В Lightning все, что находится на этапе обучения, организовано с помощью функции training_step в LightningModule
класс ЛитМНИСТ (пл.LightningModule):
def training_step (self, batch, batch_idx):
x, y = партия
logits = self.forward (х)
потеря = F.nll_loss (логиты, y)
return {'loss': loss}
# возврат потерь (тоже работает)
Опять же, это тот же код PyTorch, за исключением того, что он организован модулем LightningModule. Этот код не ограничен, что означает, что он может быть таким же сложным, как полный seq-2-seq, цикл RL, GAN и т. Д.
Обучение
Пока мы определили 4 ключевых ингредиента в чистом PyTorch, но организовали код внутри LightningModule.![]()
Модель.
Данные обучения.
Оптимизатор.
Что происходит в цикле обучения.
Для наглядности напомним, что теперь полный LightningModule выглядит следующим образом.
класс LitMNIST (pl.LightningModule):
def __init __ (сам):
super (LitMNIST, self) .__ init __ ()
self.layer_1 = torch.nn.Linear (28 * 28, 128)
self.layer_2 = torch.nn.Linear (128, 256)
self.layer_3 = факел.nn.Linear (256, 10)
def вперед (self, x):
batch_size, каналы, ширина, высота = x.size ()
x = x.view (размер_пакета, -1)
x = self.layer_1 (x)
х = torch.relu (х)
x = self.layer_2 (x)
х = torch.relu (х)
x = self.layer_3 (x)
x = torch.log_softmax (x, dim = 1)
вернуть х
def train_dataloader (сам):
transform = transforms.Compose ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os. getcwd (), train = True, download = False, transform = transform)
вернуть DataLoader (mnist_train, batch_size = 64)
def configure_optimizers (самостоятельно):
вернуть Адам (сам.параметры (), lr = 1e-3)
def training_step (self, batch, batch_idx):
x, y = партия
logits = self.forward (х)
потеря = F.nll_loss (логиты, y)
# добавить логирование
журналы = {'потеря': потеря}
return {'потеря': потеря, 'журнал': журналы}
 getcwd (), train = True, download = False, transform = transform)
вернуть DataLoader (mnist_train, batch_size = 64)
def configure_optimizers (самостоятельно):
вернуть Адам (сам.параметры (), lr = 1e-3)
def training_step (self, batch, batch_idx):
x, y = партия
logits = self.forward (х)
потеря = F.nll_loss (логиты, y)
# добавить логирование
журналы = {'потеря': потеря}
return {'потеря': потеря, 'журнал': журналы}
getcwd (), train = True, download = False, transform = transform)
вернуть DataLoader (mnist_train, batch_size = 64)
def configure_optimizers (самостоятельно):
вернуть Адам (сам.параметры (), lr = 1e-3)
def training_step (self, batch, batch_idx):
x, y = партия
logits = self.forward (х)
потеря = F.nll_loss (логиты, y)
# добавить логирование
журналы = {'потеря': потеря}
return {'потеря': потеря, 'журнал': журналы}
Опять же, это тот же код PyTorch, за исключением того, что он организован модулем LightningModule. Эта организация теперь позволяет нам обучать эту модель
Поезд на CPU
из трейнера импорта pytorch_lightning model = LitMNIST () трейнер = Тренер () тренер.подходит (модель)
Вы должны увидеть следующую сводку весов и индикатор выполнения
Лесозаготовки
Когда мы добавили ключ log в словарь возврата, он вошел во встроенный регистратор тензорной таблицы. Но вы также могли войти, позвонив по телефону:
def training_step (self, batch, batch_idx):
# . ..
потеря = ...
self.logger.summary.scalar ('потеря', потеря)
 ..
потеря = ...
self.logger.summary.scalar ('потеря', потеря)
..
потеря = ...
self.logger.summary.scalar ('потеря', потеря)
Которая будет генерировать автоматические журналы тензорной доски.
Но вы также можете использовать любое из числа поддерживаемых нами регистраторов.
Обучение графическому процессору
Но красота — это все волшебство, которое вы можете сотворить с флагами тренера. Например, для запуска этой модели на GPU:
модель = LitMNIST () трейнер = трейнер (gpus = 1) trainer.fit (модель)
Обучение работе с несколькими GPU
Или вы также можете тренироваться на нескольких графических процессорах.
модель = LitMNIST () трейнер = трейнер (gpus = 8) trainer.fit (модель)
Или несколько узлов
# (32 графических процессора) model = LitMNIST () трейнер = трейнер (gpus = 8, num_nodes = 4, distribution_backend = 'ddp') тренер.подходит (модель)
Дополнительные сведения см. В руководстве по распределенным вычислениям.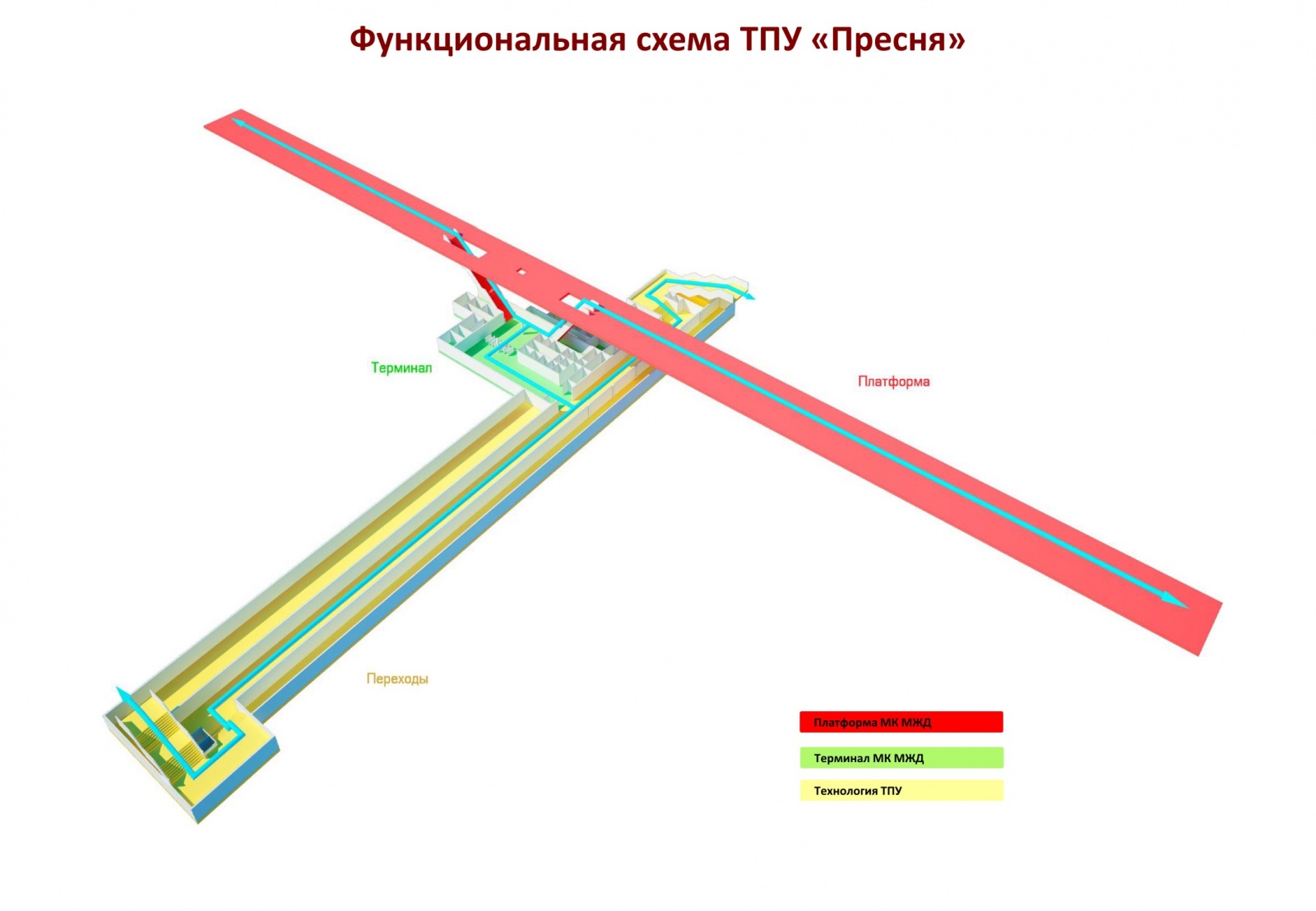
ТПУ
Знаете ли вы, что PyTorch можно использовать на TPU? Это очень сложно сделать, но мы работал с командой xla, чтобы использовать их потрясающую библиотеку, чтобы заставить это работать из коробки!
Тренируемся на Колабе (полная демонстрация доступна здесь)
Сначала измените среду выполнения на TPU (и переустановите Lightning).
Затем установите необходимую библиотеку xla (добавляет поддержку PyTorch на TPU)
импортных коллекций
from datetime import datetime, timedelta
импорт ОС
запросы на импорт
импорт потоковой передачи
_VersionConfig = коллекции.namedtuple ('_ VersionConfig', 'колеса, сервер')
ВЕРСИЯ = "torch_xla == nightly" # @ param ["xrt == 1.15.0", "torch_xla == nightly"]
КОНФИГУРАЦИЯ = {
'xrt == 1.15.0': _VersionConfig ('1.15', '1.15.0'),
'torch_xla == nightly': _VersionConfig ('nightly', 'XRT-dev {}'. format (
(datetime.today () - timedelta (1)). strftime ('% Y% m% d'))),
}[ВЕРСИЯ]
DIST_BUCKET = 'gs: // тпу-питторч / колеса'
TORCH_WHEEL = 'torch - {} - cp36-cp36m-linux_x86_64. whl'.format (CONFIG.wheels)
TORCH_XLA_WHEEL = 'torch_xla - {} - cp36-cp36m-linux_x86_64.whl'.format (КОНФИГ. колеса)
TORCHVISION_WHEEL = 'torchvision - {} - cp36-cp36m-linux_x86_64.whl'.format (CONFIG.wheels)
# Обновить версию TPU XRT
def update_server_xrt ():
print ('Обновление XRT на стороне сервера до {} ...'. формат (CONFIG.server))
url = 'http: // {TPU_ADDRESS}: 8475 / requestversion / {XRT_VERSION}' .format (
TPU_ADDRESS = os.environ ['COLAB_TPU_ADDR']. Split (':') [0],
XRT_VERSION = CONFIG.server,
)
print ('Завершено обновление XRT на стороне сервера: {}'. format (requests.post (url)))
update = threading.Thread (цель = update_server_xrt)
Обновить.Начните()
# Установить Colab TPU compat PyTorch / TPU колеса и зависимости
! pip uninstall -y torch torchvision
! gsutil cp "$ DIST_BUCKET / $ TORCH_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCH_XLA_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCHVISION_WHEEL".
! pip install "$ TORCH_WHEEL"
! pip install "$ TORCH_XLA_WHEEL"
! pip install "$ TORCHVISION_WHEEL"
! sudo apt-get установить libomp5
update. join ()
 whl'.format (CONFIG.wheels)
TORCH_XLA_WHEEL = 'torch_xla - {} - cp36-cp36m-linux_x86_64.whl'.format (КОНФИГ. колеса)
TORCHVISION_WHEEL = 'torchvision - {} - cp36-cp36m-linux_x86_64.whl'.format (CONFIG.wheels)
# Обновить версию TPU XRT
def update_server_xrt ():
print ('Обновление XRT на стороне сервера до {} ...'. формат (CONFIG.server))
url = 'http: // {TPU_ADDRESS}: 8475 / requestversion / {XRT_VERSION}' .format (
TPU_ADDRESS = os.environ ['COLAB_TPU_ADDR']. Split (':') [0],
XRT_VERSION = CONFIG.server,
)
print ('Завершено обновление XRT на стороне сервера: {}'. format (requests.post (url)))
update = threading.Thread (цель = update_server_xrt)
Обновить.Начните()
# Установить Colab TPU compat PyTorch / TPU колеса и зависимости
! pip uninstall -y torch torchvision
! gsutil cp "$ DIST_BUCKET / $ TORCH_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCH_XLA_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCHVISION_WHEEL".
! pip install "$ TORCH_WHEEL"
! pip install "$ TORCH_XLA_WHEEL"
! pip install "$ TORCHVISION_WHEEL"
! sudo apt-get установить libomp5
update.
whl'.format (CONFIG.wheels)
TORCH_XLA_WHEEL = 'torch_xla - {} - cp36-cp36m-linux_x86_64.whl'.format (КОНФИГ. колеса)
TORCHVISION_WHEEL = 'torchvision - {} - cp36-cp36m-linux_x86_64.whl'.format (CONFIG.wheels)
# Обновить версию TPU XRT
def update_server_xrt ():
print ('Обновление XRT на стороне сервера до {} ...'. формат (CONFIG.server))
url = 'http: // {TPU_ADDRESS}: 8475 / requestversion / {XRT_VERSION}' .format (
TPU_ADDRESS = os.environ ['COLAB_TPU_ADDR']. Split (':') [0],
XRT_VERSION = CONFIG.server,
)
print ('Завершено обновление XRT на стороне сервера: {}'. format (requests.post (url)))
update = threading.Thread (цель = update_server_xrt)
Обновить.Начните()
# Установить Colab TPU compat PyTorch / TPU колеса и зависимости
! pip uninstall -y torch torchvision
! gsutil cp "$ DIST_BUCKET / $ TORCH_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCH_XLA_WHEEL".
! gsutil cp "$ DIST_BUCKET / $ TORCHVISION_WHEEL".
! pip install "$ TORCH_WHEEL"
! pip install "$ TORCH_XLA_WHEEL"
! pip install "$ TORCHVISION_WHEEL"
! sudo apt-get установить libomp5
update. join ()
join ()
При распределенном обучении (несколько графических процессоров и несколько ядер TPU) каждое ядро GPU или TPU будет запускать копию этой программы.Это означает, что вы, не проявляя никакой осторожности, загрузите набор данных N раз, что вызовет всевозможные проблемы.
Чтобы решить эту проблему, переместите код загрузки в метод prepare_data в LightningModule. В этом методе мы делаем всю необходимую подготовку один раз (а не на каждом графическом процессоре).
класс LitMNIST (pl.LightningModule):
def prepare_data (self):
# преобразовать
transform = transforms.Compose ([transforms.ToTensor (), transforms.Normalize ((0.1307,), (0.3081,))])
# скачать
mnist_train = MNIST (os.getcwd (), train = True, download = True, transform = transform)
mnist_test = MNIST (os.getcwd (), train = False, download = True, transform = transform)
# поезд / вал сплит
mnist_train, mnist_val = random_split (mnist_train, [55000, 5000])
# назначить для использования в загрузчиках данных
self. train_dataset = mnist_train
self.val_dataset = mnist_val
self.test_dataset = mnist_test
def train_dataloader (сам):
вернуть DataLoader (self.train_dataset, batch_size = 64)
def val_dataloader (сам):
вернуть DataLoader (self.mnist_val, batch_size = 64)
def test_dataloader (сам):
вернуть DataLoader (self.mnist_test, batch_size = 64)
 train_dataset = mnist_train
self.val_dataset = mnist_val
self.test_dataset = mnist_test
def train_dataloader (сам):
вернуть DataLoader (self.train_dataset, batch_size = 64)
def val_dataloader (сам):
вернуть DataLoader (self.mnist_val, batch_size = 64)
def test_dataloader (сам):
вернуть DataLoader (self.mnist_test, batch_size = 64)
train_dataset = mnist_train
self.val_dataset = mnist_val
self.test_dataset = mnist_test
def train_dataloader (сам):
вернуть DataLoader (self.train_dataset, batch_size = 64)
def val_dataloader (сам):
вернуть DataLoader (self.mnist_val, batch_size = 64)
def test_dataloader (сам):
вернуть DataLoader (self.mnist_test, batch_size = 64)
Метод prepare_data также является хорошим местом для любой обработки данных, которая должна выполняться только один раз (например: загрузить или токенизировать и т. д.).
Примечание
Lightning вставляет правильный DistributedSampler для распределенного обучения. Не нужно добавлять себя!
Теперь мы можем обучать LightningModule на TPU, ничего больше не делая!
модель = LitMNIST () trainer = Тренер (num_tpu_cores = 8) тренер.подходит (модель)
Теперь вы увидите, что ядра TPU загружаются.
Обратите внимание, что эпоха НАМНОГО быстрее!
Гиперпараметры
Обычно мы не привязываем значения к модели жестко. Обычно мы используем командную строку для
изменить сеть.
Обычно мы используем командную строку для
изменить сеть.
из argparse import ArgumentParser
parser = ArgumentParser ()
# параметризуем сеть
parser.add_argument ('- layer_1_dim', type = int, по умолчанию = 128)
parser.add_argument ('- layer_2_dim', type = int, по умолчанию = 256)
парсер.add_argument ('- размер_пакета', type = int, по умолчанию = 64)
args = parser.parse_args ()
Теперь мы можем параметризовать LightningModule.
класс LitMNIST (pl.LightningModule):
def __init __ (self, hparams):
super (LitMNIST, self) .__ init __ ()
self.hparams = hparams
self.layer_1 = torch.nn.Linear (28 * 28, hparams.layer_1_dim)
self.layer_2 = torch.nn.Linear (hparams.layer_1_dim, hparams.layer_2_dim)
self.layer_3 = torch.nn.Linear (hparams.layer_2_dim, 10)
def вперед (self, x):
...
def train_dataloader (сам):
...
вернуть DataLoader (mnist_train, batch_size = self.hparams.batch_size)
def configure_optimizers (самостоятельно):
вернуть Адама (self. parameters (), lr = self.hparams.learning_rate)
hparams = parse_args ()
model = LitMNIST (hparams)
 parameters (), lr = self.hparams.learning_rate)
hparams = parse_args ()
model = LitMNIST (hparams)
parameters (), lr = self.hparams.learning_rate)
hparams = parse_args ()
model = LitMNIST (hparams)
Примечание
Бонус! если (hparams) находится в вашем модуле, Lightning сохранит его в контрольной точке и восстановит ваш модель, использующая именно эти параметры.
И мы также можем добавить все флаги, доступные в трейнере, в Argparser.
# добавить все доступные параметры трейнера в ArgParser parser = pl.Trainer.add_argparse_args (парсер) args = parser.parse_args ()
И теперь вы можете начать свою программу с
# теперь можно использовать любой тренерский флаг $ python main.py --num_nodes 2 --gpus 8
Полное руководство по использованию гиперпараметров можно найти в документации по гиперпараметрам.
Подтверждение
В большинстве случаев мы прекращаем обучение модели, когда производительность при проверке разделение данных достигает минимума.
Так же, как training_step , мы можем определить validation_step для проверки любых
метрики, которые нам важны, генерируют образцы или добавляют больше в наши журналы.
для эпох в эпохах:
для партии в данных:
# ...
# поезд
# проверить
выходы = []
для партии в val_data:
x, y = партия # шаг_проверки
y_hat = model (x) # validation_step
loss = loss (y_hat, x) # шаг_проверки
выходы.append ({'val_loss': loss}) # validation_step
full_loss = outputs.mean () # validation_epoch_end
Так как validation_step обрабатывает один пакет, в Lightning у нас также есть метод validation_epoch_end , который позволяет вычислять статистика по полному набору данных после эпохи данных валидации, а не только по партии.
Кроме того, мы определяем метод val_dataloader , который сообщает тренеру, какие данные использовать для проверки.Обратите внимание, что мы разделили разделение MNIST на поезд, проверка. Мы также должны убедиться, что разбиение образца в методе train_dataloader .
класс LitMNIST (pl.LightningModule):
def validation_step (self, batch, batch_idx):
x, y = партия
logits = self. forward (х)
потеря = F.nll_loss (логиты, y)
return {'val_loss': loss}
def validation_epoch_end (self, выходы):
avg_loss = torch.stack ([x ['val_loss'] для x в выходных данных]). mean ()
tensorboard_logs = {'val_loss': avg_loss}
вернуть {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
def val_dataloader (сам):
преобразовать = преобразовывает.Составить ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
_, mnist_val = random_split (mnist_train, [55000, 5000])
mnist_val = Загрузчик данных (mnist_val, batch_size = 64)
вернуть mnist_val
 forward (х)
потеря = F.nll_loss (логиты, y)
return {'val_loss': loss}
def validation_epoch_end (self, выходы):
avg_loss = torch.stack ([x ['val_loss'] для x в выходных данных]). mean ()
tensorboard_logs = {'val_loss': avg_loss}
вернуть {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
def val_dataloader (сам):
преобразовать = преобразовывает.Составить ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
_, mnist_val = random_split (mnist_train, [55000, 5000])
mnist_val = Загрузчик данных (mnist_val, batch_size = 64)
вернуть mnist_val
forward (х)
потеря = F.nll_loss (логиты, y)
return {'val_loss': loss}
def validation_epoch_end (self, выходы):
avg_loss = torch.stack ([x ['val_loss'] для x в выходных данных]). mean ()
tensorboard_logs = {'val_loss': avg_loss}
вернуть {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
def val_dataloader (сам):
преобразовать = преобразовывает.Составить ([transforms.ToTensor (),
transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = True, download = False,
преобразовать = преобразовать)
_, mnist_val = random_split (mnist_train, [55000, 5000])
mnist_val = Загрузчик данных (mnist_val, batch_size = 64)
вернуть mnist_val
Опять же, мы только что организовали обычный код PyTorch в два этапа: метод validation_step , который
работает с одним пакетом и методом validation_epoch_end для вычисления статистики по всем пакетам.
Если у вас определены эти методы, Lightning вызовет их автоматически. Теперь мы можем тренироваться при проверке проверочного набора.
из трейнера импорта pytorch_lightning model = LitMNIST () trainer = Тренер (num_tpu_cores = 8) trainer.fit (модель)
Возможно, вы заметили, что в журнале записаны слова Проверка работоспособности . Это потому, что Lightning запускает 5 пакетов проверки перед началом обучения. Это своего рода модульный тест, чтобы убедиться, что если у вас есть ошибка в цикле проверки вам не придется ждать целую эпоху, чтобы выяснить это.
Примечание
Lightning отключает градиенты, переводит модель в режим оценки и делает все необходимое для проверки.
Тестирование
После того, как наше исследование закончено и мы собираемся опубликовать или развернуть модель, мы обычно хотим выяснить
как это будет распространяться в «реальном мире». Для этого мы используем разбивку данных для тестирования.
Так же, как цикл проверки, мы определяем точно такие же шаги для тестирования:
test_step
test_epoch_end
test_dataloader
класс ЛитМНИСТ (пл.LightningModule):
def test_step (self, batch, batch_idx):
x, y = партия
logits = self.forward (х)
потеря = F.nll_loss (логиты, y)
return {'val_loss': loss}
def test_epoch_end (self, выходы):
avg_loss = torch.stack ([x ['val_loss'] для x в выходных данных]). mean ()
tensorboard_logs = {'val_loss': avg_loss}
вернуть {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
def test_dataloader (сам):
transform = transforms.Compose ([transforms.ToTensor (), transforms.Normalize ((0.1307,), (0.3081,))])
mnist_train = MNIST (os.getcwd (), train = False, download = False, transform = transform)
_, mnist_val = random_split (mnist_train, [55000, 5000])
mnist_val = Загрузчик данных (mnist_val, batch_size = 64)
вернуть mnist_val
Однако, чтобы убедиться, что набор тестов не используется случайно, Lightning имеет отдельный API для запуска тестов.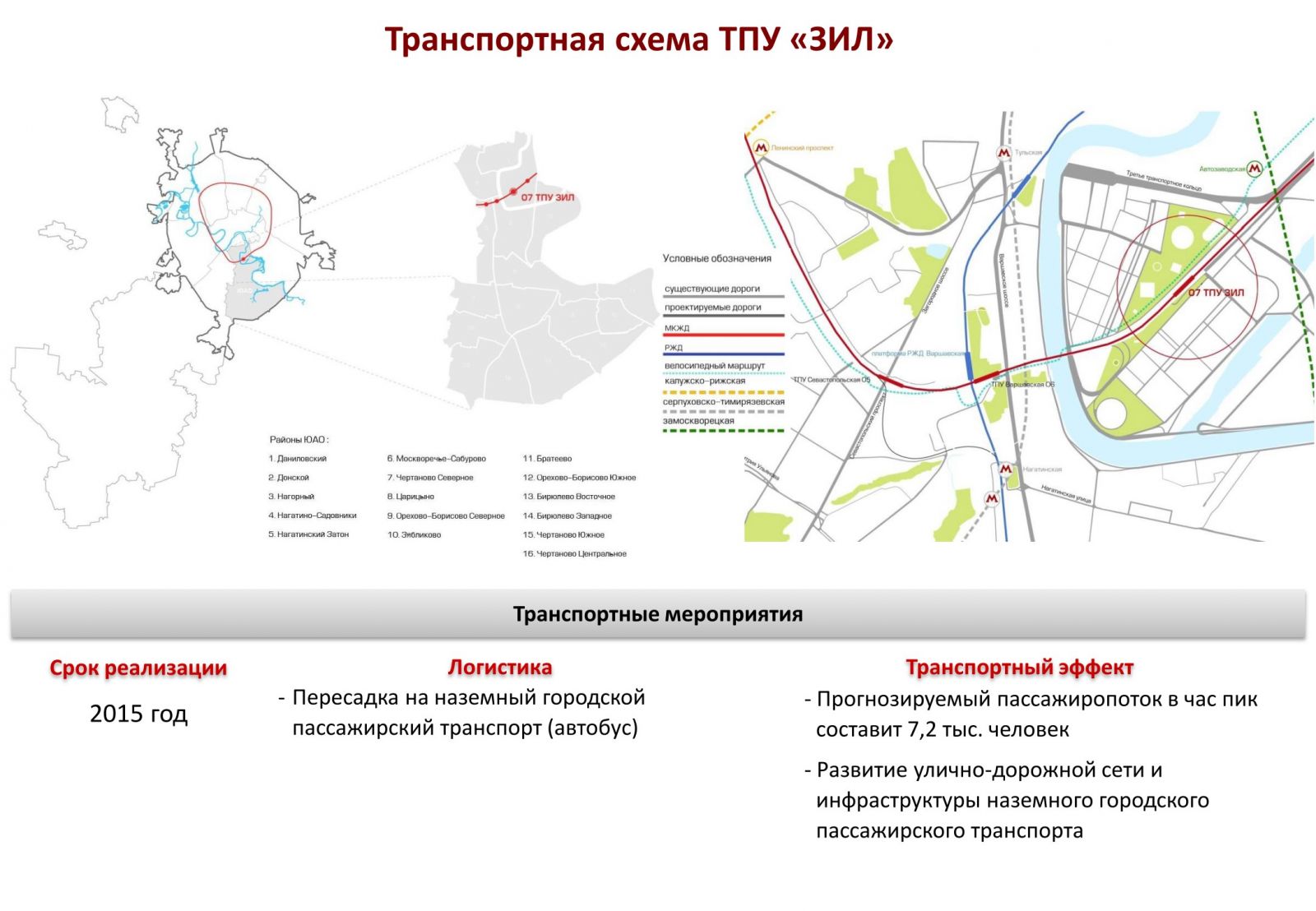 После обучения модели просто вызовите .test () .
После обучения модели просто вызовите .test () .
из трейнера импорта pytorch_lightning model = LitMNIST () trainer = Тренер (num_tpu_cores = 8) тренер.подходит (модель) # запустить тестовый набор trainer.test ()
Ушел:
------------------------------------------------- -------------
РЕЗУЛЬТАТЫ ТЕСТА
{'test_loss': tensor (1.1703, device = 'cuda: 0')}
-------------------------------------------------- ------------
Вы также можете запустить тест из сохраненной модели молнии
model = LitMNIST.load_from_checkpoint (ПУТЬ) trainer = Тренер (num_tpu_cores = 8) trainer.test (модель)
Примечание
Lightning отключает градиенты, переводит модель в режим оценки и делает все необходимое для тестирования.
Предупреждение
.test () еще не работает на TPU. Мы работаем над решением проблем, связанных с многопроцессорностью.
Прогнозирование
Опять же, LightningModule точно такой же, как и модуль PyTorch. Это означает, что вы можете загрузить его
и использовать его для предсказания.
Это означает, что вы можете загрузить его
и использовать его для предсказания.
model = LitMNIST.load_from_checkpoint (ПУТЬ) x = torch.Tensor (1, 1, 28, 28) out = модель (x)
На первый взгляд кажется, что вперед и training_step похожи.Как правило, мы хотим убедиться, что мы хотим, чтобы модель делала то, что происходит в вперед . тогда как training_step скорее всего переадресует внутри.
Классификатор MNIST (pl.LightningModule):
def вперед (self, x):
batch_size, каналы, ширина, высота = x.size ()
x = x.view (размер_пакета, -1)
x = self.layer_1 (x)
х = torch.relu (х)
x = self.layer_2 (x)
х = torch.relu (х)
x = self.layer_3 (x)
x = torch.log_softmax (x, dim = 1)
вернуть х
def training_step (self, batch, batch_idx):
x, y = партия
logits = self.вперед (x)
потеря = F.nll_loss (логиты, y)
обратные потери
модель = MNISTClassifier () x = mnist_image () logits = модель (x)
В этом случае мы установили эту LightningModel для прогнозирования логитов. Но мы также можем сделать так, чтобы он предсказывал карты функций:
Но мы также можем сделать так, чтобы он предсказывал карты функций:
класс MNISTRпредставитель (pl.LightningModule):
def вперед (self, x):
batch_size, каналы, ширина, высота = x.size ()
x = x.view (размер_пакета, -1)
x = self.layer_1 (x)
x1 = torch.relu (x)
x = себя. слой_2 (x1)
x2 = фонарик.relu (x)
x3 = self.layer_3 (x2)
return [x, x1, x2, x3]
def training_step (self, batch, batch_idx):
x, y = партия
выход, l1_feats, l2_feats, l3_feats = self.forward (x)
logits = torch.log_softmax (out, dim = 1)
ce_loss = F.nll_loss (логиты, y)
потеря = perceptual_loss (l1_feats, l2_feats, l3_feats) + ce_loss
обратные потери
модель = MNISTRepresentator.load_from_checkpoint (ПУТЬ) x = mnist_image () feature_maps = модель (x)
Или, может быть, у нас есть модель, которую мы используем для создания поколения
класс LitMNISTDreamer (пл.LightningModule):
def вперед (self, z):
imgs = self. decoder (z)
вернуть imgs
def training_step (self, batch, batch_idx):
x, y = партия
представление = self.encoder (x)
imgs = self.forward (представление)
потеря = perceptual_loss (imgs, x)
обратные потери
 decoder (z)
вернуть imgs
def training_step (self, batch, batch_idx):
x, y = партия
представление = self.encoder (x)
imgs = self.forward (представление)
потеря = perceptual_loss (imgs, x)
обратные потери
decoder (z)
вернуть imgs
def training_step (self, batch, batch_idx):
x, y = партия
представление = self.encoder (x)
imgs = self.forward (представление)
потеря = perceptual_loss (imgs, x)
обратные потери
model = LitMNISTDreamer.load_from_checkpoint (PATH) z = sample_noise () created_imgs = модель (z)
Как вы разделите то, что идет в вперед против training_step , зависит от того, как вы хотите использовать эту модель для предсказание.
Расширяемость
Хотя Lightning делает все очень простым, он не жертвует гибкостью или контролем. Lightning предлагает несколько способов управления состоянием обучения.
Обучение отменяет
Любая часть цикла обучения, проверки и тестирования может быть изменена. Например, если вы хотите выполнить свой обратный проход, вы бы переопределили реализация по умолчанию
def назад (self, use_amp, loss, optimizer):
если use_amp:
с усилителем. scale_loss (потеря, оптимизатор) как scaled_loss:
scaled_loss.backward ()
еще:
loss.backward ()
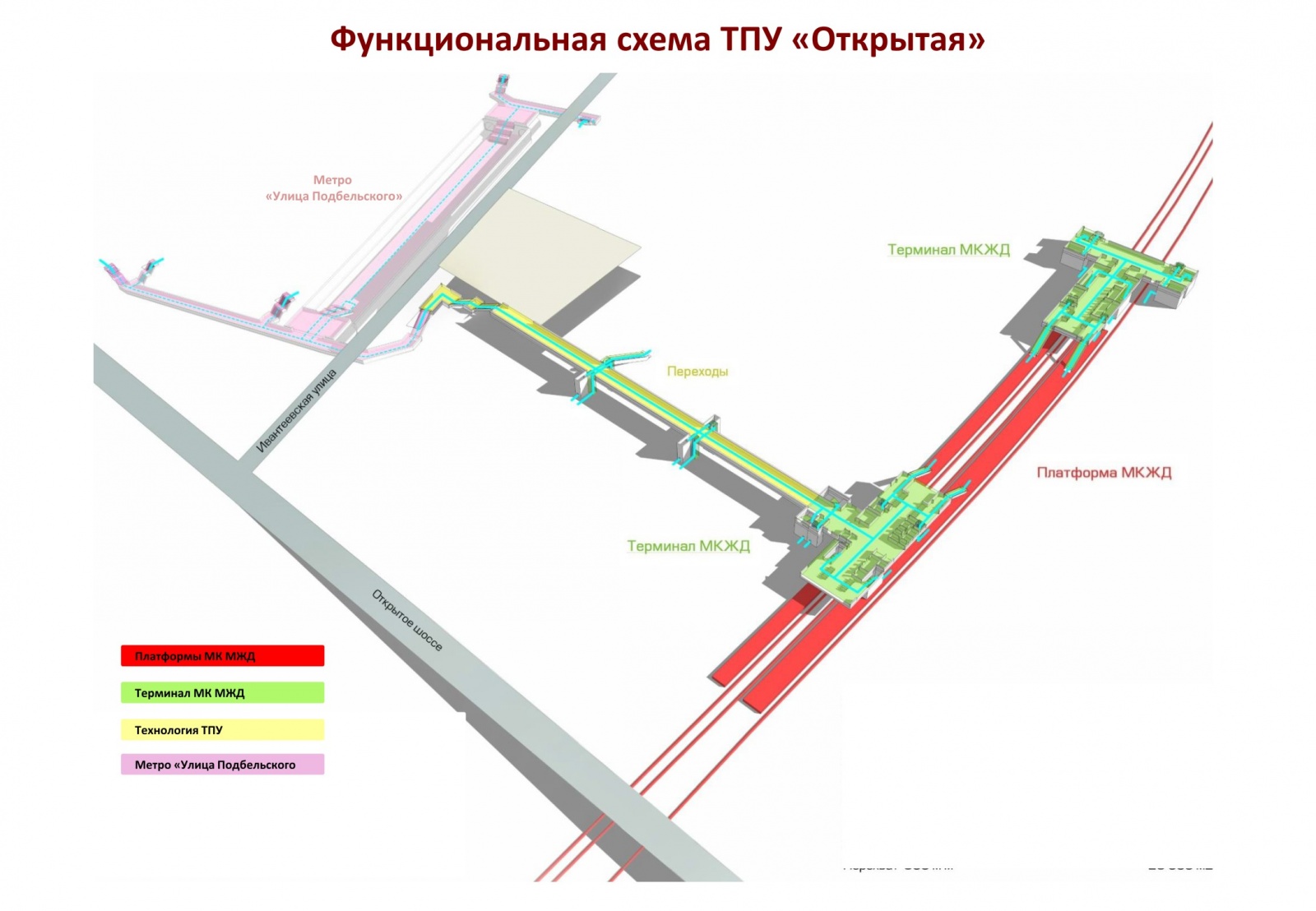 scale_loss (потеря, оптимизатор) как scaled_loss:
scaled_loss.backward ()
еще:
loss.backward ()
scale_loss (потеря, оптимизатор) как scaled_loss:
scaled_loss.backward ()
еще:
loss.backward ()
Со своим
класс LitMNIST (pl.LightningModule):
def backward (self, use_amp, loss, optimizer):
# делаем собственный путь назад
loss.backward (keep_graph = True)
Или, если вы хотите инициализировать ddp другим способом, нежели стандартный
def configure_ddp (self, model, device_ids):
# Lightning DDP просто перенаправляет на test_step, val_step и т. Д...
model = LightningDistributedDataParallel (
модель,
device_ids = device_ids,
find_unused_parameters = Верно
)
модель возврата
вы можете сделать сами:
класс LitMNIST (pl.LightningModule):
def configure_ddp (self, model, device_ids):
model = Horovod (модель)
# model = Луч (модель)
модель возврата
Таким образом настраивается каждая часть обучения.
Полный список можно найти на сайте lightningModule.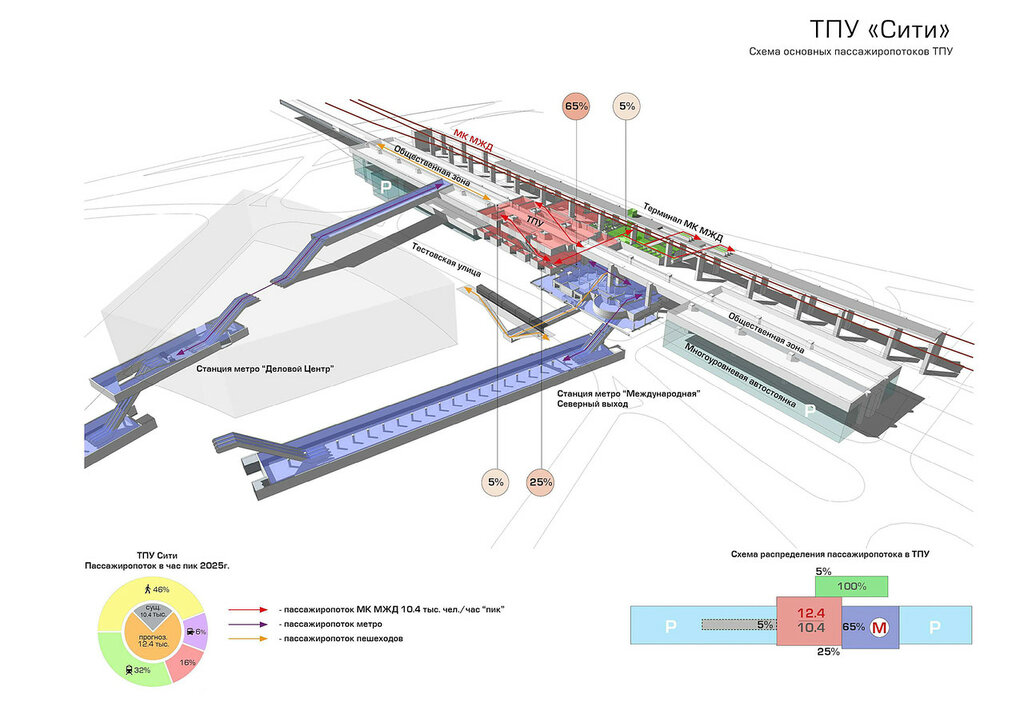
Обратный звонок
Другой способ добавить произвольную функциональность — добавить собственный обратный вызов. для крючков, которые могут вас заинтересовать
импортировать pytorch_lightning как pl
класс MyPrintingCallback (pl.Перезвоните):
def on_init_start (сам, трейнер):
print ('Запускаем трейнер!')
def on_init_end (сам, тренер):
print ('трейнер запущен сейчас')
def on_train_end (сам, тренер, pl_module):
print ('сделай что-нибудь, когда обучение закончится')
И передайте обратные вызовы в трейнер
трейнер (callbacks = [MyPrintingCallback ()])
Примечание
См. Полный список из 12+ хуков в документации обратного вызова
Дочерние модули
Исследовательские проекты, как правило, тестируют разные подходы к одному и тому же набору данных.Это очень легко сделать в Lightning с наследованием.
Например, представьте, что теперь мы хотим обучить автоэнкодер использовать его в качестве средства извлечения признаков для изображений MNIST. Напомним, что LitMNIST уже определяет всю загрузку данных и т.д.
эти изменения в модели Autoencoder включают этапы инициализации, пересылки, обучения, проверки и тестирования.
Напомним, что LitMNIST уже определяет всю загрузку данных и т.д.
эти изменения в модели Autoencoder включают этапы инициализации, пересылки, обучения, проверки и тестирования.
(torch.nn.Module):
...
класс AutoEncoder (LitMNIST):
def __init __ (сам):
self.encoder = Кодировщик ()
я.decoder = Декодер ()
def вперед (self, x):
сгенерировано = self.decoder (x)
def training_step (self, batch, batch_idx):
x, _ = партия
представление = self.encoder (x)
x_hat = self.forward (представление)
потеря = MSE (x, x_hat)
обратные потери
def validation_step (self, batch, batch_idx):
вернуть self._shared_eval (batch, batch_idx, 'val'):
def test_step (self, batch, batch_idx):
вернуть self._shared_eval (batch, batch_idx, 'test'):
def _shared_eval (self, batch, batch_idx, prefix):
x, y = партия
представление = себя.кодировщик (x)
x_hat = self. forward (представление)
потеря = F.nll_loss (логиты, y)
return {f '{prefix} _loss': loss}
 forward (представление)
потеря = F.nll_loss (логиты, y)
return {f '{prefix} _loss': loss}
forward (представление)
потеря = F.nll_loss (логиты, y)
return {f '{prefix} _loss': loss}
и мы можем обучить это с помощью того же тренажера
autoencoder = Автоэнкодер () трейнер = Тренер () trainer.fit (автоэнкодер)
И помните, что метод forward — это определение практического использования LightningModule. В этом случае мы хотим использовать AutoEncoder для извлечения представлений изображений
some_images = факел.Тензор (32, 1, 28, 28) представления = автоэнкодер (some_images)
Трансферное обучение
Использование предварительно обученных моделей
Иногда мы хотим использовать LightningModule в качестве предварительно обученной модели. Это нормально, потому что Модуль LightningModule — это просто torch.nn.Module !
Примечание
Помните, что pl.LightningModule ИМЕННО является torch.nn.Module, но с большими возможностями.
Давайте использовать AutoEncoder в качестве средства извлечения функций в отдельной модели.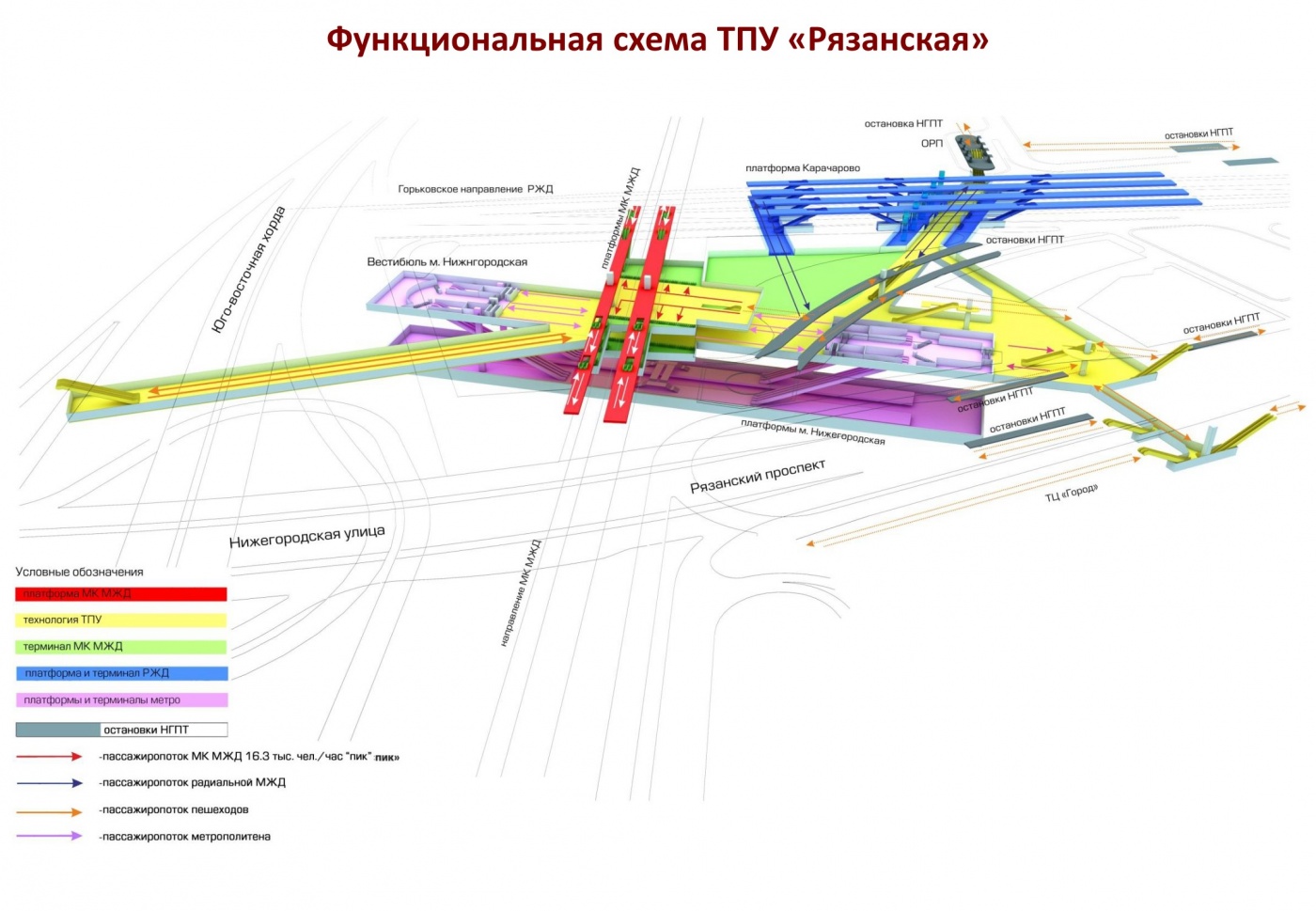
(torch.nn.Module):
...
класс AutoEncoder (pl.LightningModule):
def __init __ (сам):
self.encoder = Кодировщик ()
self.decoder = Декодер ()
класс CIFAR10Classifier (pl.LightingModule):
def __init __ (сам):
# запускаем предварительно обученный LightningModule
self.feature_extractor = AutoEncoder.load_from_checkpoint (ПУТЬ)
self.feature_extractor.freeze ()
# автоэнкодер выводит 100-мерное представление, а CIFAR-10 имеет 10 классов
я.classifier = nn.Linear (100, 10)
def вперед (self, x):
представления = self.feature_extractor (x)
x = self.classifier (представления)
...
Мы использовали наш предварительно обученный Autoencoder (LightningModule) для обучения передачи!
Пример: Imagenet (компьютерное зрение)
импортировать torchvision.models как модели
класс ImagenetTranferLearning (pl.LightingModule):
def __init __ (сам):
# запускаем предварительно обученную повторную сеть
num_target_classes = 10
я. feature_extractor = model.resnet50 (
pretrained = True,
num_classes = num_target_classes)
self.feature_extractor.eval ()
# использовать предварительно обученную модель для классификации cifar-10 (10 классов изображений)
self.classifier = nn.Linear (2048, num_target_classes)
def вперед (self, x):
представления = self.feature_extractor (x)
x = self.classifier (представления)
...
 feature_extractor = model.resnet50 (
pretrained = True,
num_classes = num_target_classes)
self.feature_extractor.eval ()
# использовать предварительно обученную модель для классификации cifar-10 (10 классов изображений)
self.classifier = nn.Linear (2048, num_target_classes)
def вперед (self, x):
представления = self.feature_extractor (x)
x = self.classifier (представления)
...
feature_extractor = model.resnet50 (
pretrained = True,
num_classes = num_target_classes)
self.feature_extractor.eval ()
# использовать предварительно обученную модель для классификации cifar-10 (10 классов изображений)
self.classifier = nn.Linear (2048, num_target_classes)
def вперед (self, x):
представления = self.feature_extractor (x)
x = self.classifier (представления)
...
Finetune
Модель= ImagenetTranferLearning () трейнер = Тренер () тренер.подходит (модель)
И используйте его для прогнозирования интересующих вас данных
model = ImagenetTranferLearning.load_from_checkpoint (PATH) model.freeze () x = some_images_from_cifar10 () прогнозы = модель (х)
Мы использовали предварительно обученную модель на изображении, точно настроенную на CIFAR-10 для прогнозирования на CIFAR-10.
В неакадемическом мире мы бы точно настроились на крошечном наборе данных, который у вас есть, и предсказали бы на основе вашего набора данных.
Пример: BERT (NLP)
Lightning полностью не зависит от того, что так долго используется для трансферного обучения как это факел .nn.Module подкласс.
Вот модель, в которой используются трансформаторы Huggingface.
из трансформаторов импортных BertModel
класс BertMNLIFinetuner (pl.LightningModule):
def __init __ (сам):
super (BertMNLIFinetuner, сам) .__ init __ ()
self.bert = BertModel.from_pretrained ('bert-base-cased', output_attentions = True)
self.W = nn.Linear (bert.config.hidden_size, 3)
self.num_classes = 3
def forward (self, input_ids, Внимание_mask, token_type_ids):
h, _, attn = self.bert (input_ids = input_ids,
Внимание_mask = внимание_маска,
token_type_ids = token_type_ids)
h_cls = h [:, 0]
logits = self.W (h_cls)
вернуть логиты, attn
Как использовать Google Colab
Если вы хотите создать модель машинного обучения, но говорите, что у вас нет компьютера, который мог бы выдержать такую нагрузку, Google Colab — это платформа для вас. Даже если у вас есть графический процессор или хороший компьютер, создание локальной среды с anaconda и установка пакетов и решение проблем с установкой — это хлопот.
Даже если у вас есть графический процессор или хороший компьютер, создание локальной среды с anaconda и установка пакетов и решение проблем с установкой — это хлопот.
Colaboratory — это бесплатная среда Jupyter для ноутбуков, предоставляемая Google, где вы можете использовать бесплатные графические процессоры и TPU, которые могут решить все эти проблемы.
Начало работы
Чтобы начать работать с Colab, вам сначала нужно войти в свою учетную запись google, затем перейти по этой ссылке https://colab.research.google.com.
Открытие Jupyter Notebook:
При открытии веб-сайта вы увидите всплывающее окно, содержащее следующие вкладки —
ПРИМЕРЫ: Содержат несколько записных книжек Jupyter с различными примерами.
НЕДАВНИЕ: Ноутбук Jupyter, с которым вы недавно работали.
GOOGLE DRIVE: Блокнот Jupyter на вашем Google Диске.
GITHUB: Вы можете добавить записную книжку Jupyter из своего GitHub, но сначала вам нужно подключить Colab к GitHub.
ЗАГРУЗИТЬ: Загрузить из локального каталога.

В противном случае вы можете создать новую записную книжку Jupyter , щелкнув New Python3 Notebook или New Python2 Notebook в правом нижнем углу.
Описание записной книжки:
При создании новой записной книжки будет создан блокнот Jupyter с Untitled0.ipynb и сохраните его на своем диске Google в папке с именем Colab Notebooks . Поскольку это, по сути, блокнот Jupyter, здесь будут работать все команды блокнотов Jupyter. Тем не менее, вы можете обратиться к подробностям в Приступая к работе с Jupyter Notebook.
Давайте поговорим о том, чем здесь отличается.
Изменить среду выполнения:
Щелкните раскрывающееся меню «Время выполнения» . Выберите «Изменить тип среды выполнения» . Выберите python2 или 3 из раскрывающегося меню «Тип среды выполнения» .
Использовать графический процессор и TPU:
Щелкните раскрывающееся меню «Время выполнения» .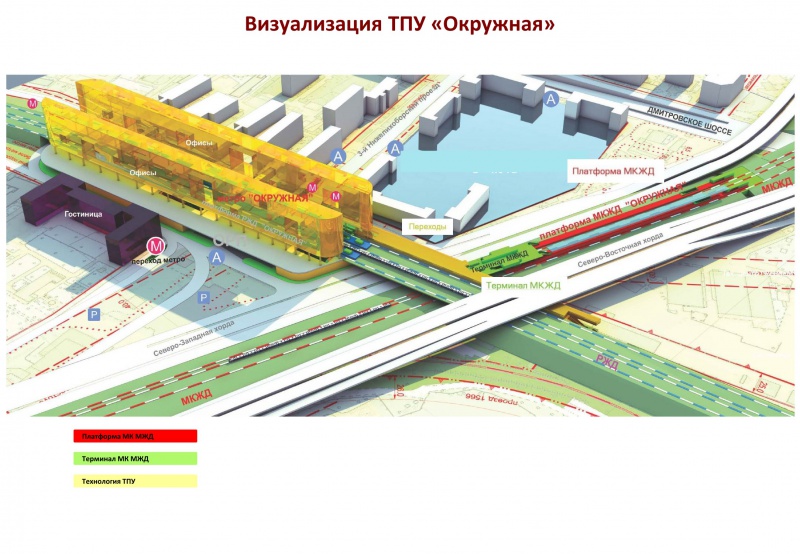 Выберите «Изменить тип среды выполнения» . Теперь выберите что угодно (GPU, CPU, None) в раскрывающемся меню «Аппаратный ускоритель» .
Выберите «Изменить тип среды выполнения» . Теперь выберите что угодно (GPU, CPU, None) в раскрывающемся меню «Аппаратный ускоритель» .
Проверить графический процессор:
|
Если подключен графический процессор, будет выведено следующее —
'/ устройство: GPU: 0'
В противном случае он будет выводить после
''
Проверить TPU:
|
Если подключен графический процессор, он будет выводить следующие
Подключен к ТПУ
В противном случае он будет выводить после
Не подключен к ТПУ
Установить пакеты Python —
Используйте pip для установки любого пакета. Например:
Например:
Клонирование репозиториев GitHub:
Используйте команду git clone . Например:
|
Загрузить файл:
|
Выберите «Выбрать файл» и загрузите нужный файл. Включите сторонние файлы cookie, если они отключены.
Затем вы можете сохранить его во фрейме данных.
|
Загрузить файл путем монтирования Google Диска:
Чтобы смонтировать диск внутри папки «mntDrive», выполните следующее —
|
Затем вы увидите ссылку, нажмите на нее, затем разрешите доступ, скопируйте всплывающий код и вставьте его в поле «Введите код авторизации:».
Теперь, чтобы увидеть все данные на вашем диске Google, вам необходимо выполнить следующее:
|
Иерархия файлов:
Вы также можете просмотреть иерархию файлов, нажав «>» в верхнем левом углу под кнопками управления (CODE, TEXT, CELL).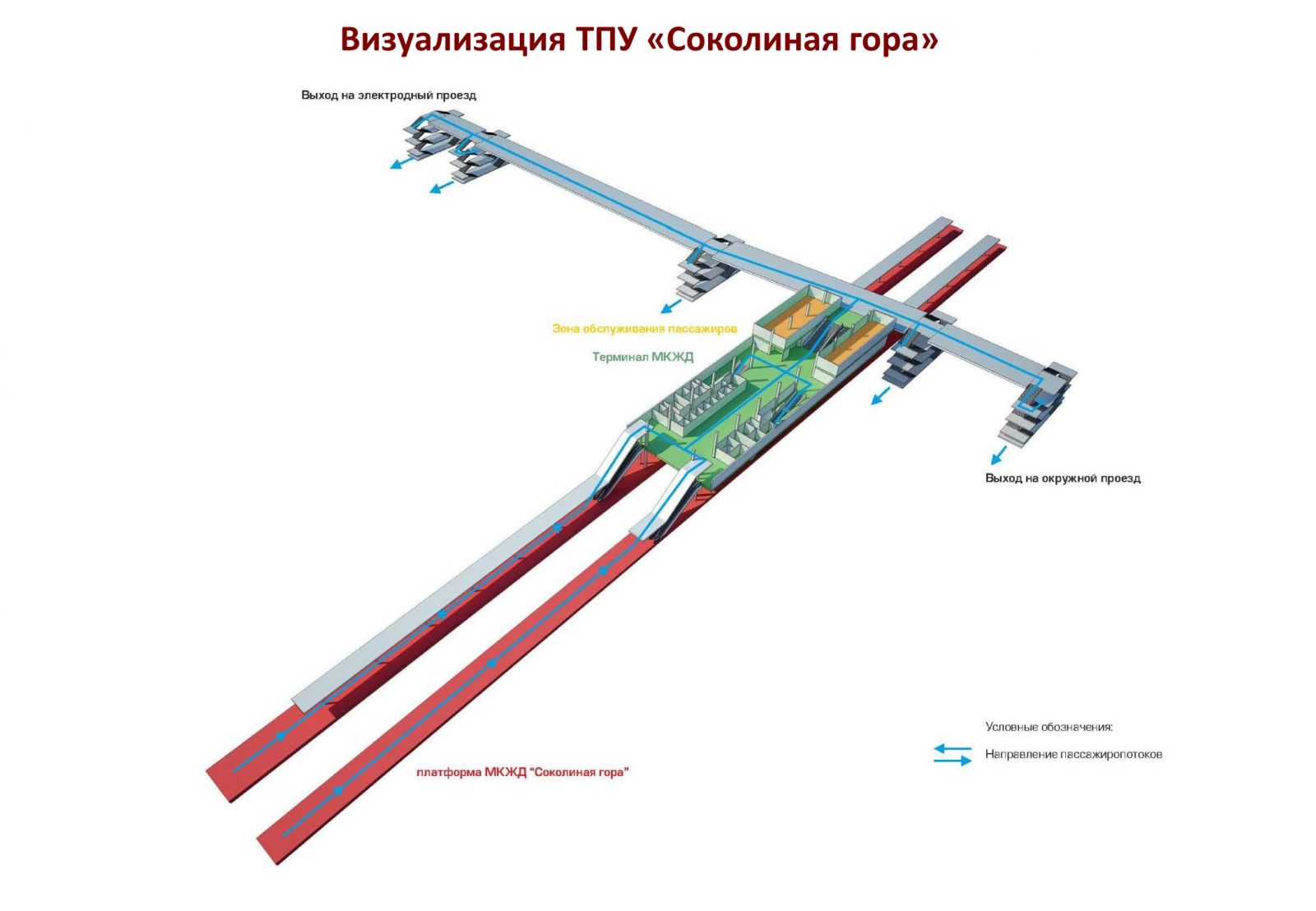
Скачать файлы:
Допустим, вы хотите скачать «имя_файла.csv ». Вы можете скопировать файл на свой диск Google (в папке «данные» вам необходимо создать папку «данные» на диске Google), выполнив следующее:
|
Файл будет сохранен в папке «data» с именем «renamed_file_name.csv». Теперь вы можете скачать прямо оттуда, или вы можете просто открыть иерархию файлов, и щелчок правой кнопкой мыши предоставит возможность загрузки.
Загрузить Jupyter Notebook:
Щелкните «Файл» раскрывающееся меню в верхнем левом углу. Выберите «загрузить .ipynb» или «загрузить .py»
Поделиться записной книжкой Jupyter:
Вы можете предоставить общий доступ к записной книжке, добавив адреса электронной почты других пользователей или создав ссылку для общего доступа.
Как 3D-печать революционизирует обувную промышленность
Обувь, напечатанная на 3D-принтере, может быть легко интегрирована в вашу повседневную жизнь, например, Phits с их стельками, напечатанными на 3D-принтере, являются хорошим примером.Некоторые проекты действительно доступны каждому, и их можно было бы развивать более широко. Персонализированные пары обуви теперь доступны каждому, и в ближайшие годы широкое распространение получит массовая индивидуализация.
Действительно, 3D-печать — отличный способ подобрать обувь, идеально подходящую для вашей ноги. Крупные бренды налаживают партнерские отношения с основными участниками аддитивного производства, такими как HP, и включают процесс 3D-печати в производство некоторых своих моделей. Обувь, напечатанная на 3D-принтере, благодаря таким брендам, как Nike или Adidas, теперь вступает в эру массового производства.
Дизайнеры продолжат работать с 3D-печатью, поскольку она позволяет создавать невероятные дизайны с большой свободой. Например, Зои Цзя-Ю Дай однозначно не собирается отказываться от 3D-печати. Поскольку она интересуется мужской и детской обувью, очень скоро могут быть запущены новые проекты.
Например, Зои Цзя-Ю Дай однозначно не собирается отказываться от 3D-печати. Поскольку она интересуется мужской и детской обувью, очень скоро могут быть запущены новые проекты.
Обувная промышленность больше связана с 3D-печатью, чем вы думаете. Все эти примеры показывают, что есть разные способы создания обуви. Это может быть расширение границ дизайна или изменение методов производства, найдя экологически чистый способ производства, или даже изготовление обуви или стелек на заказ для большего комфорта.Причин для создания 3D-печатной обуви множество, и в ближайшие годы они могут быть расширены!
Хотите начать свой бизнес по 3D-печати в обувной промышленности? Итак, вот наш первый совет: выберите правильное программное обеспечение для 3D. Программное обеспечение для создания идеальной обуви поможет вам начать свой лучший проект.
У вас есть 3D-модель, и вы хотите создать прототип пары обуви или чего-нибудь еще? Вы можете загрузить модель на нашем онлайн-сервисе 3D-печати.