|
Основные математические символы |
Нет |
Часто используемые математические символы, такие как > и < |
|
Греческие буквы |
Строчные буквы |
Строчные буквы греческого алфавита |
|
Прописные буквы |
Прописные буквы греческого алфавита |
|
|
Буквоподобные символы |
Нет |
Символы, которые напоминают буквы |
|
Операторы |
Обычные бинарные операторы |
Символы, обозначающие действия над двумя числами, например + и ÷ |
|
Обычные реляционные операторы |
Символы, обозначающие отношение между двумя выражениями, такие как = и ~ |
|
|
Основные N-арные операторы |
Операторы, осуществляющие действия над несколькими переменными |
|
|
Сложные бинарные операторы |
Дополнительные символы, обозначающие действия над двумя числами | |
|
Сложные реляционные операторы |
Дополнительные символы, обозначающие отношение между двумя выражениями |
|
|
Стрелки |
Нет |
Символы, указывающие направление |
|
Отношения с отрицанием |
Нет |
Символы, обозначающие отрицание отношения |
|
Наборы знаков |
Наборы знаков |
Математический шрифт Script |
|
Готические |
Математический шрифт Fraktur |
|
|
В два прохода |
Математический шрифт с двойным зачеркиванием |
|
|
Геометрия |
Нет |
Часто используемые геометрические символы |
Не удается найти страницу | Autodesk Knowledge Network
 REQUIRED_FIELD}})
REQUIRED_FIELD}}){{l10n_strings.CREATE_NEW_COLLECTION}}*
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}} {{addToCollection.description.length}}/500 {{l10n_strings.TAGS}} {{$item}} {{l10n_strings.PRODUCTS}} {{l10n_strings.DRAG_TEXT}} LANGUAGE}}
{{$select.selected.display}}
LANGUAGE}}
{{$select.selected.display}}{{l10n_strings.AUTHOR_TOOLTIP_TEXT}}
{{$select.selected.display}} {{l10n_strings.CREATE_AND_ADD_TO_COLLECTION_MODAL_BUTTON}} {{l10n_strings.CREATE_A_COLLECTION_ERROR}}Стили формул.
 Реферат, курсовая, диплом на компьютере
Реферат, курсовая, диплом на компьютереЧитайте также
6.2.2. Использование формул
Строка формул
2.
 2.7. Создание формул RPTwin
2.7. Создание формул RPTwin
2.2.7. Создание формул RPTwin RPTwin позволяет преобразовать в формулу любое поле данных. Для этого в диалоге Data Field Properties (см. рис. 2.2.4) следует щелкнуть по кнопке Formula Editor. Возникает диалог Formula Editor (рис. 2.2.10). Рис. 2.2.10. Диалог Formula EditorПо умолчанию в верхнем поле диалога (Formula)
2.2.9. Использование формул RPTwin
2.2.9. Использование формул RPTwin Рассмотрим построение отчета RPTwin по модели процессов, изображенной на рис. 2.2.11. Модель описывает процесс изготовления изделия и имеет три уровня декомпозиции. В ней описаны следующие свойства, определяемые пользователем (UDP):уровень
5.3. Использование формул RPTwin
5. 3. Использование формул RPTwin 5.3.1. Создание формул RPTwin
RPTwin позволяет преобразовать в формулу любое поле данных. Для этого в диалоге Data Field Properties (см. рис. 5.4) следует щелкнуть по кнопке Formula Editor. Возникает диалог Formula Editor (рис. 5.10). Рис.5.10. Диалог Formula EditorПо умолчанию в верхнем
3. Использование формул RPTwin 5.3.1. Создание формул RPTwin
RPTwin позволяет преобразовать в формулу любое поле данных. Для этого в диалоге Data Field Properties (см. рис. 5.4) следует щелкнуть по кнопке Formula Editor. Возникает диалог Formula Editor (рис. 5.10). Рис.5.10. Диалог Formula EditorПо умолчанию в верхнем
5.3.1. Создание формул RPTwin
5.3.1. Создание формул RPTwin RPTwin позволяет преобразовать в формулу любое поле данных. Для этого в диалоге Data Field Properties (см. рис. 5.4) следует щелкнуть по кнопке Formula Editor. Возникает диалог Formula Editor (рис. 5.10). Рис.5.10. Диалог Formula EditorПо умолчанию в верхнем поле диалога (Formula:)
5.3.3. Использование формул RPTwin
5.3.3. Использование формул RPTwin
Рассмотрим построение отчета RPTwin по модели процессов, изображенной на рис. 5.11. Модель описывает процесс изготовления изделия и имеет три уровня декомпозиции. В ней описаны следующие свойства, определяемые пользователем (UDP):уровень
5.11. Модель описывает процесс изготовления изделия и имеет три уровня декомпозиции. В ней описаны следующие свойства, определяемые пользователем (UDP):уровень
Ввод формул
Ввод формул Для ввода формул предназначена специальная панель инструментов Microsoft Equation, которая отображается в окне Word после запуска редактора формул. Принцип работы состоит в следующем: если необходимо ввести простую формулу, нечто вроде х + 4, вы можете просто набрать ее
Редактирование формул
Редактирование формул Редактирование формулы практически не отличается от редактирования обычного текста. Значения полей формулы можно удалять и вводить вместо них другие. Проще всего это сделать, если установить курсор в нужном поле формулы и затем нажать одну из
Форматирование формул
Форматирование формул
Редактор формул позволяет задавать расположение формулы и ее элементов. Для настройки этих параметров предназначены первые пять команд меню Формат, которые используются для горизонтального выравнивания формул и столбцов матриц. Кроме
Для настройки этих параметров предназначены первые пять команд меню Формат, которые используются для горизонтального выравнивания формул и столбцов матриц. Кроме
6.6. Создание формул
6.6. Создание формул Формула является основным средством для анализа данных. С помощью формул можно складывать, умножать и сравнивать данные, а также объединять значения. Формулы подчиняются определенному синтаксису, в который входят знак равенства (=), вычисляемые
Использование формул
Использование формул Перейдем к самой главной функции электронных таблиц – работе с формулами. Именно это отличает электронную таблицу от обычной, набранной в любом текстовом редакторе.Ячейки таблицы могут содержать не только статичные данные, но и результат некоторых
Вставка математических формул
Вставка математических формул
Математические формулы могут содержать греческие буквы, надстрочные и подстрочные символы, знаки корня, интеграла и т. д. Для создания подобных формул в составе Microsoft Office есть специальный редактор формул. Использование этой программы
д. Для создания подобных формул в составе Microsoft Office есть специальный редактор формул. Использование этой программы
Правила ввода формул
Правила ввода формул Как уже отмечалось выше, основное назначение программы Excel – это выполнение расчетов, для чего в ячейки таблиц нужно вводить формулы. Формула – это выражение, по которому Excel выполняет вычисления и отображает результат. При создании формул следует
Строка формул
Строка формул Если со строкой меню и панели инструментов все понятно – работа с этой частью Excel аналогична работе в Word, то строка формул может вызвать некоторые затруднения. Давайте разбираться.Строка формул расположена ниже панели инструментов. В строке формул всегда
Семантические сети: как представить значения слов в виде графа
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели. Вот так выглядит граф для слова «лук»:
Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели. Вот так выглядит граф для слова «лук»:
Расскажем по порядку, что это такое и откуда берется.
Напоминалка: дистрибутивная семантика
«Системный Блокъ» уже рассказывал о том, что современные технологии автоматической обработки текста (даже те, которые пафосно и не всегда заслуженно называют «искусственным интеллектом») опираются на дистрибутивную семантику. В основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах (ср. «полицейский бьет митингующего дубинкой», «омоновец бьет митингующего дубинкой», «полиция разогнала мирный митинг», «омон разогнал мирный митинг»).
Чтобы передать такое знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec (вот здесь мы подробно рассказывали, как это работает). Такие модели при обучении сохраняют знание о частых и редких контекстах слова в виде упорядоченного списка чисел (т.е. в виде вектора — отсюда и «векторные» модели). Благодаря этому семантические расстояния между словами становятся измеримы, и машина, измерив их, понимает: слова полицейский и омоновец похожи (благодаря частому употреблению в похожих контекстах вектора этих слов будут близкими).
Такие модели при обучении сохраняют знание о частых и редких контекстах слова в виде упорядоченного списка чисел (т.е. в виде вектора — отсюда и «векторные» модели). Благодаря этому семантические расстояния между словами становятся измеримы, и машина, измерив их, понимает: слова полицейский и омоновец похожи (благодаря частому употреблению в похожих контекстах вектора этих слов будут близкими).
Как визуализировать семантическую близость?
Как отображать эти семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Один самый простой вариант вы уже видели выше: можно для любого слова просто выдавать столбик ближайших к нему «семантических ассоциатов» (т.е. слов с наиболее похожими семантическими векторами).
Можно ли более наглядно? Один из вариантов — попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество, статистика разрабатывает их последние лет 100.
Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество, статистика разрабатывает их последние лет 100.
К сожалению, такое представление неизбежно теряет часть информации о соотношении векторов. Невозможно превратить, к примеру, 500-мерное пространство в двумерную картинку на плоскости без потерь.
Семантика и сети
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости можно отобразить, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
Сети хороши не только наглядностью, но и тем, что здесь можно частично преодолеть ограничения так называемых контекстно-независимых моделей (word2vec, fastText и мн.других). Такие модели всегда хранят один вектор для любого слова, даже многозначного. В результате получается, что слова с несколькими значениям типа «кисть» или «лук» будут иметь один гибридный вектор. Такой вектор будет тяготеть сразу и к словам, связанным с растениями, огородом, едой, и к разной военно-оружейно-спортивной лексике («стрелы», «колчан», «лучник»). Это серьезная проблема дистрибутивной семантики.
В результате получается, что слова с несколькими значениям типа «кисть» или «лук» будут иметь один гибридный вектор. Такой вектор будет тяготеть сразу и к словам, связанным с растениями, огородом, едой, и к разной военно-оружейно-спортивной лексике («стрелы», «колчан», «лучник»). Это серьезная проблема дистрибутивной семантики.
Сетевая визуализация позволяет отобразить не только самые близкие слова для «лука», но и близость этих самых слов между собой. «Колчан» будет близок «стреле», но не слишком близок «чесноку», поэтому связи между «колчаном» и «чесноком» не отобразится. В результате получается граф с двумя кластерами: один «оружейный», другой — «растительный»:
Видно, что «чеснок» и «репчатый» связаны с луком-растением, но не связаны с оружием.
А вот и код для vec2graph, который позволяет это сделать:
WORD = 'лук_NOUN'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.53, edge=1, sep=True)Как же получается, что не все слова связаны со всеми? Для этого в vec2graph есть полезная опция «порог близости» (threshold). В примере выше если слово входит в топ-8 ближайших семантических ассоциатов, но при этом его близость к «луку» ниже 0,53, оно появится в визуализации как узел сети, но сама такая связь не отобразится. Так происходит со словом «арбалет».
В примере выше если слово входит в топ-8 ближайших семантических ассоциатов, но при этом его близость к «луку» ниже 0,53, оно появится в визуализации как узел сети, но сама такая связь не отобразится. Так происходит со словом «арбалет».
Больше примеров сетевых визуализаций
Молодой
WORD = 'молодой_ADJ'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.7, edge=1, sep=True)При высоком пороге близости (0,7) только «немолодой» и «пожилой» достаточно близки друг другу, чтобы отобразилась связь.
Оранжерея
WORD = 'оранжерея_NOUN'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.6, edge=1, sep=True)«Теплица» связана по смыслу с «оранжереей», но далека от цветов, поэтому между ней и «цветочными» словами связи слабые (в данном случае — меньше 0.6).
Как сделать это самому?
Самая большая радость в том, что сделать это несложно: нужно лишь установить библиотеку vec2graph, скачать предобученную дистрибутивную модель на ваш вкус, а ещё установить несколько зависимостей.
Установка библиотеки и зависимостей:
Удобнее всего делать это с помощью pip. Если работаете в jupyter — можно обратиться к командной строке прямо там с помощью «!»:
! pip3 install --user --upgrade pip # может понадобиться
! pip3 install smart_open --upgrade # может понадобиться
! pip3 install gensim --upgrade # может понадобиться
! pip3 install vec2graph --upgradeИмпорт из vec2graph:
from vec2graph import visualize
from gensim.models.keyedvectors import KeyedVectorsЗаранее создать папку для html-файлов с графами, прописать путь к ней и к дистрибутивной модели:
OUTPUT_DIR = '/Users/aika/Documents/Masters/VIZ/viz_graphs'
MODEL = KeyedVectors.load_word2vec_format('model.bin', binary=True)Использование vec2graph:
Теперь осталось задать слово и параметры, как было выше в подписях к визуализациям:
WORD = 'попугай_NOUN' # нужен pos-тэг или не нужен зависит от того, как слова представлены в модели. visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.62, edge=1, sep=True)
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.62, edge=1, sep=True) visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.62, edge=1, sep=True)
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.62, edge=1, sep=True)depth=0 означает, что будет создан один файл с графом, узлами которого будут слово WORD и его ближайшие соседи. Если увеличивать глубину, то ближайшие слова-соседи исходного запроса тоже распустятся графами в отдельных html-файлах.
topn=8 значит количество слов-соседей для одного слова-запроса.
threshold=0.6 — самое интересное: это минимальное значение косинусной близости, необходимое для прорисовки ребра между словами. По умолчанию этот показатель равен нулю, тогда граф полносвязный, но интереснее всего его регулировать и выяснять, какие слова близки и образуют кластеры, а какие оказываются дальше.
edge=1 отвечает за толщину рёбер.
sep=True означает, что метки частей речи показывать не нужно.
Результат будет выглядеть так:
Теперь вы можете сами исследовать значения слов.
Ссылки
Создатели библиотеки: Алексей Яскевич, Анастасия Лисицына, Тамара Жордания, Надежда Катричева, Елизавета Кузьменко, Андрей Кутузов.
Как поставить ударение в Word над буквой в слове?
В Microsoft Word нету специальной кнопки, которая ставит ударение над буквой в слове, но ее можно сделать самому. Также можно воспользоваться специальными комбинациями клавиш, либо использовать таблицу символов для вставки ударения.
Если вам редко приходится ставить ударение в ворде, то используйте сочетания клавиш 0301 и Alt + X, либо Alt + 769 (подробности в статье ниже).
Если же у вас часто возникает такая необходимость, то лучше сделать специальную кнопку на панели инструментов в Word, которая одним кликом будет ставить ударение.
Способы поставить ударение в Word
Комбинация клавиш №1
1 Ставим курсор сразу после буквы, над которой нужно поставить ударение.
2 Затем прямо в слове печатаем 0301, после чего нажимаем сочетание клавиш Alt + X.
Комбинация клавиш №2
Внимание! Этот способ сработает только, если у вас стандартная клавиатура у которой присутствуют дополнительные цифровые клавиши справа.
1 Устанавливаем курсор после нужной буквы.
2 На клавиатуре удерживаем Alt, а на правой дополнительной клавиатуре по очереди нажимаем клавиши 7 6 9.
Таблица символов
Не самый удобный способ поставить ударение, но тоже имеет место быть.
1 Открываем таблицу символов по адресу: Вставка -> Символ -> Другие символы.
2 В окошке Код знака указываем номер символа, который отвечает за ударение – 0301, нажимаем Вставить. Курсор при этом должен стоять после буквы, для которой ставим ударение.
Создание кнопки через макросы
Здесь мы создадим кнопку, чтобы вставлять ударения в 1 клик.
1 Открываем меню записи макросов: Вид -> Макросы -> Запись макроса.
2 Выбираем имя и назначаем макрос для кнопки.
3 Отмечаем созданный макрос и нажимаем Добавить.
4 На этом шаге можно выбрать свою иконку для кнопки через меню Изменить, далее нажимаем Ok.
5 Теперь печатаем 0301 и нажимаем Alt + X.
6 Заканчиваем запись: Вид -> Макросы -> Остановить запись.
После всех этих манипуляций должна появится кнопка в левом верхнем меню.
Как в документ Visio вставлять специальные символы — Microsoft Office для женщин
В некоторых случаях, особенно при подготовке технических или научных материалов, возникает необходимость использовать в тексте специальные символы, например, обозначение градуса («°») или знак «плюс-минус» («±»). Многие современные шрифты имеют в своем составе эти и другие специальные символы, однако, в большинстве случаев, для них не находится соответствующих клавиш на клавиатуре. Для того чтобы поместить в текст символ, который вы затрудняетесь набрать при помощи клавиатуры, воспользуйтесь командой Вставка → Символ. При вызове этой команды на экране появится окно, представленное на рис. 5.19.
При помощи раскрывающегося списка Шрифт выберите начертание символов, с которым вы хотите работать. После этого, просматривая таблицу символов, выделите нужный знак при помощи мыши и нажмите кнопку Вставить. После того, как вы выделите в таблице интересующий вас символ, в нижней части окна будет выведено его краткое описание и код. Зная этот код, можно быстро ввести символ при помощи клавиатуры — достаточно набрать десятичный номер на цифровой клавиатуре, удерживая нажатой клавишу Alt. Например, для ввода символа «±» нужно набрать код Alt+0177.
После этого, просматривая таблицу символов, выделите нужный знак при помощи мыши и нажмите кнопку Вставить. После того, как вы выделите в таблице интересующий вас символ, в нижней части окна будет выведено его краткое описание и код. Зная этот код, можно быстро ввести символ при помощи клавиатуры — достаточно набрать десятичный номер на цифровой клавиатуре, удерживая нажатой клавишу Alt. Например, для ввода символа «±» нужно набрать код Alt+0177.
Рис. 5.19. При помощи окна команды Вставка → Символ вы можете выбрать и добавить в текст редко используемые символы, отсутствующие на стандартной клавиатуре
Обратите внимание — вводить с клавиатуры следует номер в десятичной системе счисления, в то время как в окне вставки символа по умолчанию отображаются шестнадцатеричные значения. Раскрывающийся список, расположенный в нижнем правом углу окна, позволяет выбрать режим представления кодов символов в десятичной системе исчисления, однако, в системах, отличных от Юникод (работающем в шестнадцатеричной системе) набор доступных символов может быть сильно ограничен.
Если известен шестнадцатеричный код символа, можно перевести его в десятичную систему, например, при помощи программы Калькулятор, традиционно входящей в состав Windows. Для корректного распознавания набранного вами кода может потребоваться ввести первый, «ведущий» 0 — Alt+0177 вместо Alt+177.
Как поставить символ (знак) градуса
Знак градуса (°) — символ, используемый для обозначения размера температуры и угла.
Значок градуса ставится сразу после числового обозначения величины угла или температуры без всякого пробела. Если за ним стоит сокращённое обозначение шкалы (имеется ввиду такие как: C — Цельсий, K — Кельвин, F — Фаренгейт), то эти сокращения отбиваются от знака градуса на 2 типографских пункта. Также следует помнить, что цифру со знаком градуса и температурной шкалой следует набирать со знаком + или —, а не без него.
Сегодня +26° C
Хранить при температуре до —7° С
Градус °
На клавиатуре клавиши с градусом нет, поэтому для его написания применяются различные методы, в том числе:
- символы в Word,
- таблица символов,
- сочетания клавиш на клавиатуре,
- градус на Mac OS,
- градус на iPhone и iPad,
- вёрстка °
Градус в Word
При работе в ворде устанавливаем курсор в нужное место → вкладка Вставка → Символ → Другие символы… (если знака градуса нет в готовом наборе) → Набор: дополнительная латиница-1. Выделяем символ градуса → Вставить.
Выделяем символ градуса → Вставить.
Программа запомнит ваш выбор. В следующий раз достаточно будет открыть набор ранее использованных символов.
Таблица символов
Коллекция символов есть не только в ворде. В Windows существует своя таблица с символами — программа charmap.exe. Для её вызова нажимаем Пуск → Выполнить → charmap.exe → ОК.
В окне таблицы найдите значок градуса. Выделите его, нажмите кнопку Выбрать и Копировать.
Остаётся лишь вставить символ в нужное место сочетанием клавиш Ctrl и V.
Сочетания клавиш на клавиатуре
Для написания символа градуса в Windows следует одной рукой нажать клавишу Alt и, удерживая её, другой рукой ввести на клавиатуре цифры 0 1 7 6.
Отпустите Alt — получится знак градуса цельсия.
Для ноутбуков, у которых на клавиатуре нет цифрового блока, нужно дополнительно нажать клавишу Fn и использовать функциональные клавиши с цифрами.
Mac OS
На компьютерах Mac OS знак градуса можно вставить, нажав клавиши ⌥ + 0.
Знак градуса на iPhone и iPad
Нажмите и удерживайте клавишу с цифрой 0 — появится дополнительный символ °.
Код °
// html
°
или
°
// css
span
{
content: "\00B0";
}
Как создавать векторы в Word
Word предлагает различные способы создания вектора в документе:
| Использование Equation – мы настоятельно рекомендуем этот способ! | |
| Использование Автозамены для математических расчетов | |
| Использование диалогового окна Symbol |
I. Использование уравнения:
Этот способ идеально подходит, если вам не нужно заботиться о формате и совместимости с предыдущими версиями Microsoft Office (рекомендуемый подход для физических и математических наук, требующий большого количества математических операций в тексте с согласованными шрифтами для всех уравнений и символов) :
1. В абзаце, куда вы хотите вставить вектор , затем щелкните Alt + = , чтобы вставить блок верховой езды:
В абзаце, куда вы хотите вставить вектор , затем щелкните Alt + = , чтобы вставить блок верховой езды:
2. В блоке верховой езды введите величину вектора и выберите ее. Это может быть одна буква, несколько букв или даже выражение.
Например:.
3. На вкладке Equation в группе Structures нажмите кнопку Accent :
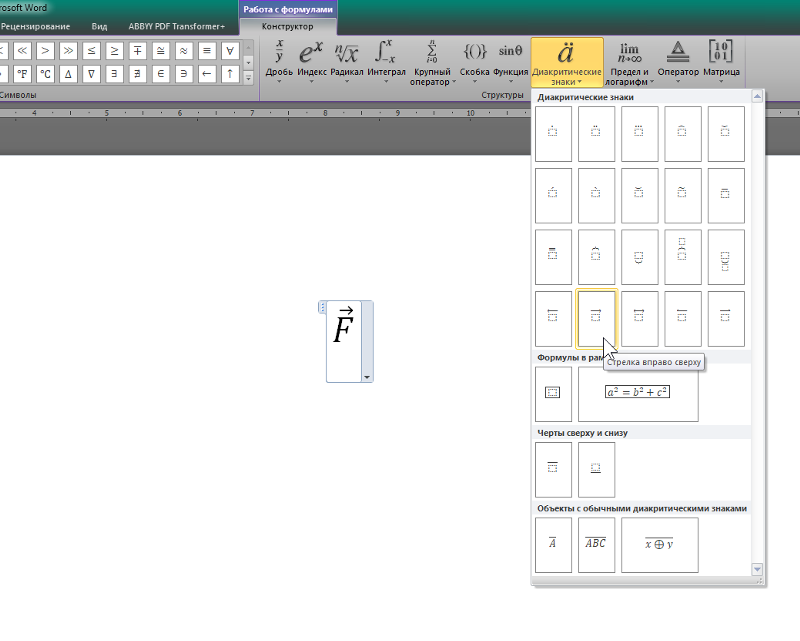
В списке Accent выберите Bar или Стрелка вправо вверх :
илиПримечание : Если вы хотите продолжить работу с этим уравнением, дважды щелкните стрелку вправо, чтобы выйти из поля под вектором: & RightArrow; &Правая стрелка; .Итак, чтобы продолжить работу с уравнением, в нем не должно быть выбранных данных:
II. Использование автозамены для математики:
Когда вы работаете с большим количеством документов и часто, нужно вставить один специальный символ, вам не нужно каждый раз вставлять уравнение. Microsoft Word предлагает полезную функцию под названием Автозамена . Параметры Автозамена в Microsoft Word предлагают два разных способа быстрого добавления любого специального символа или даже
большие фрагменты текста:
Microsoft Word предлагает полезную функцию под названием Автозамена . Параметры Автозамена в Microsoft Word предлагают два разных способа быстрого добавления любого специального символа или даже
большие фрагменты текста:
Используя этот метод, вы можете воспользоваться функциями Автозамена математикой , не вставляя уравнения.Чтобы включить или выключить AutoCorrect из Math символов, выполните следующие действия:
1. На вкладке Файл щелкните Параметры :
2. В диалоговом окне Word Options на На вкладке Проверка нажмите кнопку Параметры автозамены … :
3. В диалоговом окне Автозамена на вкладке Математическая автозамена выберите параметр Использовать математические правила автозамены вне математических областей :
После нажатия OK вы можете использовать любое из перечисленных Названия символов , и Microsoft Word заменит их соответствующими символами:
Примечание : Если вам не нужна последняя замена, нажмите Ctrl + Z , чтобы отменить ее.
III. Использование диалогового окна символа:
Microsoft Word предлагает очень удобную возможность комбинировать два символа (см. Наложение персонажей). Чтобы добавить к символу какой-либо элемент, например, штрих , апостроф и т. Д., Введите символ и сразу же вставьте векторную метку из подмножества комбинирования диакритических знаков для символов любого шрифта (если он существует).
Чтобы объединить элемент с введенным символом, откройте диалоговое окно Символ :
На вкладке Insert в группе Symbols нажмите кнопку Symbol , а затем нажмите More Symbols… :
В диалоговом окне Symbol :
- В списке Font выберите шрифт Segoe IU Symbol ,
- Дополнительно, чтобы найти символы быстрее, в списке подмножества выберите Объединение диакритических знаков для символов подмножество ,
- Выберите символ:
- Нажмите кнопку Insert , чтобы вставить символ,
- Нажмите кнопку OK , чтобы закрыть диалоговое окно Symbol .

Как набрать векторный символ в Word? — Mvorganizing.org
Как набрать векторный символ в Word?
Как разместить стрелку прямо над буквой в Word для создания векторных уравнений. Начните с обычного ввода уравнения, затем выделите букву, над которой вы хотите разместить стрелку, перейдите на вкладку вставки и выберите «Equation». В разделе «Акцент» выберите стрелку, которую нужно разместить над буквой.
Как вы читаете векторные обозначения?
Его длина — это его величина, а направление указано стрелкой.Вектор здесь может быть написан OQ (жирный шрифт) или OQ со стрелкой над ним. Его величина (или длина) записывается OQ (символы абсолютного значения). Вектор может быть расположен в прямоугольной системе координат, как показано здесь.
Что такое правильная векторная запись?
Векторная нотация — это обычно используемая математическая нотация для работы с математическими векторами, которые могут быть геометрическими векторами или членами векторных пространств. Сокращенные обозначения включают тильды и прямые линии, помещенные соответственно ниже или выше имени вектора.
Сокращенные обозначения включают тильды и прямые линии, помещенные соответственно ниже или выше имени вектора.
Какая стандартная форма вектора?
Стандартное положение векторов имеет начальную точку в начале координат. Компонентная форма вектора — это упорядоченная пара, которая описывает изменения в значениях x и y. На графике выше x1 = 0, y1 = 0 и x2 = 2, y2 = 5. Упорядоченная пара, которая описывает изменения, это (x2- x1, y2- y1), в нашем примере (2-0, 5-0) или (2,5).
Как решить векторную задачу?
Давайте поработаем над этим.
- Шаг 1) Нарисуйте вектор.
- Шаг 2) Добавьте ножки треугольника.
- Шаг 3) Математика. Направление y = величина * sin (угол) = 5 метров * sin (37) = 3 метра. Направление x = величина * cos (угол) = 5 метров * cos (37) = 4 метра.
- Шаг 4) Подставьте решения в определение вектора. Вектор = 3 + 4ŷ
Позиция — это вектор?
Положение объекта дается относительно некоторой согласованной контрольной точки. Позиция — это векторная величина. У него есть как величина, так и направление.Величина векторной величины — это число (с единицами измерения), показывающее, какая часть величины существует, а направление указывает, в какую сторону она указывает.
Позиция — это векторная величина. У него есть как величина, так и направление.Величина векторной величины — это число (с единицами измерения), показывающее, какая часть величины существует, а направление указывает, в какую сторону она указывает.
Как вы рассчитываете векторную работу?
Работа W, совершаемая силой F при движении вдоль вектора D, равна W = F⋅D.
Как вычислить вектор?
- Пример: сложите векторы a = (8, 13) и b = (26, 7) c = a + b. c = (8, 13) + (26, 7) = (8 + 26, 13 + 7) = (34, 20)
- Пример: вычесть k = (4, 5) из v = (12, 2) a = v + −k.а = (12, 2) + — (4, 5) = (12, 2) + (−4, −5) = (12−4, 2−5) = (8, −3)
- Пример: складываем векторы a = (3, 7, 4) и b = (2, 9, 11) c = a + b.
Какова длина вектора?
Длина вектора — это квадратный корень из суммы квадратов горизонтальной и вертикальной составляющих. Если горизонтальный или вертикальный компонент равен нулю: если a или b равны нулю, то формула длины вектора вам не нужна. В этом случае длина — это просто абсолютное значение ненулевой компоненты.
Является ли длина вектора его величиной?
Величина вектора — это длина вектора. Величина вектора a обозначается как a∥. На этой странице выведены формулы для величины векторов в двух и трех измерениях через их координаты. Для двумерного вектора a = (a1, a2) формула его величины a∥ = √a21 + a22.
Какова формула определения величины вектора?
Чтобы работать с вектором, нам нужно уметь определять его величину и направление.Мы находим его величину, используя теорему Пифагора или формулу расстояния, и мы находим его направление, используя функцию обратной тангенса. Для вектора положения → v = ⟨a, b⟩ величина находится по формуле | v | = √a2 + b2.
Как определить величину вектора по двум точкам?
Величина вектора → PQ — это расстояние между начальной точкой P и конечной точкой Q. В символах величина → PQ записывается как | → PQ | . Если заданы координаты начальной и конечной точек вектора, можно использовать формулу расстояния, чтобы найти его величину.
Как определить величину и направление вектора?
Мы находим его величину, используя теорему Пифагора или формулу расстояния, и мы находим его направление, используя функцию обратной тангенса. Для вектора положения → v = ⟨a, b⟩ величина находится по формуле | v | = √a2 + b2. Направление равно углу, образуемому с осью x или с осью y, в зависимости от приложения.
Есть ли у величины направление?
Величина, не зависящая от направления, называется скалярной величиной.Векторные величины имеют две характеристики: величину и направление. Скалярные величины имеют только величину. При сравнении двух векторных величин одного типа необходимо сравнить как величину, так и направление.
Что имеет величина и направление?
Вектор в физике — величина, которая имеет как величину, так и направление. Обычно он представлен стрелкой, направление которой совпадает с направлением количества, а длина пропорциональна величине величины.Хотя вектор имеет величину и направление, у него нет позиции.
Что имеет величину, но не направление?
Скаляр — это любая величина, имеющая величину, но не имеющая направления.
У скорости есть величина и направление?
Скорость имеет только величину, а скорость имеет величину и направление.
Может ли время быть вектором?
Время не является компонентом вектора. Время — одна из координат. Есть «направление времени», то есть вектор.В специальной теории относительности для любого данного наблюдателя время — это вектор в пространстве-времени, который указывает в направлении, перпендикулярном всем пространственным направлениям этого наблюдателя.
Температура — это вектор или скаляр?
Температура определенно является скалярной величиной. Температура — это мера средней кинетической энергии атомов в массе. Определенно есть значение (которое можно интерпретировать как величину), но ему не хватает направления. Следовательно, он не может соответствовать требованиям считаться вектором.
Сила — это векторная величина?
(Введение в механику) векторные величины — это величины, которые обладают как величиной, так и направлением. Сила имеет как величину, так и направление, поэтому: Сила — это векторная величина; его единицы — ньютоны, Н. Силы могут вызывать движение; в качестве альтернативы силы могут действовать, чтобы удерживать объект (объекты) в состоянии покоя.
Является ли общая длина пути векторной величиной?
Импульс: определяется как сила, действующая на тело в течение определенного периода времени. Это интеграл силы по временному интервалу.Он задает направление движения количества движения на теле, т. Е. Является векторной величиной. Общая длина пути: это общее расстояние, пройденное телом.
Что из следующего является единственной векторной величиной?
В то время как угловой момент тела (L) имеет как величину, так и направление. Следовательно, это векторная величина.
Плотность — это векторная величина?
Векторный аналог массы — это вес. Вес — это векторная величина. Вес — это сила, а силы — это векторы, т.е.е. имеющий как величину, так и направление. Плотность — это скалярная величина, имеющая только величину и не дающая информации о направлении.
Можем ли мы добавить компонент вектора к тому же вектору?
Компонент вектора может быть добавлен к тому же вектору только с использованием закона сложения векторов. Таким образом, добавление компонента вектора к тому же вектору не является осмысленной алгебраической операцией.
Illustrator — преобразование шрифта в векторный
Главная »Illustrator — Преобразование шрифта в векторныйКлиенты могут создавать и отправлять свои собственные дизайны или логотипы.
Все шрифты в дизайне или логотипе необходимо преобразовать в векторный контур, прежде чем Lyfe Pix сможет использовать дизайн или логотип.
Убедитесь, что все шрифты преобразованы в векторный контур, используя инструмент «Создать контур» в Adobe Illustrator или аналогичные функции в другом графическом программном обеспечении. Это необходимо сделать до того, как вы отправите в Lyfe Pix какой-либо дизайн или логотип.
Шрифты, которые не преобразованы в контур, могут некорректно отображаться в окончательном дизайне. Наша система может даже автоматически заменить их другим шрифтом.Важно преобразовать все шрифты в векторный контур, чтобы этого не произошло.
ИНСТРУКЦИИ:
Как преобразовать шрифт в векторный контур в Adobe Illustrator:
Выполните следующие простые шаги, чтобы убедиться, что текст будет сохранен в том виде, в котором он был изначально разработан:
Шаг 1: Выберите шрифт, который вы хотите использовать. Введите текст в Illustrator с помощью инструмента Type Tool (T)
Выберите шрифт и введите текст в Illustrator
Шаг 2: Выберите инструмент выделения в Illustrator (ярлык = «V») и выделите введенный текст
Выберите инструмент «Выделение» в Illustrator (ярлык = «V») и выделите текст
Шаг 3: Выделив текст, нажмите Тип в верхнем меню и выберите Создать контуры
Используйте функцию Create Outline в Illustrator
Все готово: Окончательный результат должен выглядеть примерно так, как показано на рисунке ниже.Вы успешно преобразовали шрифт в векторный контур.
Окончательный результат после преобразования шрифта в векторный контур текста
Шаг 4: Сохраните файл и отправьте дизайн / логотип в Lyfe Pix.
Ограниченное по времени предложение:
Скидка 42% на Adobe CC — Подписка на все приложения
Подписка на все приложения Adobe CC (20+ приложений, включая Photoshop, Illustrator, InDesign и т. Д.) За всего за 347,93 доллара . Обычно это стоит 52 доллара.99 в месяц, но в течение ограниченного времени вы можете получить целый год всего за 347,93 доллара.
ПОЛУЧИТЬ СКИДКУ .
Получите самую низкую цену на подписку на все приложения Adobe CCВыразите вектор в форме компонента
Если вы считаете, что контент, доступный через Веб-сайт (как определено в наших Условиях обслуживания), нарушает или несколько ваших авторских прав, сообщите нам, отправив письменное уведомление («Уведомление о нарушении»), содержащее в информацию, описанную ниже, назначенному ниже агенту.Если репетиторы университета предпримут действия в ответ на ан Уведомление о нарушении, оно предпримет добросовестную попытку связаться со стороной, которая предоставила такой контент средствами самого последнего адреса электронной почты, если таковой имеется, предоставленного такой стороной Varsity Tutors.
Ваше Уведомление о нарушении прав может быть отправлено стороне, предоставившей доступ к контенту, или третьим лицам, таким как в качестве ChillingEffects.org.
Обратите внимание, что вы будете нести ответственность за ущерб (включая расходы и гонорары адвокатам), если вы существенно искажать информацию о том, что продукт или действие нарушает ваши авторские права.Таким образом, если вы не уверены, что контент находится на Веб-сайте или по ссылке с него нарушает ваши авторские права, вам следует сначала обратиться к юристу.
Чтобы отправить уведомление, выполните следующие действия:
Вы должны включить следующее:
Физическая или электронная подпись правообладателя или лица, уполномоченного действовать от их имени; Идентификация авторских прав, которые, как утверждается, были нарушены; Описание характера и точного местонахождения контента, который, по вашему мнению, нарушает ваши авторские права, в \ достаточно подробностей, чтобы позволить репетиторам университетских школ найти и точно идентифицировать этот контент; например нам требуется а ссылка на конкретный вопрос (а не только на название вопроса), который содержит содержание и описание к какой конкретной части вопроса — изображению, ссылке, тексту и т. д. — относится ваша жалоба; Ваше имя, адрес, номер телефона и адрес электронной почты; а также Ваше заявление: (а) вы добросовестно полагаете, что использование контента, который, по вашему мнению, нарушает ваши авторские права не разрешены законом, владельцем авторских прав или его агентом; (б) что все информация, содержащаяся в вашем Уведомлении о нарушении, является точной, и (c) под страхом наказания за лжесвидетельство, что вы либо владелец авторских прав, либо лицо, уполномоченное действовать от их имени.
Отправьте жалобу нашему уполномоченному агенту по адресу:
Чарльз Кон
Varsity Tutors LLC
101 S. Hanley Rd, Suite 300
St. Louis, MO 63105
Или заполните форму ниже:
Встраивания векторов Word поддерживают социальные онтологические отношения, способные отражать значимые оценки справедливости
Общей чертой дизайна искусственного интеллекта, ориентированного на человека, является необходимость использования людей для оценки, в которой в той или иной ситуации лежат основные права и обязанности.Отсюда правила вводятся в ИИ для смягчения любого потенциального вреда (Bauer 2020a). Мы утверждаем, что это ограничивает возможности ИИ и лишает силы, предоставляемые технологиями. Мы выдвинули предположение, что сам ИИ должен обладать способностью воспринимать пространство-состояние действия и распределять права и обязанности. Такое восприятие позволило бы ИИ опираться на огромное количество информации, включать прецеденты и предыдущие результаты для решения многофакторных этических головоломок в реальных условиях.
Это контрастирует с нисходящими системами, основанными на правилах, которые в некоторой степени воспроизводят методы работы, не связанные с искусственным интеллектом (Cervantes et al. 2020). С другой стороны, восходящее программирование использует алгоритмы машинного обучения (ML), чтобы учиться на шаблонах в подготовленном наборе данных, чтобы сделать вывод о следующем шаге (Bauer 2020a). Такая методология рассматривает нормативные ценности как присущие деятельности агентов, но не определенные явно в терминах общей теории (Wallach et al. 2008). Подход в этой статье можно рассматривать как восходящий, но он использует универсальное правило справедливости, которое присуще встраиваемым словам, которое будет расширено.
Чтобы система ИИ могла воспринимать задействованные контексты для оценки справедливости описания действия или инструкции, требуется метрика справедливости, с помощью которой она может измерять такую активность. В настоящее время показатели для оценки человеческих качеств, таких как сентиментальность и личность, хорошо подтверждены в литературе (Boyd et al., 2015; Hai-Jew 2017; Youyou et al. 2015). Однако действенный и надежный показатель справедливости еще предстоит разработать.
Наша работа в этой статье будет сосредоточена на выполнении первого шага в разработке такой меры, которая фокусируется на интерпретации удобочитаемых текстов и оценке справедливости описанных в них взаимодействий социальной власти.Поскольку документы можно разбить на составляющие абзацы, предложения и слова, в этой статье основное внимание будет уделено анализу отдельных слов, в частности глаголов.
Существует определенное ограничение на использование слов в единственном числе, лишенных контекста. Предложение «Мужчина убил таксиста» vs. «Человек убил сорняк в своем саду» несет в себе как несправедливость, так и справедливость, соответственно, для одного и того же слова «убит». То же можно сказать и об омонимах. Однако такие предложения, как «Мальчик поблагодарил учителя за его помощь», легко классифицировать как справедливые по сравнению с «Мальчик использовал оскорбление против учителя».Здесь два глагола: «благодарить» и «ругать» обычно рассматриваются как справедливые и несправедливые действия, соответственно, даже лишенные контекста. Мы принимаем это ограничение на данном этапе исследования. Мы будем тестировать список глаголов, который использовали (Jentzsch et al., 2019), которые включили в свой конвейер список глаголов «Делай» и «Не делай» в качестве обучающих данных. Однако наша методология отличается от их собственной, поскольку мы не используем никаких обучающих данных, а полагаемся на внутренние социальные онтологии. Наша методология будет рассмотрена после введения в фон, использованный при разработке меры, которая фокусируется на социальной анатомии человеческого разума и социальном дискурсе.
Принципы, лежащие в основе меры справедливости
Человеческий разум способен строить богатые причинные модели, выполнять обобщения и собирать мощные абстракции, несмотря на скудные и неполные данные (Tenenbaum et al. 2011). Моделирование того, как разум использует абстрактные знания для управления выводами, было предпринято с помощью байесовской статистики. Абстрактное знание рассматривается как закодированное в вероятностной генеративной модели. Тот, который описывает причинные процессы в мире таким образом, чтобы облегчить анализ воспринимаемых пространств и их скрытых переменных.Данные о причинно-следственных связях могут быть получены из совпадений между событиями, при этом предполагается наличие причинно-следственных связей. Вероятность отдает предпочтение причинно-следственным связям, которые делают такое совместное появление более вероятным, тогда как априорные отдают предпочтение связям, которые соответствуют базовым знаниям о вероятных событиях (Tenenbaum et al. 2011).
Было высказано предположение, что такие абстрактные знания создают существенные ограничения для обучения. Сторонники развития утверждают, что люди от природы обладают набором основных абстрактных понятий, таких как «агент», «объект» и «причина», чтобы обеспечить фундаментальную онтологию для квалифицирующего опыта (Carey, 2011a, b).Действительно, в литературе наблюдается растущая тенденция к множественному представлению взглядов, при которой абстрактные концепции основаны на множестве входных данных: лингвистических, эмоциональных, сенсомоторных, внутренних переживаний и социальных (Эндрюс и др., 2014; Борги и др., 2018). Было высказано предположение, что расхождение между абстрактными и материальными концепциями может быть лучше всего смоделировано в терминах многомерного пространства, в котором распределены концепции, различающиеся как по уровню абстракции, так и по другим измерениям содержания (Borghi et al.2018).
Эта форма представления абстрактного в многомерном пространстве, включающая вероятностное обучение и статистику совместной встречаемости, напоминает онтологические особенности формы нейронных сетевых вычислений, известной как вложения слов. Эти вложения способны уловить богатые черты человеческого языка, языка, который по своей сути отражает общество и его ценности (Boyd and Richerson 2009; Smith 2010; Drozd et al. 2016).
Социальный разум, человеческий язык и вложения слов
Вложения слов используют процесс, известный как вероятность совпадения, для представления слов.Таким образом, эти слова больше представлены не их словарными определениями, а их отношениями к другим словам. Подход использует словесный контекст для представления значения. Часто улавливается поговоркой: «Вы узнаете слово по компании, которую он держит!» (Firth 1958; Nerbonne and Hinrichs 2006).
Векторы используются для определения того, насколько часто каждое слово встречается в определенном контексте. Каждый вектор состоит из списка чисел, при этом каждое число отражает вероятность. По мере того, как создается список совпадений, начинают выявляться вероятностные модели.Таким образом, такие термины, как «собака» и «кошка», будут с большей вероятностью встречаться друг с другом, чем слова, которые не встречаются вместе так часто, как «собака» и «трубка». По мере того, как список векторов растет, появляется все больше полезной информации о значениях слов. Например, слово «лед» чаще встречается со словом «твердый», чем со словом «газ». В то время как слово «пар» чаще встречается с словом «газ», чем слово «твердый». Следует отметить, что оба слова часто встречаются с водой, поскольку это их общее свойство, но нечасто с несвязанными словами (Pennington et al.2014).
Эти векторы затем могут быть представлены в многомерном пространстве. Каждому слову в документе дается набор координат, который представляет его положение в геометрическом пространстве по отношению к любому другому слову. Настройка этих слов основана на их контексте. Обнаружено, что слова, имеющие много контекстов, расположены рядом друг с другом, по сравнению со словами, имеющими разные контексты (Козловски и др., 2019). Таким образом, такие слова, как «боль» и «удовольствие» могут оказаться далекими друг от друга, но ближе к «жестокому обращению» и «любви» соответственно.
Преимущество использования векторных обозначений заключается в их арифметических свойствах. Два вектора можно сравнивать, складывать и масштабировать, что позволяет выполнить ряд вычислений. Часто цитируемым примером является манипулирование вектором, который представляет слово «король». Если вычесть из него вектор «мужчина», а затем добавить к нему вектор «женщина», то получится слово «королева». Это происходит потому, что представление «Король» содержит представление «человека» из-за совместного возникновения.Когда это качество удаляется с помощью вычитания, это слово перестает быть тесно связанным с «королем», но остается тесно связанным с королевской властью. Таким образом, замена слова «мужчина» на «женщину» позволяет новому вектору быть близким к слову, которое представляет королевскую семью и женщин, то есть «королеву» (Chen et al., 2017; Drozd et al., 2016).
Также можно определить, насколько похожи или различны два вектора, измеряя их косинусное сходство. Из тригонометрии Cos (0) = 1, Cos (90) = 0 и 0 <= Cos (θ) <= 1.Максимально похожие векторы параллельны (т. Е. Под углом 0 градусов друг к другу) и минимально подобны, если они перпендикулярны (т. Е. Под углом 90 градусов друг к другу). Эта функция позволяет напрямую сравнивать слова. С помощью этого метода можно сравнивать отдельные слова, такие как «невнятный» и «безответственный», например, с ожиданием того, что аналогичные слова будут иметь более высокий балл косинуса, чем разнородные слова. Мощность и гибкость, предлагаемые этим методом, позволили усилить большую часть работы, выполняемой в области обработки естественного языка (НЛП) (Almeida и Xexéo, 2019; El-Amir, 2020).
Такая концепция семантики была описана как гипотеза распределения (Clark and Pulman 2007). Этот подход частично отражает то, как разум действует через параллельные процессы и взвешенные связи (Миколов и др., 2013).
Эпистемология вложений слов
Одним из открытий, сделанных с помощью вложений слов, является их способность достоверно отражать значимые закономерности из данных, которые они изучили. Сбор статистики, присущей языку, с использованием этого метода и проецирование ее в многомерное пространство позволило отразить тонкие отношения в арифметических терминах.Например, когда вложения слов берутся из документов, описывающих социологию страны на протяжении нескольких десятилетий, измерения, вызванные различиями слов, такими как (богатый — бедный), соответствуют измерениям культурного значения. Было показано, что проекция слов на эти измерения выявляет широко разделяемые ассоциации, подтвержденные данными опроса (Kozlowski et al.2019). Было обнаружено, что эта способность встраивания слов одновременно находить объекты в нескольких культурных измерениях, включая такие классы, как раса, пол, социально-экономический класс, делает их мощным инструментом для исследования интерсекциональности, например (Kozlowski et al.2019).
Это открытие не относится к социальным наукам. Естественные науки также выиграли от их использования. Например, материалы по материаловедению, представленные в опубликованной литературе, были закодированы с использованием Word Embeddings без какого-либо явного добавления химических знаний. Было обнаружено, что вложения отражают сложные концепции материаловедения, такие как основная структура периодической таблицы Менделеева и взаимосвязи между структурой и свойством материалов. Используя эту неявную информацию, хранящуюся в векторном пространстве, исследователи предложили материалы для функциональных приложений за несколько лет до своего открытия.Предполагается, что скрытые знания о будущих открытиях в какой-то степени встроены в прошлые академические статьи (Tshitoyan et al.2019). Встраивания также успешно улавливают скрытые концепции, такие как идеология, обеспечивая интегрированную основу для косвенного изучения политического языка (Rheault and Cochrane 2020).
Однако вложения слов имеют свои ограничения. Одна из них заключается в том, что они могут отражать предубеждения, содержащиеся в текстах, которые они представляют. Было обнаружено, что такие слова, как «врач» и «инженер» чаще встречаются с «мужчиной», чем «женщина» в современных текстах и репортажах.Таким образом, векторное пространство, построенное с использованием таких документов, также будет отражать такое смещение (Калискан и др., 2017; Гарг и др., 2018). Эти предубеждения рассматривались как препятствие для эффективности использования встраиваний для приложений социального взаимодействия, таких как их использование при выборе кандидатов (Köchling and Wehner 2020). Тем не менее, другие предубеждения, присущие встраиванию слов, в некоторых случаях могут быть полезны для извлечения основной концепции, которая вызвала проявление такой предвзятости. В этой статье мы продемонстрируем наличие предвзятости в отношении справедливости в Word Embeddings и воспользуемся этим в наших интересах для разработки метрики справедливости.
Предвзятость справедливости, просоциальная склонность
Подобно тому, как было обнаружено, что вложения слов содержат гендерные и этнические предубеждения (Калискан и др., 2017; Брюнет и др., 2019), мы выдвигаем аргументы в пользу того, что люди предвзято относятся к совершение действий, которые не дают им ощущения выгоды. То есть люди инстинктивно противятся бесполезной деятельности. Что, будучи социальным видом, люди склонны отдавать предпочтение социальным действиям. Действия, которые приносят чувство выгоды и радости, а не причиняют себе вред и боль.Мы инстинктивно классифицируем поступки, которые мы были бы счастливы сделать с собой, как положительные, а действия, которые мы не хотели бы делать с собой, как отрицательные. Такое предубеждение, как мы полагаем, универсально для людей. Чтобы расширить эту предвзятость, поскольку она является центральным моментом в данной статье, мы рассмотрим литературу по социальной психологии и моральной психологии по этой теме.
Онтология справедливости
Несмотря на импульсы к выживанию, акты сотрудничества рассматриваются как центральные для человеческого поведения (Trivers 1971; Milinski et al.2002), порождая чувства, которые способствуют сотрудничеству (Nowak 2006). Когда дело доходит до принятия решения о поступке по отношению к другому, одним из основных чувств является осознание того, как другой человек отреагирует на указанное действие (Civai 2013). Люди эволюционно удерживаются от вредных действий, избегая возможных санкций. Попутно их эволюционно поощряют к сотрудничеству, получению возможных выгод и вознаграждений, прямых или косвенных. Это чувство расчета, которое влечет за собой соображения по поводу групповой ответственности, будь то полное вознаграждение или санкции, рассматривалось как то, которое способствует сотрудничеству и социальным связям (Fehr et al.2002; Fehr and Rockenbach 2004).
Это развитое чувство сотрудничества вызывает у человека чувство долга. Мы утверждаем, что чувство долга имеет те же коннотации, что и ответственность: чувство сдерживания порождает неотъемлемое чувство ответственности за то, чтобы не причинять вред другому, а также одновременно присваивает другому неотъемлемое право не пострадать (van Dijk and Vermunt 2000). Хотя нельзя сказать, что они возникли как явные социальные ценности, чувства обладают такими же вытекающими отсюда качествами.Ибо, несмотря на эволюционное происхождение чувства сдерживания и поощрения к действиям, способствующим социальному выживанию, результат по своей сути может быть сформулирован как результат, который порождает эти мета-качества прав и обязанностей. Мета-качества, которые возникают как следствия развитого чувства кооперативного поведения, чувства, что человек должен или не должен. Ответственность становится управляемой чувством озабоченности (Берковиц и Дэниелс, 1963; Кремер и Ланге, 2001).
Эти познания можно сформулировать как восприятия, которые составляют основу золотого правила (Джордж Дюк и Джордж 2017, стр.44), поскольку для того, чтобы оценить, является ли действие тем, что «я хотел бы для себя», я должен воспринимать контекст с точки зрения качеств, которые предполагают курс действий. Тот, который я бы пожелал себе, даже когда действую в обществе, не встретит или не смогу ответить взаимностью (van Dijk and Vermunt, 2000).
Даже макиавеллисты, считающие причинение вреда другим оправданным, не желали бы быть объектом их действий. Врожденное межкультурное отвращение к тому, чтобы относиться к другим так, как вы бы не хотели, чтобы с ними обращались, остается, даже если они продолжат действовать.Это чувство контрастирует с организмами, которые не обрабатывают способность к таким чувствам, например, с вирусами и бактериями. Такое отвращение к неравенству характерно для видов, которые регулярно сотрудничают даже с не родственниками (Brosnan and Bshary, 2016), и формирует основу социальной предвзятости, то есть предвзятости к социальным действиям.
Исходя из этого, это будет мера ответственности человека и его восприятия фрейма как того, что гарантирует такую квалификацию (Handgraaf et al.2008), что станет отправной точкой для этической оценки.
В каждом контексте мера восприятия кадра позволяет человеку учитывать соответствующие измерения. Когда контекст оценивается как вредный для одного субъекта, например, такой как убийство, он будет более заметным. Было обнаружено, что чувства являются неотъемлемой частью анализа, с помощью которого люди оценивают решения в сложных ситуациях суждения (Sadler-Smith 2012). Здесь восприятие контекста играет определяющую роль (Decety et al.2012; Fessler and Haley 2003), и такую значимость можно представить через эмоции, отрицательные и положительные, такие как боль и радость.
Можно возразить, что война и жестокость проистекают из познаний, указывающих на антисоциальность (Kahane 2016, p. 285). Однако этому возражению можно противопоставить наблюдение, что просоциальные действия желательны для себя, а антиобщественные — нет. Даже макиавеллисты, как уже упоминалось, считая узурпацию власти оправданной, не желали бы того же для себя.Отвращение к таким действиям сохраняется, и люди характеризуются как социально осведомленные агенты (Izzidien and Chennu 2018).
Это чувство «должного» не следует путать никакими нормативными утверждениями. В статье не делается вывод о моральном образе действий из-за наличия такого социального познания. Скорее, в документе утверждается, что из-за представлений, которые помогают в социальном выживании, люди социально склонны к социальной жизни. Выявление этого чувства у людей можно рассматривать как чувство, которое по своей природе поощряет действия сотрудничества, и то, что продолжающееся выживание включает познания не только самих себя, но и других агентов (Simon 1990; Brewer 2004).Каждого человека удерживают от действий, которые могут нанести ущерб его выживанию, и в то же время одновременно поощряют его к сотрудничеству, поощряют просоциальные действия, поддерживают ультра-кооперативный образ жизни (Tomasello 2014).
Было показано, что восприятие других людей, которые зависят от нас в получении необходимых благ, вызывает такое чувство ответственности, побуждая нас способствовать продвижению их интересов (van Dijk and Vermunt 2000). При взаимозависимости отношений, направленных на выживание, можно обнаружить, что у индивидов есть склонность — или положительное социальное предубеждение — приходить на помощь другим индивидам, чем они более зависимы (Berkowitz and Daniels 1963; Berkowitz 1972; Schwartz and Howard 1982). .Поскольку такие расчеты влияют на выживаемость, некоторые считают, что социальное поведение имеет биологические корни (Hewstone et al. 2012, p. 184) и общие неврологические процессы, такие как теория разума, эвристика сравнения и эмпатия (Tabibnia et al. 2008). ; Civai 2013; Corradi-Dell’Acqua et al.2013).
Кроме того, исследования показывают, что корреляция между фактическим поведением и ожиданиями приводит к тому, что ожидания квалифицируются как важный фактор в совместном поведении или щедрых действиях (Brañas-Garza et al.2017) и были связаны со стадным поведением, влияющим на формирование социальных норм (Brunnermeier 2001; Castelfranchi et al. 2003; Bicchieri 2006).
Таким образом, мы утверждаем, что, когда люди воспринимают социальный контекст, требующий оценки справедливости, они инстинктивно порождают чувство долга. То, что можно истолковать как чувство ответственности. Это сочетается или смягчается мерой важности действия и его эффекта: вред / польза, боль / радость и его результат: санкция / награда.
Таким образом, чтобы отметить действие как справедливое или несправедливое, похоже, что ИИ должен учитывать эти первичные когниции. Это может позволить ИИ начать делать человеческие оценки, которые включают соответствующие необходимые параметры. Восприятия, которые, возможно, необходимы для проведения оценок справедливости.
Использование встраивания слов для извлечения просоциального предубеждения человека
Мы утверждаем, что на основе этой человеческой склонности — или социального предубеждения — выживать как социальный вид (Burkart et al. 2014; Peysakhovich et al.2014) человеческий язык представляет собой среду, с помощью которой отражается такая предвзятость (Boyd and Richerson 2009; Smith 2010). Более того, точно так же, как социальные действия — это отношения между агентами и пациентами, мы выдвигаем аргумент, что один из способов, которым можно уловить эту характеристику, — это вложения слов. Это связано с тем, что при таких встраиваниях, учитывая социальную предвзятость человека, определенные действия будут более тесно связаны с концепциями ответственности, чем безответственности. Действия, наполненные чувством ответственности, то есть долга по отношению к другим, также будут связаны с положительными эмоциональными, материальными и социальными аспектами.Будет показано, что эти параметры являются основными представлениями, необходимыми для толкования контекста до проведения оценки справедливости.
Одной из проблем машинного обучения (ML) и глубокого обучения (DL) при обнаружении закономерностей в данных для классификации является необходимость правильно определить, какие свойства использовать. Это может быть просто, если данные легко охарактеризовать с помощью четких маркеров, таких как цвет или форма. Однако, когда данные имеют большой размер — в абстрактном смысле — определение соответствующих параметров представляет собой проблему.Язык не является исключением, предложение имеет множество возможных измерений: эмоциональное, моральное, властное и эстетическое, и это лишь некоторые из них. Таким образом, чтобы выявить соответствующие параметры для универсально приемлемой классификации справедливости, необходимо рассмотреть этот момент.
В качестве отправной точки в данной статье рассматриваются вышеупомянутые первичные восприятия, которые обычно возникают у людей, когда они сталкиваются с ситуацией, в которой они должны сделать этическую квалификацию: делать или не делать.
Чтобы отделить их, мы предлагаем использовать установленную технику сложения, вычитания и сравнения векторов.
Разработка вектора справедливости для оценки слов
Хотя можно использовать процесс маркировки, чтобы пометить каждое исследуемое предложение с точки зрения этих абстракций — вместе с их причинными свойствами, например, «Мальчик пнул ребенка»:
( Мальчик ): Агент, безответственный. ( Baby ): Пациент, Боль, Потеря. ( Удар ногой, ) Причинно-следственная связь, несправедливость.Затем обучите алгоритм машинного обучения, основанный на таких абстракциях, в этой статье предлагается, что такой шаг не нужен.
Это основано на предположении, что процесс совпадения слов по своей сути захватывает эти реляционные свойства. Например: агент действует на пациента (например, «Мальчик ударил по мячу, и он ушел далеко»), причинный результат сдерживается («он далеко ушел»). Тем не менее, альтернативное предложение, такое как («Шар был зеленым, и он был большим», в котором нет агента, действующего на пациента, приводит к кадру, в котором нет результата.Первое предложение по своей сути содержит абстракции: агент — пациент — результат. А второй — нет. Это измерение, если оно обнаружено алгоритмом машинного обучения, неявно позволяет ему изучить концепцию причинности: причинный результат можно найти только в текстах, в которых есть силовое взаимодействие, то есть с двумя или более действующими лицами.
В статье мы считаем, что эта информация присуща вложениям слов, даже если такие предложения не помечены такими абстракциями. Более того, поскольку властные взаимодействия имеют свои особенности, то есть их можно описать как действия, которые можно было бы пожелать для себя, или как нет, т.е.е. справедливо или несправедливо, можно утверждать, что при встраивании очень больших текстовых документов, это условие справедливости также будет присутствовать. Так как, например, такие слова, как «ругательство», чаще встречаются со словами, относящимися к санкциям, безответственности и боли, чем к ответственности, вознаграждению и радости. Отражая вышеупомянутую социальную предрасположенность, положительную социальную предвзятость в обществе, как было подробно описано ранее.
Вложение слов в такой корпус позволит каждому вектору слов быть частично репрезентативным относительно того, как он соотносится с социальными онтологическими абстракциями всех других слов.По мере роста корпуса, отражение человеческого социального положения становится все более убедительным — если, например, корпус не является частью научной фантастики, отражающей альтернативные реальности. Поскольку векторизованный корпус характеризуетс на основе евклидовых расстояний. Затем слова можно измерить на предмет их близости или расстояния от других.
В документе предполагается, что при создании единого вектора, который фиксирует требуемые измерения справедливости, станет возможным измерить, насколько подобен такой вектор любому действию слова в корпусе, без необходимости каких-либо обучающих данных.
Глаголы отражают действия, обычно между двумя или более агентами. Они также поддаются этической квалификации: хотел бы я себе этот «глагол»? При этом справедливый поступок — это то, что я сделаю, а несправедливый — нет. Глаголы также связаны с определенными грамматическими ожиданиями, такими как ассоциация с абстрактными единицами, такими как объекты или дополнительные предложения (Fortescue 2017). Таким образом, они по своей сути выступают в качестве претендентов на совместные события «агент-действие-результат-оценка».
Чтобы проверить эту гипотезу, в статье представлена конструкция того, из чего состоит вектор справедливости.Это достигается за счет принятия терминов, описывающих абстрактные измерения, перечисленные выше, из литературы по социальной психологии. Измерения, которые люди обычно используют при оценке справедливости. Проводится проверка обоснованности использования этого вектора для различения честных и несправедливых действий. Для этого рассчитывается косинусное сходство для вектора справедливости по набору глаголов. Где каждый глагол квалифицируется как справедливый или несправедливый в соответствии с золотым правилом. Список глаголов, представленный в статье (Jentzsch et al.2019). Однако вместо того, чтобы использовать обучающие данные, как они это делают, в нашей статье представлен метод квалификации действий с силой, предоставляемой встраиванием слов, с использованием соответствующих психологических параметров для вынесения суждения о справедливости.
Перед тем, как перейти к разделу о методах, мы представляем коллекцию гипотетических сценариев, чтобы описать, как правило справедливости проявляется в манере, которая привлекает всеобщее внимание.
Сценарий 1
Том видит проходящего Джеффа. У Тома есть желание ударить его, но он спрашивает себя: «Хотел бы я, чтобы меня ударили?» Отвечая себе отрицательно, он решает воздержаться.В свою очередь, он не ведет себя несправедливо по отношению к Джеффу.
Сценарий 2
Том не против, чтобы люди называли его «четырехглазым» из-за ношения очков. На самом деле, он находит это забавным. Однажды он видит Джеффа, тоже носящего очки. Тому хочется называть Джеффа «четырехглазым». Во-первых, кажется, что соображение справедливости «желаю ли я того же самому себе» не поможет Тому быть справедливым. Тем не менее, подумав, Том заключает, что причина, по которой он не против того, чтобы люди называли его «четырехглазым», заключается в том, что он находит это забавным.Джеффу, однако, это не показалось бы забавным, более того, он уверен, что Джефф сочтет это оскорбительным. Поскольку Том хотел бы, чтобы другие не оскорбляли его, и то, что называние Джеффа «четырехглазым» не развеселило бы Джеффа, скорее, было бы оскорблением Джеффа, Том, таким образом, использует соображения справедливости, чтобы обращаться с ним так, как он хотел бы, чтобы относились к нему. то есть не для того, чтобы оскорбить его, скорее, чтобы сказать что-то такое, что его позабавит.
Сценарий 3
Том путешествует по той части света, где хозяева встречают своих гостей большим горячим обедом.Джефф тоже гость, но в другом регионе мира, который встречает гостей только чашкой чая. Две культуры, каждая по-своему ценит гостеприимство. Тем не менее, несмотря на культурные различия, правило справедливости также может применяться: в первой культуре было бы несправедливо предлагать еду всем, кроме одного, а этому выделенному гостю только чашку чая. Это потому, что в любой культуре никто не хочет получать меньше, чем полагается. Хозяин в одной части мира хотел бы, чтобы ему предложили горячую еду, если бы он был гостем, тогда как хозяин в другой части мира не почувствовал бы боли или возмущения, если бы ему не подали больше, чем чашку чая.Каждый будет считать справедливым то, что он пожелает для себя в соответствующем контексте.
Сценарий 4
Что, если Джефф собирался получить штраф за превышение скорости? Том, офицер закона, может не захотеть покупать билет сам. Будет ли его выдача билета означать, что он поступает несправедливо?
Чтобы распаковать это, мы можем рассмотреть следующее. Если бы Джефф жил на оживленной улице, он бы не хотел, чтобы его дети или он сам пострадали из-за превышения скорости машин. Таким образом, он поддерживает средства для предотвращения превышения скорости автомобилями.Скажем, за счет использования штрафов за превышение скорости.
Если Джеффа поймают на превышении скорости, то для того, чтобы быть последовательным, ему придется признать, что наказание за превышение скорости является справедливым действием, даже если он будет раздражен. Это можно рассматривать как случай, когда виновный признает, что «заслуживает наказания». Они могут не получать от этого удовольствия или даже эмоционально желать этого, но они считают это оправданным. Однако, если наказание предполагало обезглавливание, например, Джефф возразил бы, поскольку Джефф не пожелал бы того же самого себе.
В основе всего этого лежит общий фактор, который люди обычно не любят причинять вред. Они признают это в себе и в других. Таким образом, люди признают, что все люди обычно не хотят получать травмы, независимо от их культуры. Эта характеристика придает силу использованию оговорки «не относиться к другим так, как не хотелось бы, чтобы с ними обращались» в качестве основы для вектора справедливости.
Использование терминов «ответственность» и «безответственность» для описания этой эвристики в некоторой степени ограничено, поскольку полный вопрос, заданный в форме предложения «хотел бы я совершить это действие для себя» или аналогично «для моих близких», не полностью отражен. .Поскольку эта статья сосредоточена на отдельных словах, мы рассматриваем возможность использования таких предложений в нашем обсуждении дальнейшей работы.
Таким образом, и для этой статьи мы выбрали алгоритм GloVe (Pennington et al. 2014), чтобы сделать наши вложения, поскольку он сосредоточен на отдельных словах. После предварительной обработки алгоритм создает матрицу совпадения, которая кодирует вероятность появления двух слов в одном контексте. Затем он использует различные стратегии (например, матричную факторизацию) для создания вложения, которое сохраняет информацию о совместном появлении (Liu et al.2019).
Построение вектора справедливости
Чтобы использовать вложения GloVe для оценки отдельных слов, необходимо разработать метод, с помощью которого такие слова, как «убийство», «кража» и «помощь», можно разделить на категории. Таким образом, эта статья вносит свой вклад в литературу, предполагая, что:
- я
вложений слов в перчатках (Pennington et al., 2014) несут в себе социальные отношения, которые можно извлечь.
- ii
В силу того, что они являются социальным видом, эти социальные отношения отражают склонность к социальным.
- iii
Используя векторы, можно использовать эту склонность в качестве классификатора посредством сравнения косинусного сходства между тестовым словом (например,g., «убийство») и Вектор справедливости.
- iv
Вектор справедливости может быть построен, когда он основан на соответствующих социальных аспектах, которые обычно выявляются при проведении оценки справедливости.
Как преобразовать текстовый документ в вектор? Часть — 1 | автор: Винит Шарма
В этой статье мы собираемся обсудить около
1.Пакет слов (BoW)
2. Векторизатор TF-IDF
3. Word2Vec и AvgWord2Vec
4. Встраивание Word2Vec с TF-IDF
Итак, здесь мы не будем вдаваться в математические подробности. Я просто расскажу о частях кода и некоторой информации об этих моделях. Мы будем использовать эту модель после обработки текста, удаления стоп-слов очистки текста и т. Д. Во всем списке документов.
Во-первых, зачем нам эти модели?
Ответ: преобразовать текст в числовой вектор.Но зачем нам преобразовывать текст в вектор. Почему мы не можем просто использовать текст в качестве функций?
Как правило, мы собираемся преобразовать текст в векторное представление, где каждое измерение вектора соответствует слову, а его значение каким-то образом отображается на частоту или важность слова в фрагменте текста. Преобразование может быть выполнено с использованием Bow, idf, tfidf и т. Д. Отсюда вы получаете представление документа в непрерывном многомерном пространстве и можете применять алгоритмы кластеризации и классификации.Алгоритмы машинного обучения не могут работать напрямую с необработанным текстом; текст необходимо преобразовать в числа.
При языковой обработке векторы x выводятся из текстовых данных, чтобы отразить различные лингвистические свойства текста.
Стр. 65, Методы нейронных сетей в обработке естественного языка, 2017.
Существует множество способов преобразования текста в вектор, один из наиболее часто используемых методов — использование нейронных сетей, таких как RNN (Recurrent Neural Networks), LSTM / GRU, который работает феноменально.На самом деле, какой из них использовать, очень зависит от конкретной проблемы, но если у вас достаточно данных для варианта использования, RNN почти всегда превосходят GLM (обобщенные линейные модели). Я выложу статью по этому поводу через несколько дней.
А пока начнем с нашей первой модели.
1. Пакет слов (BoW)
Модель пакета слов — это упрощенное представление, используемое при обработке естественного языка и поиске информации. В этой модели текст (например, предложение или документ) представлен как мешок (мультимножество) его слов.
Пакет слов — это представление текста, которое описывает появление слов в документе. Он включает в себя две вещи:
1. Словарь слов
2. Количество слов словаря, которые есть в документе.
Это называется мешком слов, так как не содержит информации о порядке или структуре слов в документе. Например, модель знает только, есть ли словарное слово в документе, а не там, где оно находится.
Интуиция подсказывает, что документы похожи, если они имеют одинаковое содержание. Далее, только по содержанию мы можем кое-что узнать о значении документа.
Пример модели «Сумка со словами»
D1 — Этот шоколад очень вкусный и доступный.
D2 — Этот шоколад невкусный и недорогой.
D3 — Этот шоколад вкусный и дешевый.
D4 — Шоколад вкусный, и шоколад приятный на вкус.
1-й шаг — В BoW строится словарь i.Набор всех уникальных слов
Vocab– {Это, шоколад, очень, вкусно и, доступно, не вкусно, дешево, вкусно, хорошо}
Допустим, у нас есть d уникальных слов и n текстовых документов ( здесь n = 4, d = 12)
2-й шаг — Мы создадим n векторов (по одному для каждого документа) размера d.
· Каждое слово представляет собой отдельное измерение в векторе, то есть каждый индекс соответствует одному уникальному слову в словаре.
· j-й индекс вектора сохраняет количество j-го слова в документе.
Двоичный BoW:
BoW, в котором хранится наличие слов в словаре. 1, если слово присутствует, 0 в противном случае.
Двоичное представление BoW D1 и D2 —
Длина вектора документа равна количеству известных слов.
Двоичный BoW предпочтительнее BoW. С этого момента я буду обсуждать Binary BoW.
По мере увеличения размера словаря увеличивается и векторное представление документов. В реальном мире проблема, когда у нас большой набор данных.Каждый вектор является разреженным вектором
. (Вектор, большинство элементов которого равны нулю). Точно так же у нас есть d-мерный вектор для всех документов, и матрица, представляющая их, является разреженной матрицей.
Итак, до сих пор мы разбираемся в построении BoW.
Наша цель заключалась в том, чтобы похожий текст приводил к более близким векторам.
В BoW, сходство между векторами документа можно рассматривать как подсчет общих слов в документе.
Больше общих слов, больше похожие документы, но есть ограничение.
BoW не всегда работает очень хорошо. В примере
D1 — Этот шоколад очень вкусный и доступный. D2 — Этот шоколад невкусный и недорогой.
Все слова почти одинаковы, кроме очень вкусно и не вкусно. По словам BoW и большинство слов общие, а значит, и похожие. Но во вкусе они имеют противоположное значение.
Более сложный подход — создать словарь сгруппированных слов. Это одновременно изменяет объем словарного запаса и позволяет сумке слов уловить немного больше смысла из документа.
В этом подходе каждое слово или лексема называется «граммом». Создание словаря пар из двух слов, в свою очередь, называется моделью биграмм. Опять же, моделируются только биграммы, которые появляются в корпусе, а не все возможные биграммы.
N-грамм — это последовательность слов с N-символами: 2-грамм (чаще называемый биграммой) — это последовательность слов из двух слов, таких как «пожалуйста, переверни», «переверни» или «твое домашнее задание». », А 3-граммовая (чаще называемая триграммой) представляет собой последовательность из трех слов, например« пожалуйста, переверни свою »или« переверни свою домашнюю работу »
Часто простой подход с биграммой лучше, чем 1-граммовый пакет. словесная модель для таких задач, как классификация документации.
представление «мешок биграмм» намного мощнее, чем «мешок слов», и во многих случаях его очень трудно превзойти.
(Перед построением н-граммов следует избегать удаления стоп-слов, таких как «not»)
Теперь давайте поищем часть кода —
Код для BoW
В Scikti learn мы уже реализовали BoW модель, которая может работать для нас
из sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer (ngram_range = (1,3))
final_bigram_counts = count_vect.fit_transform (документы)
print («тип векторизатора подсчета», тип (final_bigram_counts))
ВЫХОД:
тип векторизатора подсчета
Примечание:
1. ngram_range = (1, 3) означает, что мы используем униграмму, биграмму, триграмму. В основном мы используем i-й грамм в заданном диапазоне.
2. Документы должны быть списком текстовых документов
3. Final_bigram_counts хранится как разреженная матрица, вот ссылка для дальнейшего понимания разреженной матрицы.
4. Форма final_bigram_counts (final_bigram_counts.get_shape ()) будет n * d. (n: количество документов, d размер словаря).
5. Если вы хотите построить двоичный BoW, в код будет небольшое изменение.
count_vect = CountVectorizer (ngram_range = (1, 3), binary = True)
6. Я рекомендую вам просмотреть документацию Count Vectorizer
Недостатки —
· Значение : при удалении порядка слов игнорируется контекст и, в свою очередь, значение слов в документе (семантика).Контекст и значение могут многое предложить модели, что при моделировании можно было бы различить одни и те же слова, расположенные по-разному («это интересно» против «это интересно»), синонимы («старый велосипед» против «подержанный велосипед»). , и многое другое.
· Словарь : Словарь требует тщательного проектирования, особенно для управления размером, что влияет на разреженность представлений документа.
· Разреженность : Редкие представления труднее моделировать как по вычислительным причинам (пространственная и временная сложность), так и по информационным причинам, когда модели должны использовать так мало информации в таком большом репрезентативном пространстве.
Проблема с оценкой частоты слов заключается в том, что в документе начинают преобладать очень часто встречающиеся слова (например, более высокие оценки), но они могут не содержать столько «информационного содержания» для модели, сколько более редкие, но, возможно, специфичные для предметной области слова.
Один из подходов состоит в том, чтобы изменить частоту слов в зависимости от того, как часто они появляются во всех документах, так что оценки за часто встречающиеся слова, такие как «the», которые также часто встречаются во всех документах, не учитываются.
Этот подход к оценке называется частотой термина, обратная частоте документа, или сокращенно TF-IDF, где:
· Частота термина : оценка частоты слова в текущем документе.
· Частота обратного документа : оценка того, насколько редко слово встречается в документах.
Баллы представляют собой взвешивание, при котором не все слова одинаково важны или интересны.
Баллы имеют эффект выделения слов, которые отличаются (содержат полезную информацию) в данном документе.
Таким образом, idf редкого термина будет высоким, тогда как idf частого термина, вероятно, будет низким.
Код —
из sklearn.feature_extraction.text import TfidfVectorizer
tf_idf_vect = TfidfVectorizer (ngram_range = (1,2))
final_tf_idf = tf_idf_vect.fit_transform (final [‘CleanedText’, тип
, тип «вектор». final_tf_idf))
Вывод:
тип векторизатора счетчика
Итак, до сих пор мы знаем о BoW и TF-IDF.
как они конвертируют текст в векторы. каковы разреженные векторы, интуиция за BoW.
Теперь мы будем обсуждать Word2Vec и Word2Vec, взвешенный по TF-IDF, в моей следующей статье.
Вставка векторной графики в документы Office
Иногда мне не повезло писать доклады для конференций в Microsoft Word, а не в более цивилизованной среде, такой как LaTeX. Полезно, что Word откажется импортировать любой формат векторных изображений, за исключением собственного проприетарного и урезанного формата WMF / EMF. Итак, когда дело доходит до диаграмм, большинство людей склонны вскидывать руки и прибегать к форматам растровых изображений, таким как PNG.Однако это приводит к большим размерам файлов или нечетким распечаткам, так что это неоптимальное решение.
Несмотря на то, что есть много препятствий, через которые можно пройти, тем не менее можно сгенерировать разумные файлы EMF из других векторных форматов, которые Word примет. Существует большое количество подводных камней, не в последнюю очередь из-за плохого соблюдения стандартов, когда дело доходит до рендеринга указанных форматов. Средство визуализации PDF в Mac OS X, к сожалению, не является исключением, поэтому часто приходится прибегать к различным причудливым конвейерам преобразования, чтобы на другом конце было что-то читаемое.
Тем не менее, иногда это работает.
Итак, это процедура, которой я следовал, чтобы генерировать фигуры EMF из произведений искусства, созданных в различных приложениях, включая XFig (который я лично не использую, но мой научный руководитель Карло любит), Inkscape и OmniGraffle.
- Установите pstoedit, инструмент, который принимает различные форматы (например, PDF / EPS) и конвертирует их в другой — в частности, в EMF.
- Убедитесь, что установленная версия поддерживает вывод EMF — в Терминале, pstoedit -help | grep emf.Если этого не произойдет, вам нужно будет найти другую версию в другом месте.
- Если ваша диаграмма еще не в формате PDF или EPS, экспортируйте ее в тот или иной формат.
- Попробуйте в качестве первого шага преобразовать PDF / EPS как есть. Некоторые команды, которые стоит попробовать (открывайте в Word / Powerpoint, чтобы каждый раз видеть результат):
- pstoedit -f emf diagram.pdf / eps output .emf
- pstoedit -f emf -pta diagram.pdf / eps output .emf (Помещайте буквы отдельно, если текст выглядит нечетным)
- pstoedit -f «emf: -m» диаграмма.pdf / eps вывод .emf (используйте Arial в качестве шрифта, если шрифт выглядит неправильно)
- pstoedit -f emf -drawbb diagram.pdf / eps output .emf (Принудительное рисование ограничивающей рамки — попробуйте это, если вы получили обрезку)
- pstoedit -f emf -xscale 2 -yscale 2 diagram.pdf / eps output .emf (Увеличить масштаб — используйте это, если линии выглядят блочно; поэкспериментируйте с большими значениями, чем 2)
- pstoedit -f «emf: -m» -pta -drawbb diagram.pdf / eps вывод .ЭДС (комбинация некоторых из вышеперечисленных)
- Если ваша версия EMF выглядит неправильно, попробуйте экспортировать в EPS, если вы использовали PDF, или PDF, если вы использовали EPS — разные средства визуализации работают по-разному. Повторите описанные выше действия еще раз для этой новой экспортированной версии.
- Если это по-прежнему не дает приемлемого результата, попробуйте другое приложение, которое экспортирует PDF / EPS с улучшенными характеристиками. Вам нужно будет импортировать свою диаграмму в такое приложение, внести косметические изменения, необходимые для противодействия любому забавному бизнесу в результате импорта, а затем экспортировать в формате PDF / EPS.
- Какое-то время я использовал для этой цели Inkscape, но иногда все равно получал забавный вывод.
- Я обнаружил собственное приложение OS X под названием Intaglio, которое, кажется, обеспечивает очень хороший вывод PDF (не так много с EPS).
- Для любого приложения экспортируйте диаграмму в понятном для них формате для последующего импорта.
- Inkscape в основном принимает только SVG, насколько я помню. Вы можете попробовать преобразовать PDF / EPS в SVG снова с помощью pstoedit: pstoedit -f svg diagram.pdf / eps вывод .svg
- Intaglio с радостью возьмет PDF-файл и позволит вам преобразовать его в редактируемый формат, который в некоторых случаях будет работать с достаточно хорошим PDF-файлом. Перетащите PDF-файл на холст, выберите его, затем используйте Object, Convert, PDF для редактирования .
- Исправьте любые визуальные проблемы, вызванные импортом, с помощью инструментов редактирования приложения.
- Экспортируйте схему в PDF / EPS (при необходимости попробуйте оба)
- Intaglio, кажется, лучше всего работает с PDF: выберите рисунок, затем File, Save Selection As , выберите PDF и Crop to Content Size.
- После экспорта PDF / EPS повторите шаг 4, чтобы попытаться получить приемлемый результат.
Весь процесс, несомненно, является тяжелым испытанием и требует серьезной самоотдачи, но он может потребоваться, если вы хотите создать векторную графику в документе Word. Будем надеяться, что гении в Microsoft не забудут добавить импортер PDF и т. Д. В свой следующий офис.
.