PaintTool SAI — тонкая настройка
Тонкая настройка PaintTool-SAI
PaintTool-SAI легко настраивается через файлы конфигурации, которые можно открывать и редактировать в обычном блокноте Windows (но только в нём, никаких Word и иже с ним, они могут добавлять в файл дополнительные коды, которые его испортят).
Я буду настраивать Portable (портативную) версию 1.0.2d (номер версии можно узнать, открыв файл sysinfo.txt, самая верхняя строчка), но это описание подойдёт и для версии 1.1.0. и скорее всего для других версий.
Для портативной версии все файлы, которые нам нужны, находятся в папке App, которая лежит в основной папке программы. Для версии 1.1.0 всё лежит в основной папке программы.
Перед какими-либо исправлениями советую сделать бэкап всей папки с программой, на всякий случай. То есть сохранить где-нибудь её копию.
Все изменения вступят в силу только после перезапуска PaintTool-SAI.
Как создать свой пресет
Для начала попробуем самое простое — добавить свой пресет с заранее заданным разрешением файла.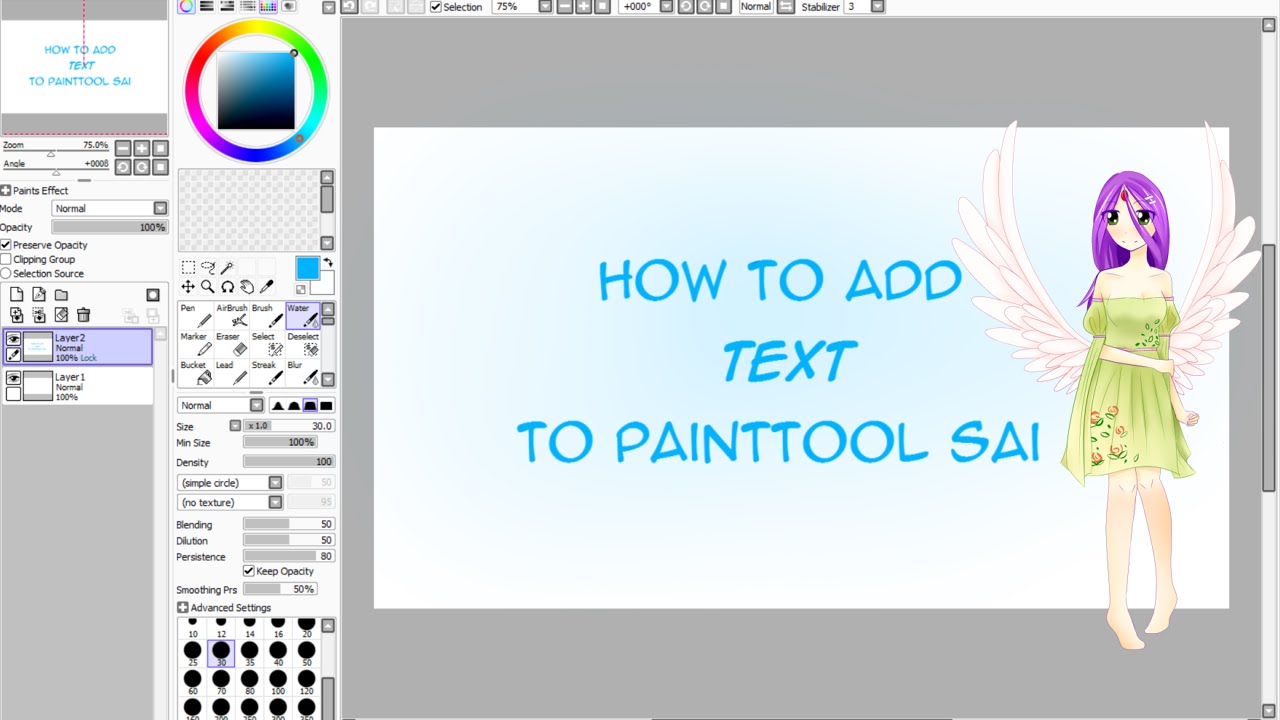 Эти пресеты удобны во время создания нового файла, мы просто выбираем из списка пункт с нужными параметрами, а не задаём их каждый раз в ручную.
Эти пресеты удобны во время создания нового файла, мы просто выбираем из списка пункт с нужными параметрами, а не задаём их каждый раз в ручную.
Для этого нам понадобится открыть файл presetcvsize.conf. На скриншоте я добавил перевод значений для каждого элемента. Самым последним идёт название пресета, оно может быть любым, но обязательно должно быть в кавычках. Для примера, я дописал новый пресет:
1920, 1080, 72, 0, 0, «1920 х 1080 (Full HD)»
Вот как это выглядит в SAI
Как добавить свою текстуру в свойствах слоя
Для этого нужно добавить файл с готовой текстурой (формат файла bmp, цветовой режим Grayscale (градации серого), размер 512х512 пикселей) в папку papertex. Затем открыть в блокноте файл papertex.conf, и добавить строку:
1,papertex\FileName.bmp
она состоит из специального кода (еденицы) и пути к текстуре, FileName.bmp — имя вашего файла. Желательно, чтобы текстура была бесшовной.
Я добавил две своих текстуры, они выделены.
Вот как это выглядит в SAI
Как создать свою текстурную кисть
Для этого нужно добавить файл с готовой текстурой (формат файла bmp, цветовой режим Grayscale (градации серого), размер 512х512 пикселей) в папку brushtex. Затем открыть в блокноте файл brushtex.conf, и добавить строку:
1,brushtex\FileName.bmp
она состоит из специального кода (еденицы) и пути к текстуре, FileName.bmp — имя вашего файла. Желательно, чтобы текстура была бесшовной.
Вот как это выглядит в программе
Как создать свою форму кисти
(всего два типа форм кистей)
Тип 1
Для этого нужно добавить файл с готовой текстурой (формат файла bmp, цветовой режим Grayscale (градации серого), размер 512х512 пикселей) в папку blotmap. Затем открыть в блокноте файл brushform.conf, и добавить строку:
1,blotmap\FileName.bmp
она состоит из специального кода (еденицы) и пути к текстуре, FileName. bmp — имя вашего файла. Желательно, чтобы текстура была бесшовной.
bmp — имя вашего файла. Желательно, чтобы текстура была бесшовной.
Тип 2
Для этого нужно открыть папку elemap. В ней лежат графические файлы формата bmp размером 63х63 пикселя, которые можно отредактировать по-своему, используя только два цвета — белый и чёрный. Путь к новому созданному графическому файлу необходимо добавить в файл конфигурации brushform.conf, добавив в него строку:
2,elemap\FileName.bmp
она состоит из специального кода (двойки) и пути к файлу, FileName.bmp — имя вашего файла.
Бледно-фиолетовая система координат не обязательно должна оставаться видна, она нужна для удобства редактирования. Насколько я понял, инструмент работает таким образом, что поворачивает форму в соответствии с направлением движения кисти. Поэксперементировав, можно добиться своих необычных эффектов.
Я сделал свою форму кисти, просто закрасив этот квадратик 63х63 чёрным цветом. Я назвал эту форму Square_Max. Потом подобрал такие настройки, как на скриншоте. Получился инструмент с интересными тонкими особенностями. Главный минус — он тормозит (не успевает за рукой), тем сильнее, чем больше размер редактируемой картинки и радиус инструмента.
Получился инструмент с интересными тонкими особенностями. Главный минус — он тормозит (не успевает за рукой), тем сильнее, чем больше размер редактируемой картинки и радиус инструмента.
Как исправить некорректное отображение двух названий режимов перехода цветов в настройках слоя
1 — откройте файл language.conf
2 — найдите цепочку символов:
«help.chm»[Strings]
3 — сразу после неё нажмите ввод пару-тройку раз, переведите курсор вверх на образовавшиеся пустые строки и вставьте следующий текст:
BlendMode_Sub = «Вычитание»
BlendMode_AddSub = «Слож-Вычит»
4 — сохранитесь
Как поменять русский язык на английский
Я привык пользоваться англоязычной версией SAI. Поэтому поменял себе русский язык обратно на английский.
Чтобы поменять язык, нужно взять файл language.conf из англоязычной версии и заменить им аналогичный из русской. Я взял его из версии 1.1.0 и он подошёл для портативной версии 1. 0.2d, но не совсем, нужно кое-что добавить.
0.2d, но не совсем, нужно кое-что добавить.
1 — открываем файл language.conf
2 — ищем цепочку символов (вместе с кавычками):
«Status Bar»
3 — сразу после неё нажимаем ввод, появится новая пустая строка.
4 — вставляем в новую пустую строку следующий текст:
WindowFunc_HSLMode = «HSL-Mode»
5 — ищем цепочку символов (вместе с кавычками):
«Status Bar (&U)»
6 — сразу после неё нажимаем ввод, появится новая пустая строка.
7 — вставляем в новую пустую строку следующий текст:
WindowMenu_HSLMode = «HSL-Mode (&р)»
8 — ищем строку, содержащую DlgJpgSave_Title
9 — меняем DlgJpgSave_Title на DlgJpegSave_Title (добавилась латинская буква «e«)
10 — делаем то же самое для следующих 10 строк
11 — сохраняемся
Ну вот, пожалуй, и весь туториал. Больше настраивать там особо и нечего.
Приятного рисования.
Создание манги в Paint Tool SAI [часть 1] « Мангалекторий
Ещё раз здравствуйте!
Данный урок будет посвящён процессу создания страницы манги или комикса в программе Easy Paint Tool SAI. В своём предыдущем мастер-классе я уже говорила о том, что в SAI нет инструментов для работы с текстом, поэтому оставим эти вопросы для других программ, таких как, например, Adobe Photoshop или Adobe Illustrator.
В своём предыдущем мастер-классе я уже говорила о том, что в SAI нет инструментов для работы с текстом, поэтому оставим эти вопросы для других программ, таких как, например, Adobe Photoshop или Adobe Illustrator.
Итак, начнем!
Набросок
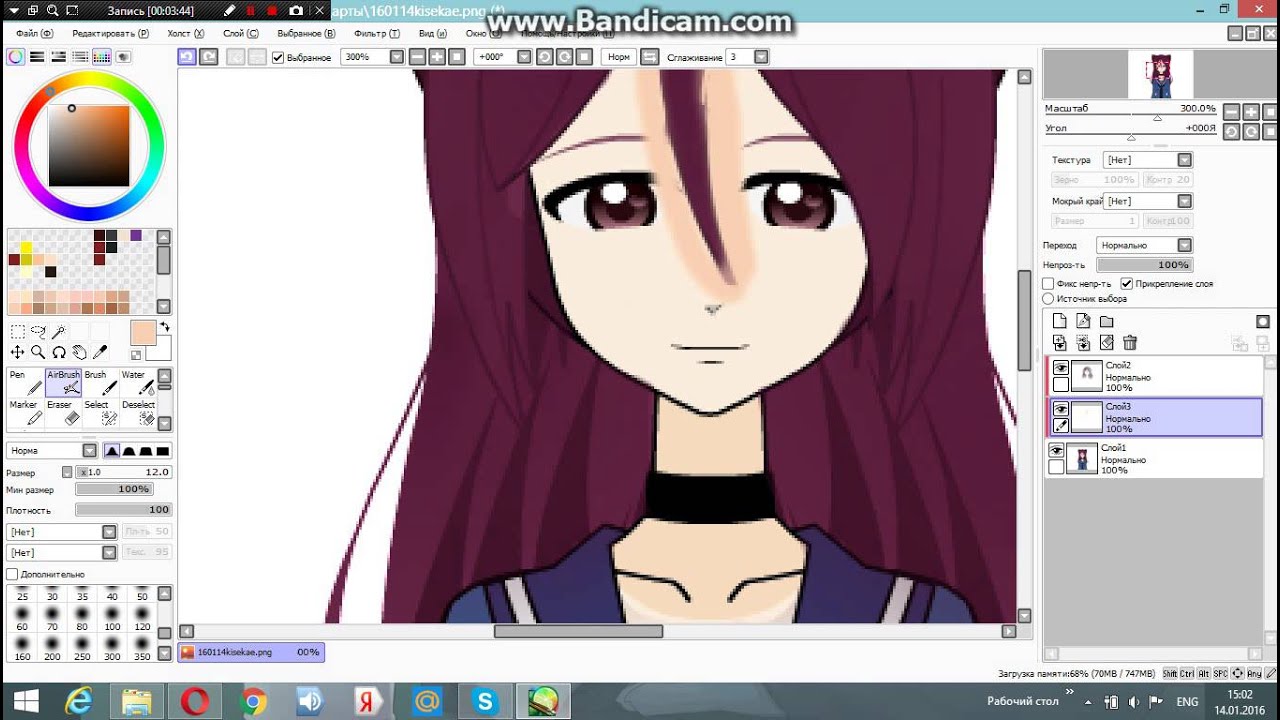
Думаю, самое логичное с чего стоит начать рисовать страницу своей манги — это с создания нового документа необходимого размера =) Далее потребуется набросок. Для его создания я использую инструмент Pen (Карандаш) со следующими настройками (рис. справа):
Сначала создаю примерный набросок. Синий цвет для наброска я использую по привычке, доставшейся мне от работы в программе Manga Studio. Вы же можете использовать любой другой цвет.
Делаю его полупрозрачным, чтобы на втором слое сверху сделать уже более точный набросок. В итоге у меня получилось следующее:
Видео-бонус по созданию наброска:
Раскадровка
Далее приступаю к делению страницы на кадры. Для этого я выберу самый легкий из способов — cоздам New Linework Layer (новый векторный слой):
Для этого я выберу самый легкий из способов — cоздам New Linework Layer (новый векторный слой):
Инструментом Line (Линия) провожу полосы 30 размера. Получается вот такая страница:
Остаётся сделать ещё одну рамочку. Для этого я создаю новый слой. С помощью инструмента
Далее захожу в меню на вкладку Selection (Выделение) и выбираю Invert (Инвертировать). Полученный рисунок я заливаю чёрным цветом с помощью инструмента Bucket (Заливка) со следующими настройками (рис. справа):
Остаётся только объединить два слоя и мы получим готовую раскадровку. Если вас не устраивает такая простая раскадровка, то следует обратиться к Adobe Photoshop или к другой программе для рисования, которая будет вам удобна.
Видео-бонус по созданию раскадровки на чёрном фоне:
youtube.com/embed/ecwoLO98kkU" allowfullscreen="" frameborder="0">
Видео-бонус по созданию раскадровки на белом фоне:
Контур
Для создания чёрно-белого контура мне понадобилось Binary Pen (Двоичное перо). Найти его можно, нажав правой кнопкой мышки по свободной клетке в меню. Появится список инструментов, которые можно добавить к стандартным.
Чтобы при рисовании получился чёткий контур, я выбрала для Двоичного пера следующие настройки:
Также мне понадобились Eraser (Ластик ) и Bucket (Заливка).
Теперь делаем набросок (1) и полупрозрачный слой с кадрами (3), а между ними создаём новый слой (2).
Начинаем рисовать на слое (2). Сначала создаём фон. Если вы ещё не использовали инструмент Ластик, то самое время сделать это =)
В итоге у меня получается фоновое изображение без персонажей. Я это делаю исходя из того, что потом планирую раскрасить свою страничку и сделать фон менее насыщенным, но об этом чуть попозже.
Я это делаю исходя из того, что потом планирую раскрасить свою страничку и сделать фон менее насыщенным, но об этом чуть попозже.
Когда фон готов, я отключаю отображение этого слоя и создаю над ним новый, предназначенный для персонажей и переднего плана. Всё это я рисую теми же инструментами: Двоичное перо (Binary Pen), Ластик (Eraser) и Заливка (Bucket). В итоге получается следующее:
Пока не понятно, что и где. Для того чтобы этот бардак превратился в ясный рисунок следует:
- Вытереть ненужные части фона у персонажей.
- Создать ещё один слой между фоном (2) и героями(3) и залить его белым цветом. Лично я выбираю этот метод, так как эти заливки мне понадобятся при покраске.
Затем отключаю слой с фоном, создаю под ним новый слой и заливаю его серым цветом:
И опять же, используя Двоичное перо, Ластик и Заливку (см. настройки превью), создаю на отдельном слое белые заливки для персонажей:
После удаления лишних слоёв возвращаю параметр Opacity (Прозрачность) на 100% и у меня получается вот это:
Видео-бонус по созданию контура:
youtube.com/embed/HrXQ0pYxJjs" allowfullscreen="" frameborder="0">
Мелочи
После того как основная часть работы завершена, можно заняться мелочами. С помощью Ластика убрать пробел между кадрами, если в каком-то месте ваш рисунок выходит за рамки кадра.
Добавить звуки. Для этого на отдельном слое рисуем звуковые эффекты.
Ещё можно сделать белую обводку на слое ниже, чтобы персонажи не сливались с фоном.
Видео-бонус по дополнениям:
На этом первый этап работы закончен!
Часть 2 >>
Автор: EkaGO
Филлис Кристал — Саи Баба (Первое знакомство) читать онлайн
Кристал Филлис
Саи Баба (Первое знакомство)
Филлис Кристал
САИ БАБА
ПЕРВОЕ ЗНАКОМСТВО
Филлис Кристал — дипломированный психотерапевт школ Юнга и Эриксона.
Посвящается Шри Сатья Саи Бабе
ПРЕДИСЛОВИЕ
Почему я взялась за эту трудную задачу написать книгу о Саи Бабе? Это действительно требует мужества, и одна я никогда бы не помышляла взяться за книгу по собственной инициативе. Как может обыкновенный человек судить о такой многогранной личности, которую считают божественным ~Аватаром|? Я, вне всякого сомнения, не чувствовала себя достаточно компетентной сделать это.
В течение последних двадцати пяти и более лет я была вовлечена во внутренний поиск смысла жизни, применяя методику медитации, которую можно уподобить визуализации или мечте. Результатом этого поиска является метод, состоящий из серии визуальных упражнений и символов. Их можно использовать в индивидуальных беседах, а также предоставлять отдельным лицам, чтобы они самостоятельно занимались ими в уединении своего собственного дома.
Их можно использовать в индивидуальных беседах, а также предоставлять отдельным лицам, чтобы они самостоятельно занимались ими в уединении своего собственного дома.
Множество людей, с которыми я работала таким методом, убеждали меня написать книгу об этом методе. Однако, я была слишком занята его применением в дополнение к моей роли жены и матери, чтобы найти время и посвятить себя этой задаче. Более того, я никогда не испытывала ни малейшего желания стать писателем. Я твердо верила, и не жаждала ничего другого. Однако настойчивость тех, кто извлек пользу из моего метода, возросла до такой степени, что я, наконец, согласилась попробовать изложить ее в форме книги и довести до широкой аудитории.
Когда я принесла законченную рукопись Саи Бабе, чтобы попросить Его благословения, то спросила у Него разрешения добавить в конце главу о Нем. Вместо этого, к моему удивлению, Он предложил мне написать отдельную книгу о Нем.
Много книг о Бабе и Его учении, чудесах и исцелениях написано гораздо более опытными писателями.
Баба говорит о себе, что является божественным ~Аватаром|, который явился в мир в это время великого напряжения, чтобы помочь человечеству вновь познать древнюю мудрость,с помощью которой можно отвратить беду. Другие божественные «Аватары», такие как Рама и Кришна, аналогичным образом принимали человеческое подобие в прошлые периоды чрезвычайных кризисов, чтобы помочь людям и направить их по тому же пути. Первоочередная и поставленная Им самим задача Бабы -сначала обучить людей своей родной Индии и вновь связать эту страну и ее народ с древним наследием ведических доктрин, которым пренебрегли в пользу материалистических аспектов западной культуры и обычаев. Он также милостиво простирает Свою любовь и внимание на людей всего мира, которые нашли свой путь к Нему.
В этом миниатюрном отчете о моем собственном, очень личном опыте общения с Бабой я рассказал о Его многочисленных, разнообразных ролях как мудрого учителя и духовного ~гуру|, как любящего родителя — отца и мать в одном лице, как друга и утешителя, исцелителя и психолога. Кроме того, я попыталась показать Его многочисленные макрокосмические грани как дипломата и организатора, советчика и воспитателя, а также, и прежде всего, как всемирного лидера.
Кроме того, я попыталась показать Его многочисленные макрокосмические грани как дипломата и организатора, советчика и воспитателя, а также, и прежде всего, как всемирного лидера.
Есть много людей, которые способны намного лучше представить Его многогранную личность и наполненную деятельностью жизнь, так как они когда-то ежедневно находились в Его непосредственном окружении в течение длительных периодов. Такая тесная близость позволяла им наблюдать за Ним во всех возможных обстоятельствах и вместе с тысячами разных людей. Многие знали Его с тех пор, как Он был ребенком, и наблюдали за Его развитием годами.
Я посещала Его лишь на короткие периоды с годичными интервалами. Однако, оглядываясь назад на те кратковременные посещения, я виду, как вырисовывается картина, раскрывающая метод, который Он применял, чтобы обучить меня. Эта картина отражается также в более обширном плане, который Он составил, чтобы приступить к выполнению мировой задачи в это неспокойное время истории и эволюции мира. Так как мир населен отдельными людьми, оба подхода необходимы для того, чтобы этот план стал зримым и действующим.
Так как мир населен отдельными людьми, оба подхода необходимы для того, чтобы этот план стал зримым и действующим.
Для того, чтобы настоящий отчет имел смысл, он должен обязательно касаться моего личного опыта, поскольку этот опыт является основой всего, что удалось узнать о Нем. Хочу, однако, подчеркнуть, что моим твердым намерением было, прежде всего, представить Его и Его учение со ссылкой только на саму себя потому, что через Его влияние на мою жизнь можно мельком увидеть, как в окне или в зеркале, влияние, которое Он оказывает на жизнь всех, кто ищет Его помощи.
Моя надежда заключается в том, что многие люди, которые прочтут эту книгу, почувствуют тягу к Бабе и Его учению и пожелают присоединиться к Его последователям, чтобы способствовать выполнению Его миссии в этом беспокойном мире. Однако необязательно находиться с Его физической формой в Индии, и Его не так легко найти, поскольку Он заявил, что удалится из поля зрения общественности. С этим решением перекликается одно из Его самых последних посланий «Внутренний путь, а не разговоры». Другими словами, каждый, кто готов и хочет сделать попытку, может непосредственно установить контакт внутри себя с той искрой Божественного, присущего каждому и любому живому существу. Я надеюсь показать, как этого можно достичь.
Другими словами, каждый, кто готов и хочет сделать попытку, может непосредственно установить контакт внутри себя с той искрой Божественного, присущего каждому и любому живому существу. Я надеюсь показать, как этого можно достичь.
SAI Note Manager — Scribe
Центральный узел для обработки сносок и концевых сносок.
С помощью диспетчера заметок SAI вы можете находить проблемы с заметками, изменять настройки заметок документа и преобразовывать встроенные заметки в заметки с обычным текстом.
Настоятельно рекомендуется устранить любые предупреждения об активных заметках на вкладке заметок перед преобразованием заметок.
Преобразование и настройки примечаний
Параметры преобразования примечаний и нумерации могут быть изменены одновременно, хотя также возможно изменить параметры нумерации примечаний без преобразования примечаний и преобразовать примечания без изменения параметров нумерации примечаний.Преобразование можно запустить для активного файла или файлов, выбранных из каталога. При запуске для выбранных файлов преобразованный файл будет сохранен как отдельный файл в том же каталоге. При преобразовании встроенных заметок в несвязанный текст новое имя файла будет заканчиваться на -postnotestrip. При преобразовании из обычного текста во встроенные заметки новое имя файла будет заканчиваться на -prenotestrip.
При запуске для выбранных файлов преобразованный файл будет сохранен как отдельный файл в том же каталоге. При преобразовании встроенных заметок в несвязанный текст новое имя файла будет заканчиваться на -postnotestrip. При преобразовании из обычного текста во встроенные заметки новое имя файла будет заканчиваться на -prenotestrip.
Параметры нумерации примечаний
Задайте глобальные параметры нумерации примечаний для выбранного документа или документов. Чтобы обновить, установите флажок для обновления сносок или концевых сносок, а затем выберите способ нумерации примечаний.
Добавить разрывы разделов перед стилями глав ScML. : Вставляет разрывы разделов Microsoft Word в местах, где должна располагаться каждая глава, на основе стилей абзацев ScML. Это позволяет перенумеровать встроенные концевые и сноски Word для каждой главы. Этот инструмент также можно использовать с функцией «Разделить документ» для вывода одного файла на каждую главу книги.

Добавить заголовки для каждой главы в примечаниях. : Вставляет заголовки в диапазоны концевых сносок, соответствующие информации главы, взятой из стилей ScML заголовка главы.Разрывы разделов должны быть добавлены в документ при каждом разрыве главы перед запуском. Вставит информацию из ctfm, ctbm, ct или cn, если таковая имеется. Если секция концевых сносок содержит старые заголовки, выберите удалить текущие заголовки , чтобы удалить заметки перед добавлением новых. Выберите шаблон текста для заметок, которые нужно сделать, когда глава содержит и название, и номер главы. Полученные головки следует проверить, чтобы убедиться, что узор соответствует спецификации вашего проекта.

Параметры преобразования встроенного / обычного текста примечания
Преобразует встроенные концевые сноски и сноски Word в / из обычного текста. Поскольку встроенная функция заметок Word позволяет автоматически изменять нумерацию заметок при внесении изменений, Scribe рекомендует использовать заметки Word в процессе создания и редактирования.
- Используйте флажки, чтобы указать, должно ли преобразование происходить в концевых сносках, сносках или и в том, и в другом.
- Выберите, хотите ли вы преобразовать встроенные текстовые заметки в обычный текст или простые текстовые заметки во встроенные заметки.
- Выберите, хотите ли вы преобразовать встроенные текстовые заметки, расположенные в таблицах, в текстовые tn абзацы, расположенные сразу после таблицы. Это не может быть отменено.
- При преобразовании встроенных заметок в простой текст выберите форматирование, которое будет применяться к номерам заметок.
- [ссылка]. [Табуляция] : номер примечания будет преобразован в номер примечания, за которым следует точка и табуляция перед текстом примечания.
- [tab] [refnum]. [Tab] : номер примечания будет преобразован в табуляцию, за которой следует номер примечания, за которым следует точка и еще одна табуляция перед текстом примечания.

Предупреждения о примечаниях
На этой вкладке отображаются предупреждения о примечаниях, которые необходимо исправить перед загрузкой в концентратор или перед преобразованием примечаний в SAI. Параметры в «Найти. . . » фрейм найдет проблемные экземпляры, в то время как фрейм «Изменить выбранное примечание» применяет исправление к выделенному тексту или примечанию.
Найти: enref / find стиль символа на немаркерах
Исправление: Применить шрифт абзаца по умолчанию к выделенному тексту
Описание: Параметр становится активным, когда стиль ссылки примечания (
Найти: встроенная заметка без маркера заметки
Исправление: Вставить маркеры заметки (перезаписать первое слово, если число)
Описание: Параметр становится активным, если в документе есть встроенная заметка без символа маркера заметки в примечании.Проблема обычно возникает, когда пользователь Word удаляет встроенный номер заметки. Word не удаляет , а не соответствующую ссылку на заметку, что создает проблемы с сопоставлением заметок, которые трудно решить и которые могут вызвать проблемы в концентраторе. Эта опция поиска выберет заметку (автоматически выберет первое слово в заметке). Соответствующее исправление добавит необходимый маркер заметки в начало первого абзаца заметки. Если выбранный текст представляет собой число (например, повторно вставленный вручную маркер сноски), этот текст будет удален перед добавлением маркера примечания.
Найти: маркер заметки с использованием настраиваемого маркера
Исправление: Преобразовать настраиваемый маркер во встроенный маркер заметки
Описание: Параметр становится активным, когда в документе используется заметка, которая имеет параметр «настраиваемая отметка». Использование этой функции Word может вызвать непредвиденные проблемы с встраиванием заметок. Соответствующий параметр исправления заменяет пользовательский маркер обычным встроенным маркером заметки.
Использование этой функции Word может вызвать непредвиденные проблемы с встраиванием заметок. Соответствующий параметр исправления заменяет пользовательский маркер обычным встроенным маркером заметки.
Paint Tool Сай против Photoshop
Photoshop или Paint Tool Сай, какой из них лучший инструмент для редактирования фотографий? Среди заядлых пользователей редактирования фотографий по этому поводу ведутся долгие споры.Но у нас не будет дебатов. В этой статье мы узнаем о двух самых известных инструментах для редактирования фотографий, инструменте рисования сай и фотошопе. Кроме того, мы изучим особенности, плюсы и минусы и проведем сравнение, чтобы узнать, какой из них наиболее продуктивный и эффективный.
Почему мы должны редактировать наши фотографии?
Когда мы говорим о фотографии, одна вещь, которая автоматически приходит на ум после фотографии, — это редактирование фотографий. Потому что редактирование — важная часть фотографического процесса.Но вы когда-нибудь спрашивали себя, почему вы должны всегда редактировать свои фотографии? Итак, вот несколько причин, по которым мы собрались.
Изображения всегда требуют обработки. Либо камера это делает, либо вы. или это делает камера. Когда камера захватывает изображение, какой бы формат вы ни выбрали, камера принимает его как файл формата «RAW» при первом снимке. После этого камера обработает файл RAW. Камера автоматически добавляет насыщенность, применяет шумоподавление и контраст, применяет резкость, а также некоторые другие функции.Затем камера выравнивает файл и обрабатывает его в желаемом формате файла. Напротив, мы тоже можем обработать фото. С камеры мы можем снимать фото в формате RAW, и камера не делает никакого редактирования. После этого мы можем применить насыщенность, контраст и резкость в соответствии с нашими предпочтениями.
Редактирование дает второй шанс исправить это. Потому что, когда вы делаете снимок камерой, качество снимка иногда не на должном уровне, даже если мы стремимся получить лучший снимок.Редактирование дает нам возможность редактировать любой формат, такой как JPEG, PNG, RAW, в соответствии с нашими предпочтениями.
Еще одна причина для редактирования фотографии — рассказать зрителям свою историю более понятной. Потому что иногда камера неточно отражает момент. Либо мы неправильно настроили камеру, либо не смогли полностью передать настроение в камере. Итак, редактирование дает нам возможность вернуть их в изображение.
Редактирование помогает развить свой собственный стиль. Это не всегда стиль изображения и фона, это нужно для того, чтобы внести свой собственный стиль.Редактирование позволяет миру узнать ваш взгляд на мир. Когда вы экспериментируете с новым стилем, ваше обучение редактированию изображения будет процветать.
Зачем нужны инструменты для редактирования фотографий?
Редактировать фото иногда легко, но большую часть времени это сложно. Чтобы получить невероятное фото, нам просто нужен мощный инструмент для редактирования. Инструменты редактирования фотографий могут предоставить всевозможные функции редактирования. Фактически, все профессионалы в области графического дизайна и редактирования фотографий используют различные инструменты для редактирования фотографий для обслуживания клиентов.Инструменты для редактирования фотографий, способные обеспечить автоматическое улучшение изображения, сжатие данных, возможность выбора изображения, использование слоя, изменение размера изображений, обрезку изображений и многое другое. Фактически, все профессионалы редактирования фотографий используют по крайней мере один или даже несколько инструментов редактирования изображений для различных целей. Давайте поговорим о двух наиболее известных инструментах для редактирования фотографий: Paint Tool Sai и Photoshop.
Paint Tool Сай против PhotoshopPaint Tool Sai: Paint Tool SAI — это самая простая и легкая программа для рисования.Его функции очень просты, в нем есть те инструменты, которые только связаны и важны для рисования или художественных работ. Функции легко настраиваются, всего лишь двойной щелчок мышью. Кроме того, у него есть хороший селектор кистей, где вы можете легко изменить размер, цвет, поток и вес кистей. Он имеет расширенную функцию выбора цвета, такую как цветовое колесо и шестнадцатеричные коды. Этот инструмент дает вам хорошую свободу рисования.
Основные характеристики
- Имеет полную поддержку графических планшетов
- Расширенная цветовая палитра и выбор цвета
- Базовые наборы кистей с индивидуальной настройкой
- Многочисленные инструменты для профилирования
- Управление уровнями
- Управление файлами
Плюсы :
- Очень простое и легкое программное обеспечение с легко распознаваемыми функциями.
- Легко настраиваемые инструменты. Вы можете легко переименовывать инструменты и создавать ярлыки.
- Он совместим со многими распространенными форматами цифрового искусства, но не в такой степени, как Photoshop.
- Лучшие возможности выбора, чем в Photoshop. Инструменты фиксации линий слоя
- Lineart работают эффективно, исправляя мелкие детали линий, а также создают изменяемые векторы.
- Это очень популярное программное обеспечение среди людей, которые рисуют или рисуют стили аниме или манга.
Минусы:
- В этом программном обеспечении нет инструмента или функции для добавления текста.
- Свет, цвета и тени изменить нелегко.
- Количество встроенных щеток ограничено. Но вы можете творить самостоятельно.
- Чтобы сделать последние штрихи рисунка или добавить текст, люди должны использовать Photoshop рядом с инструментом рисования sai.
- Поддерживает только английский язык.
Photoshop
Photoshop — это наиболее часто используемое программное обеспечение во всем мире для создания художественных работ, редактирования фотографий и графики. Он построен с множеством инструментов и функций для художественных работ, а также для редактирования фотографий.Это, вероятно, самый мощный инструмент для работы с фотографиями, где вы можете настраивать инструменты и кисти, вы можете использовать блендер, создавать слои и маски, добавлять текст, изменять цвета, настраивать свет и тени в соответствии с вашими предпочтениями, исправлять небольшие окончательные детали ваших работ. и многое другое.
Характеристики
- Доступны различные инструменты формы, заливки, линии и градиента.
- Имеет расширенный селектор цвета.
- Создание и управление слоями
- Множество различных настраиваемых кистей.Вы также можете создать свою собственную кисть.
- Широкий набор инструментов для редактирования и выделения.
- Возможность импорта текстур и узоров.
- Он поддерживает различные языки.
Плюсы:
- Очень изобретателен для рисования и рисования.
- Вы найдете все возможные возможности для рисования или редактирования фотографий в Photoshop.
- Вы можете создавать свои собственные ярлыки и изменять настройки по умолчанию, чтобы сэкономить ваше время.
- Отсканированные чертежи легко редактировать.
Минусы:
- Из-за множества функций, поначалу вы можете напугать, вам понадобится много терпения и времени, чтобы научиться.
- Photoshop нужен самый быстрый компьютер из-за большого количества ресурсов.
Кто лучший игрок?
Очень сложно вынести вердикт, кто лучший. Потому что у каждого есть своя уникальная личность.
Paint Tool Sai в основном предназначен для рисования и создания цифровых произведений искусства.Он в основном подходит для тех, кто увлекается рисованием, даже если у него ограниченные функции в отличие от Photoshop. для работы на профессиональном уровне.
С другой стороны, Photoshop предназначен как для профессионалов, так и для любителей. Он подходит для графических дизайнеров, веб-дизайнеров и цифровых художников. Вы можете широко использовать его для печати.
По сравнению с инструментом Paint Sai, Photoshop выигрывает в игре благодаря множеству функций, которые привели к максимальному удовлетворению запросов пользователей.
Заключение
Итак, это сравнение двух замечательных программ для редактирования фотографий.Сделать вывод, какой из них лучше, непросто. Потому что взаимодействие с пользователем может отличаться. Не стоит ограничиваться вердиктами профессиональных пользователей. Вы должны выбрать подходящий в зависимости от ваших потребностей.
Скачать PaintTool SAI для Windows
SAI — это программа, предназначенная для создания и редактирования произведений искусства. Он ориентирован на живопись и рисунок и предлагает уникальное качество и продуманные инструменты, которые помогут вам раскрыть свой творческий потенциал.
Дайте волю художнику в пределах
Выберите из ряда цветовых шаблонов, которые превратят ваши рисунки в более профессионально выглядящие произведения.
Дайте волю своему творчеству с этим профессиональным программным обеспечением для рисования и рисования. Вы можете создавать потрясающие цифровые изображения с помощью различных инструментов, которые помогут вам разработать и довести до совершенства свою работу. Смешайте цвета в палитре и получите идеальный оттенок для своих работ.
Используйте перо, акварель, аэрограф и ластик, чтобы улучшить свои рисунки. Каждый из них может быть настроен на ваш предпочтительный размер и мягкость. Вы также можете изменить давление вашего инструмента для рисования, чтобы создать вариацию линий, которые вы рисуете.Есть множество уникальных способов использовать предоставленные вам инструменты. Сохраните предпочтительные настройки и используйте их в следующем сеансе рисования или откажитесь от них и создайте что-нибудь новое.
SAI отстает от других программ для графического дизайна, но имеет очень ограниченные инструменты для редактирования фотографий. Вы можете изменить яркость, контраст, оттенок и насыщенность на импортированных фотографиях, но приложение идет только до этого. Важно помнить, что программное обеспечение не предназначено для всестороннего редактирования графики, поскольку основное внимание уделяется рисованию и рисованию.
Где можно запустить эту программу?
SAI доступен только для настольных компьютеров и планшетов Windows, работающих в операционных системах Windows.
Есть ли лучшая альтернатива?
Это программное обеспечение обладает впечатляющими возможностями для заядлых художников, которые хотят создавать цифровые произведения. Он явно ориентирован на рисование и живопись, но ему не хватает других функций графического дизайна. Вы можете попробовать FireAlpaca для получения дополнительных инструментов для редактирования фотографий и доступности из других операционных программ.
Наш дубль
SAI дает художникам кисть и дает им больше контроля над своими творениями.Он имеет большое внимание к деталям и предлагает высококачественную графику.
Стоит ли его скачать?
Да. Если вы хотите поиграть с их инструментами для рисования и палитрами, SAI — хороший вариант. Его стоит скачать, будь вы профессионалом или хотите попробовать свои силы в рисовании. Если вам нужно более интегрированное приложение для графического дизайна, лучше поискать альтернативы.
Скачать PaintTool SAI бесплатно для Windows 10
Как скачать PaintTool SAI бесплатно. Вы ищете инструмент, который упростит вашу работу по редактированию фотографий? Вы хотите проявить свои творческие способности? Вы хотите добавить текст или дополнительную функцию к загруженным изображениям?
С помощью бесплатного фоторедактора PaintTool SAI вы можете легко добавлять детали к изображениям в Интернете и к загруженным. В самом деле, ничто так не приносит удовлетворения, как возможность воспроизвести свое творчество. Итак, если вы всегда хотели добавить изюминку в редактирование и дизайн фотографий, тогда PaintTool SAI — это то, что вам нужно.
PaintTool SAI — это базовый инструмент для рисования фотографий для начинающих. Новички, не знакомые с графикой, могут использовать этот инструмент с минимумом хлопот. С помощью этого инструмента ваши цифровые произведения искусства обязательно улучшатся.
В этом программном обеспечении есть много удивительных и простых в использовании инструментов. Аэрограф, кисть, акварель, карандаши и ластики — все это встроено в этот замечательный инструмент.
Просто выполните переворот фотографии, масштабирование, изменение цвета, насыщенности и оттенка.
В дополнение к основным инструментам существуют другие расширенные инструменты, которые добавят изящные эффекты в вашу работу по редактированию фотографий.Наличие слоев и холстов — одни из очень полезных расширенных инструментов редактирования, доступных в PaintTool SAI.
Связано: CorelDraw Цена, функции и обновления
PaintTool SAI Ключевые особенности.
ВPaintTool SAI очень легко ориентироваться. Интерфейс очень прост в освоении.
Он имеет холст, который является центром основной дизайнерской работы. Все инструменты доступны на холсте. Сюда входят инструменты для рисования и рисования.Инструмент масштабирования доступен для более детального просмотра. Объект также можно повернуть для лучшего обзора целевого участка.
Имеет список слоев. PaintTool SAI позволяет накладывать изображения друг на друга. Слои используются для наложения изображений друг на друга. Порядок изображений можно легко изменить в списке. С помощью этого инструмента можно добиться смешивания изображений и теней.
Раздел «Эффекты рисования» позволяет создавать различные эффекты рисования на слоях изображения.Некоторые из эффектов рисования включают «множественные эффекты» для пропуска цветов слоев и «эффекты наложения» для смешивания цветов нижележащих слоев.
Еще одна замечательная функция PaintTool SAI — это инструменты рисования. Инструменты рисования очень важны для создания графики и рисования идей. Некоторые из доступных инструментов рисования включают инструмент «Перо», инструмент «Аэрограф», инструмент для создания эскизов и т. Д. Эти инструменты доступны для дизайна холста. Размер, плотность и текстуру изображений также можно регулировать.
| Минимальные требования | |||||||||
| Компьютер | PC / AT (не виртуальная машина) | ||||||||
| ОС | Windows 98 Windows 2000 / XP / Vista / 7/8 / 8.1 / 10 * Будет работать на 64-битной Windows | ||||||||
| ЦП | Pentium 450 МГц или новее (требуется поддержка MMX) | ||||||||
| Системная память (RAM) |
| ||||||||
| Жесткий диск | 512 МБ свободного места | ||||||||
| Графическая карта | Разрешение 1024 × 768, экран «32-битный True Color» | ||||||||
| Опорное устройство | Дигитайзер, совместимый с Wintab, с поддержкой давления | ||||||||
Этот удивительный инструмент можно бесплатно загрузить с веб-сайта PaintTool SAI.Его можно использовать в Windows и Mac. Для загрузки просто выполните следующие действия:
- Посетите https://www.systemax.jp/en/sai/
- Прокрутите страницу вниз. Когда вы найдете кнопку загрузки, просто нажмите ее, чтобы начать загрузку.
Кроме того, вы также можете бесплатно загрузить PaintTool SAI, посетив http://en.softonic.com/download/painttool-sai/windows
Вы найдете кнопку загрузки, просто нажмите на нее, чтобы загрузить.
Связано: 10 лучших программ для графического дизайна для дизайнеров
Спасибо, что прочитали этот пост.Просто используйте поле для комментариев, чтобы внести свой вклад в этот пост. Нажмите кнопку «Поделиться», чтобы поделиться публикацией с друзьями.
SketchBook против PaintTool SAI: какое программное обеспечение лучше?
Сравните SketchBook с PaintTool SAI, чтобы понять, какая программа будет лучшим выбором для каждого конкретного случая задачи рисования.
SketchBook , несомненно, одна из лучших программ для рисования для художников и любителей, которая поставляется с мощным редактором рисования и эскизов, упрощающим работу с изображениями и иллюстрациями.
PaintTool SAI — это отмеченное наградами программное обеспечение профессионального уровня для редактирования и рисования растровой графики для операционных систем Microsoft Windows.
Окончательный вердикт:
SketchBook предлагает профессиональным художникам высококачественный продукт, который позволяет им не только редактировать эскизы, но и создавать уникальные и индивидуальные изображения с нуля. Программное обеспечение позволяет создавать слои, добавлять текст, изменять цвет, смешивать фотографии, компьютерные дизайны и многие другие функции.
SketchBook — победитель>
Характеристики SketchBook:
- Параметры сканирования камеры
- Поддержка нескольких форматов
- Настраиваемые кисти
- Библиотека цветов
- Коллекция карандашей
Что такое SketchBook?
Функции рисования, поддерживаемые Autodesk SketchBook, улучшены исключительной простотой использования приложения для рисования, превосходным и интуитивно понятным пользовательским интерфейсом, широким разнообразием шаблонов и тем, богатым выбором кистей и опций для цвета, жесткости, толщины линий и ширины штриха. , и различные дополнения функций.
Одним из вариантов рисования программы является прогнозирующая разметка штрихов. Эта функция использует усовершенствованный алгоритм искусственного интеллекта, чтобы предсказать, где на экране художник будет рисовать мазок. Это экономит время, потому что SketchBook может предложить художнику наиболее эффективное место для рисования определенного мазка, не требуя от него угадывать или оглядываться.
Еще одна полезная функция Autodesk SketchBook Pro — функция автоматической трассировки, которая предназначена для автоматического обведения линий в эскизе, чтобы пользователю не приходилось так осторожно рисовать линии.С помощью этого программного обеспечения рисование эскизов становится проще и быстрее, а весь процесс можно завершить за несколько минут.
Что такое PaintTool SAI?
PaintTool SAI нацелен на то, чтобы подготовить картины для лучшей демонстрации и продвижения цифрового искусства в сети. Вы можете использовать это программное обеспечение, чтобы получить желаемые результаты более эффективно, чем раньше. Этот SAI также позволяет вам легко переключаться между различными уровнями инструментов редактирования изображений, и когда вы закончите, вы увидите предварительный просмотр в виде холста, показывающий все внесенные вами изменения.
Он предоставляет различные полезные функции, в том числе импорт, сохранение и редактирование кистей, параметры объема и наложения, несколько размеров холста и различные эффекты. В программе есть большая библиотека из тысяч текстур, мультяшных рисунков, инструментов для ретуши и многого другого. Он прост в использовании, а руководства содержат пошаговые инструкции, помогающие пользователям пройти каждый этап.
Программа имеет расширенную версию пера, которая позволяет рисовать линии и карандаши, а также ряд других специальных инструментов.Он также поставляется с расширенной версией Photoshop «paint», которая дает вам почти те же функции Photoshop, только немного более упрощенные для пользователей SAI.
Сравнение:
Эскизы
МАСЛЯНЫЙ ИНСТРУМЕНТ SAI
Характеристики SketchBook и PaintTool SAI:
- Чернила эффекты
- Неограниченное количество слоев
- Различные режимы наложения
- Интуитивно понятный интерфейс
- Оцифровка бумажных чертежей
- Слои навигации
- Полный цветовой спектр
- Карандашные инструменты
- Регулировка насыщенности цвета
- Поддержка технологии Intel MMX
SketchBook и PaintTool SAI Цена:
| НАЧАЛЬНАЯ ЦЕНА | $ 4.99 / мес | 52,00 $ / одна покупка |
| БЕСПЛАТНЫЙ ПРОБНЫЙ ПЕРИОД |
Кросс-платформенный:
Поддержка:
Выбор FixThePhoto:
SketchBook — один из самых популярных инструментов для рисования и эскизов для архитекторов, художников и других творческих людей, в том числе дизайнеров интерьеров, концептуальных дизайнеров и художников-графиков.
PaintTool SAI может быть наиболее часто используемой художественной программой как художниками, так и специалистами. Благодаря нескольким инновационным инструментам он стал одной из самых популярных программ для рисования как для новичков, так и для профессионалов.
Анализ настроенийна Swachh Bharat с использованием Twitter | by Siva sai
Анализ настроений позволяет выявить восприятие людьми определенной проблемы, бренда, схемы и т. д., (тональность) из текстовых данных. Он имеет широкий спектр приложений, от мониторинга бренда и анализа продуктов до разработки политики. В этой статье мы проводим анализ тональности твитов с хэштегом Swachh Bharat. Полный код этого проекта доступен здесь.
Эта статья разделена на следующие части.
- Различные подходы к выполнению анализа тональности
- Сбор данных
- Преобразование полезных данных в CSV
- Удаление повторяющихся строк и ненужных столбцов
- Очистка твитов
- Удаление стоп-слов
- Лемматизация и построение стержней
- Визуализация данных
- Векторизация текст твитов
- Реализация классификаторов из sklearn
- Реализация моделей Gensim
- Резюме
Существует два основных подхода к выполнению подхода на основе анализа тональности на основе лексики или с использованием моделей машинного обучения.Любой подход, основанный на лексиконе, в основном использует словарь слов с присвоенными им семантическими баллами для расчета окончательной полярности твита. Например, рассмотрим предложение «Мне нравится этот фильм, хотя вторая часть немного медленная». Теперь каждому из таких слов будет присвоена (общая) оценка тональности.
«Я: 0, любовь: 0,750, это: 0,0, фильм: 0,0, хотя: 0,0, 0,0 секунды: 0,0, часть: 0,0, это: 0,0, скучно: -0,250»
Положительный результат означает, что слово положительное, а отрицательный результат означает отрицательный.Теперь, если мы сложим все оценки для этого предложения, получится -0,500, что является положительным мнением. Таким образом, твит будет отмечен как положительный. Доступны несколько важных ресурсов лексики: SentiWordNet, TextBlob, Afinn, MPQA (многоперспективный ответ на вопрос) Лексика субъективности и шаблон. Я использовал этот словарный подход, используя SentiWordNet для маркировки моих твитов (объяснено позже).
Второй подход, машинное обучение, решает проблему как задачу классификации текста с использованием классификаторов после предварительной обработки данных.Мы следуем второму подходу, который будет подробно объяснен.
Относительно инструментов, необходимых для этой задачи
Существует множество библиотек для обработки текста и классификации — NLTK (комплексная и сложная кривая обучения), TextBlob (простой в использовании, подходит для новичков), Spacy (идеально подходит для промышленности. работа) и многое другое. Я выбрал NLTK, потому что он предоставляет множество вспомогательных библиотек для реализации многих методов обработки текста
Давайте начнем!
Теперь мне нужны текстовые данные, которые выражают мнение людей о Swachh Bharat.Некоторые доступные варианты используют Reddit API, Facebook API, Twitter API и сбор данных с веб-страниц. Я решил использовать twitter API, чтобы собирать твиты о Swachh Bharat, так как многие считают Twitter большой психологической базой данных. Твиты для этого проекта собираются из базы данных Twitter с использованием библиотеки Tweepy на Python. Чтобы получить доступ к твитам, нужно создать учетную запись разработчика твиттера. Существуют разные типы учетных записей разработчиков: Standard Search (бесплатно), Premium (платно) и Enterprise (платно).Возможности API или доступность увеличиваются со стандартной учетной записи на корпоративную. Например, через стандартную учетную запись вы можете получить доступ к твитам за последние семь дней, в то время как это 30 в случае Premium. Для создания учетной записи вы должны предоставить подробную информацию об основном варианте использования, намерении, бизнес-цели вашего использования, сведения об анализах, которые вы планируете провести, а также о методах или методах. И я советую предоставить как можно больше деталей (можно также добавить ссылки на веб-страницы проекта, похожие на ваш или основную тему проекта, когда вы хотите прояснить ситуацию) с первой попытки, иначе вам придется писать длинные электронные письма с повторным объяснением одного и того же содержания снова и снова на случай, если им понадобится дополнительная информация.Команда Twitter тщательно рассмотрит вашу заявку. Это хорошая статья о Twitter Data Mining.
Обычно получение письма с подтверждением занимает меньше дня при условии, что ваша информация является полной.
После этого вам необходимо создать новое приложение в их интерфейсе и предоставить его описание (как показано ниже), которое генерирует API KEY, API SECRET KEY, ACCESS TOKEN и ACCESS TOKEN SECRET, которые мы будем использовать для входа в систему через терминал.
Создание нового приложенияТеперь давайте аутентифицируем наши данные с помощью tweepy.Функция AppAuthHandler (). Замените «*» своими данными аутентификации.
import tweepy
API_KEY = "*********************"
API_SECRET = "**************** ********* "
ACCESS_TOKEN =" ******************************* "
ACCESS_TOKEN_SECRET =" ***************************** "
auth = tweepy.AppAuthHandler (API_KEY, API_SECRET)
auth.set_access_token (ACCESS_TOKEN, ACCESS_TOKEN_SECRET )
api = tweepy.API (auth)
print (api.me (). Name)
Если аутентификация прошла успешно, вы должны увидеть напечатанное имя вашей учетной записи.
IAmSai
После аутентификации мы готовы загружать твиты. Мы используем метод API.search () для получения твитов. Существует два основных способа поиска твитов с помощью Tweepy-поиск по хэштегу (или ключевому слову) и поиск по идентификатору твита (идентификатор каждого твита уникален). Второй метод полезен, когда у вас есть все идентификаторы твитов, которые нужно собрать (скажем, вы хотите собирать твиты о демонетизации с учетом идентификаторов. Эти идентификаторы будут предоставлены теми, кто ранее собирал данные по этой теме).Поскольку у меня нет идентификаторов, я использую первый метод.
search_query = "# SwachhBharat"
new_tweets = api.search (q = search_query, count = tweetsPerQuery, lang = "en", tweet_mode = 'extended')
auth = tweepy.AppAuthHandler (API_KEY, API_SEC) .API (auth, wait_on_rate_limit = True, wait_on_rate_limit_notify = True)
fName = 'sb_04_08_19.txt' # где я сохраняю твиты
В приведенном выше фрагменте кода дано несколько важных строк кода. Пожалуйста, посмотрите здесь подробный код.
Мы ищем по ключевому слову «#SwachhBharat». Позже, очищая данные, я обнаружил, что твиты с хэштегами — ‘# MyCleanIndia’ и ‘#SwachhBharatUrban’ также могут использоваться для поиска твитов, касающихся Swachh Bharat. Для авторизации API мы используем AppAuthHandler (3-я строка), а не OAuthHandler, который обычно используется. OAuthHandler допускает максимум 180 запросов в 15-минутное окно (и максимум 100 твитов на запрос). Таким образом, мы можем получить только 18 000 твитов за 15 минут. Но AppAuthHandler имеет максимальное ограничение на частоту запросов: 450 и 100 твитов на запрос.Таким образом, он помогает получить 45 000 твитов за пятнадцать минут. Кроме того, я использовал режим расширенного твита (вторая строка), чтобы убедиться, что мы получаем полные твиты, а не усеченные. После загрузки мы сохраним твиты в текстовом файле (в качестве альтернативы мы также можем сохранить их в файле .json). Я повторил описанную выше процедуру еще несколько раз, чтобы собрать большее количество твитов позже (с перерывом более семи дней между двумя сборами данных, иначе мы получим много повторяющихся твитов).
Скачивание твитовЭто была трудная часть для меня изначально, поскольку я никогда не работал с API и JSON.Текстовый файл огромен и содержит около 1100 страниц информации. В sb.txt (текстовом файле) твиты представлены в формате JSON (JavaScriptObjectNotation). Взгляните на него.
Данные заполнены множеством объектов JSON.С первого взгляда вы можете увидеть, что есть много функций (объектов), которые не важны для нашей задачи, например, метаданные, индексы, screen_name. Итак, я просмотрел эту страницу, чтобы выяснить, какие объекты могут мне понадобиться для моей задачи. Я решил выбрать следующие объекты — full_text (полный текст твита), retweet_count (твита), избранное_count (твита), geo (географическое положение), координаты (координаты широты и долготы места), место ( от которого он твитнул), follower_count (пользователя, который твитнул), created_at (время и дата твита), id_str (id твита в строковом формате).Я сохраняю указанные выше объекты в своем CSV-файле, а остальные отбрасываю.
inputFile = 'sb_04_08_19.txt'
tweets = []
для открытой строки (inputFile, 'r'):
tweets.append (json.loads (line))
для твита в твитах:
try:
csvWriter .writerow ([tweet ['full_text'], tweet ['retweet_count'], tweet ['user'] ['followers_count'], tweet ['favour_count'], tweet ['place'], tweet ['координаты']) , tweet ['geo'], tweet ['created_at'], str (tweet ['id_str'])])
count_lines + = 1
за исключением Exception as e:
print (e)
Несколько важных строк кода для преобразования из текстового файла в CSV приведены выше.Пожалуйста, посмотрите это для большей ясности. Мы создаем список твитов, читающих каждую строку из файла (1-й цикл for). Затем мы используем csvWriter.writerow () для записи необходимой информации в файл CSV для каждого твита. И мы собираем только упомянутые выше предметы.
Попробуем загрузить CSV-файл в Jupyter Notebook. Важно установить параметр кодировки как «unicode_escape» в функции read_csv (), поскольку некоторые твиты также состоят из эмодзи и могут затруднить использование кодировки по умолчанию.
импортировать панды как pd
df = pd.read_csv ('somall.csv', encoding = 'unicode_escape')
df.head (5)
Посмотрите на вывод.
Давайте посмотрим и удалим повторяющиеся строки, если они есть. Есть два типа дубликатов-дубликатов с одинаковыми значениями для всех столбцов (это дублирование происходит, когда одни и те же твиты снова собираются сборщиком твитов) и дубликаты с одинаковым текстом для твитов (это происходит, когда два или более пользователей публикуют один и тот же твит. )
print (len (df.index)) # 14195
serlis = df.duplicated (). Tolist ()
print (serlis.count (True)) # 112
serlis = df.duplicated (['full_text']). tolist ()
print (serlis.count (True)) # 8585
Мы видим 112 повторяющихся строк и 8585 строк которые дублируются в column-full_text, а row-duplicates — это подмножество full_text-duplicates. Итак, мы отбрасываем все повторяющиеся строки.
df = df.drop_duplicates (['full_text'])
Изначально я не заметил дубликатов. Таким образом, когда используются текстовые классификаторы, они дают мне высокую точность до 99.54%, что не очень хорошо.
Кажется, некоторые функции, такие как «место» и «гео», имеют в качестве значений больше не числа (NaN). Давайте проверим, сколько пустых строк существует в некоторых выбранных столбцах
print (df ['geo']. Isna (). Sum ())
print (df ['place']. Isna (). Sum ())
print (df ['координаты']. isna (). sum ())
Всего в нашем наборе данных 14 195 строк. Мы видим, что 14191 строка гео-столбца пуста. Пустые строки в «месте» и «координатах» также высоки (13951 и 14191). Поэтому мы отбрасываем эти столбцы вместе с «id_str» (который является идентификатором твита), поскольку идентификатор твита для нас не очень полезен.Хотя мы не используем retweet_count, user_followers_count, favourite_count в нашем контексте, мы не отбрасываем их, потому что они могут использоваться для других задач (например, для оценки популярности твита, которая может использоваться для присвоения веса твитам).
df = df.drop (['место', 'координаты', 'geo', 'id_str'], axis = 1)Первые пять строк набора данных после удаления нескольких столбцов
df.head (5)
В тексте твита могут быть ненужные символы, которые не важны для нашего анализа.Итак, давайте продолжим и очистим наши твиты.
Давайте рассмотрим полный текст любого конкретного твита.
полный текст твита в строке номер 22 Как мы видим, некоторые из ненужных текстов и символов, которые необходимо удалить, — это теги username_tags (например, @_WeMeanToClean), символ ретвита (RT), хэштеги (например, #MyCleanIndia), URL-адреса ( например, https://t.co/XK3ZReâ\x80), числа и знаки препинания. Некоторые из значимых хэштегов передают смысл и могут иметь некоторую тональность после того, как слово разделено на полезные части (например, #ILoveSwachhBharat).a-zA-Z] «,» «, txt) #replace hashtags
df.at [i,» full_text «] = txt
Теперь мы видим, что наши твиты выглядят чистыми.
Твит после очисткиМы выполняется с помощью базовой очистки текстовых данных. В алгоритмах машинного обучения, которые мы собираемся реализовать, ‘full_text’ твита действует как переменная-предиктор (другие переменные, которые могут использоваться, — это количество ретвитов, количество избранных, если мы хотим спрогнозировать влияние твита, но в настоящее время это не входит в нашу задачу) .Как очевидно, нам необходимо создать целевые переменные (оценки настроения) для наших данных.Для этого мы используем SentiWordNet. SentiWordNet — это расширенный лексический ресурс, специально разработанный для поддержки приложений классификации настроений и анализа мнений. Он имеет большой корпус английских слов с тегами POS, а также их тональность.
Прогнозирование тональности нескольких слов с помощью SentiWordNet — ПримерSWN дает pos_score и neg_score для каждого слова, как в приведенном выше случае. Чем выше pos_score, тем более позитивным является слово. Мы используем простое линейное суммирование этих оценок (мы складываем pos_score всех слов в твите, чтобы сформировать pos_total, и аналогичным образом получаем neg_total.Затем мы складываем эти два, чтобы получить sent_total) и помечаем предложение как положительное (1), если оно (sent_total) больше 0, отрицательное (-1), если оно меньше 0, и нейтральное (0) в противном случае. Как вы уже догадались, нам нужно найти POS-теги (части речевых тегов) наших твитов, чтобы использовать SWN. Функция pos_tag в nltk помогает нам пометить текст, но она не упрощена (помимо существительного, местоимения, прилагательного, глагола она также помечает текст многими другими тегами, такими как присоединение, союз, определитель и т. Д.). Но SWN принимает только упрощенные теги.Поэтому мы пытаемся упростить теги с помощью функции map_tag из библиотеки nltk.
для i в диапазоне (len (df_copy.index)):
text = df_copy.loc [i] ['full_text']
tokens = nltk.word_tokenize (text)
tagged_sent = pos_tag (tokens)
store_it = [( word, map_tag ('en-ptb', 'universal', tag)) for word, tag in tagged_sent]
Вторая строка преобразует текст твита в токены, которые позже будут помечены соответствующими частями речи. Затем мы сохраняем слова и теги в списке store_it.Этот список впоследствии будет передан для маркировки настроений с помощью SWN.
Теги твита («Движение по осведомленности о разделении отходов от двери до двери было проведено членами nehru yuva kendra в капуртхала пенджабе»), помеченные с помощью pos_tag () и упрощенного POS-тега, представлены ниже.
Отмеченные части речи: [('a', 'DT'), ('door', 'NN'), ('to', 'TO'), ('door', 'VB'), (' отходы ',' NN '), (' сегрегация ',' NN '), (' осведомленность ',' NN '), (' драйв ',' NN '), (' было ',' VBD '), (' выполнено ',' VBN '), (' out ',' RP '), (' by ',' IN '), (' members ',' NNS '), (' of ',' IN '), (' nehru ',' JJ '), (' yuva ',' NN '), (' kendra ',' NN '), (' in ',' IN '), (' kapurthala ',' NN '), (' ' punjab ',' NN ')] Отмеченные части речи - Упрощенное: [(' a ',' DET '), (' door ',' NOUN '), (' to ',' PRT '), (' door ' , 'ГЛАГОЛ'), ('отходы', 'СУЩЕСТВИТЕЛЬНОЕ'), ('сегрегация', 'СУЩЕСТВИТЕЛЬНОЕ'), ('осведомленность', 'СУЩЕСТВИТЕЛЬНОЕ'), ('драйв', 'СУЩЕСТВИТЕЛЬНОЕ'), ('было' , 'ГЛАГОЛ'), ('несёт', 'ГЛАГОЛ'), ('out', 'PRT'), ('by', 'ADP'), ('members', 'СУЩЕСТВИТЕЛЬНОЕ'), ('of' , 'ADP'), ('nehru', 'ADJ'), ('yuva', 'СУЩЕСТВИТЕЛЬНОЕ'), ('kendra', 'СУЩЕСТВИТЕЛЬНОЕ'), ('in', 'ADP'), ('kapurthala' , 'NOUN'), ('punjab', 'NOUN')] Затем мы находим тональность твита с помощью метода, упомянутого выше во введении.Пожалуйста, просмотрите полный код для большей ясности в отношении маркировки настроений. Получив отзывы от SWN, мы добавляем еще три столбца в наш CSV- ’pos_score’, ’neg_score’, ’sent_score’. «Pos_score» твита — это чистая положительная оценка всех слов в твите, и то же самое происходит с «neg_score».
Набор данных после добавления оценки тональности для твитов Значение 1 присваивается для положительного твита (pos_score> neg_score), 0 для нейтрального твита (pos_score = neg_score) и -1 для отрицательного твита (pos_score Пропорция количества твитов от каждого настроения в каждом классификаторе является постоянной, что дает нам больше уверенности в оценке настроений.Кроме того, мы можем сделать вывод, что большинство твитов положительные. Теперь мы закончили с пометкой тональности, мы подготовим наши текстовые данные для дальнейшей подачи в классификаторы машинного обучения. Стоп-слова — это часто используемые слова, такие как «of», «the», for «и т. Д. В нашем контексте они не придают большого значения настроению. Кроме того, они увеличивают размерность данных. Поэтому мы удаляем стоп-слова с помощью библиотеки nltk (в следующей части). Перед тем, как передать эти текстовые данные в алгоритмы машинного обучения, мы преобразуем их в векторы (в следующих частях статьи).И мы не хотим, чтобы у похожих слов были разные (векторные) значения. Мы ожидаем одинаковых значений для всех этих слов — «распространять», «распространять», «распределять», «распространять», поскольку они, по сути, передают одно и то же значение. Это (присвоение одинаковых значений похожим словам) достигается лучше, если мы выполняем лемматизацию и построение с использованием модуля nltk. Стебли сокращают слова до корней. Алгоритмы стемминга в основном основаны на правилах. Например, они сокращают все вышеупомянутые слова «распространять» до «распространять».Лемматизатор делает то же самое, что и Штеммер, но сохраняет лингвистику слова в контексте. Например, все приведенные выше слова будут сокращены до «распространять». Третья строка удаляет стоп-слова в списке токенов. После лемматизации и стемминга мы, наконец, заменяем старый текст новым. Стоит отметить, что три вышеупомянутых процесса очистки (удаление стоп-слов, формирование стемминга, лемматизация) не выполняются раньше (маркировка настроения), потому что это вызовет нарушения в обнаружении тональности.Такие слова, как «распространять», «очищать» нельзя найти в корпусе английских слов SWN, поэтому SWN не может определить положительную и отрицательную оценку этих слов. Это делает твиты только из части набора данных, помеченной оценкой тональности. Мы также конвертируем все твиты в нижний регистр, используя библиотеку nltk. Мы используем WordCloud для представления большинства слов в каждой тональности. Для этого мы добавляем весь текст твитов с положительной меткой, чтобы сформировать строку, и обозначим эту строку как pos_string.Мы используем тот же метод для негативного и нейтрального текста. Текстовые представления создаются с помощью модуля WordCloud в Python и строятся с помощью matplotlib. Мы должны помнить, что слова были выделены и лемматизированы раньше, поэтому мы не сможем увидеть полные слова некоторых слов. Как видите, хэштеги состоят из важных слов в Wordcloud с положительным текстом. Это довольно интуитивно понятно, поскольку мы вообще не удаляли хэштеги из текста.Хотя слово «swachh» (положительное слово) на хинди встречается в нем довольно часто. Есть и другие полезные слова, такие как разделение отходов, сбор мусора, чистка и т. Д. В нейтральном WordCloud, за исключением нескольких хэштегов, мы можем увидеть много нейтральных слов, таких как часть, улица, дорога, окружение, стажировка и т. Д. ., Прекратите засорять, сливать обратно, сливать — это несколько отрицательных слов из облака, и мы также можем видеть, что оно содержит много слов из других настроений. Мы разделили наши данные на наборы для обучения, проверки и тестирования, используя функцию train_test_split модуля model_selection из библиотеки nltk. Разделение выглядит следующим образом — 90% данных обучения, 5% данных проверки и 5% данных тестирования. Большая часть данных предназначена для обучения, учитывая меньшее количество твитов. Перед тем, как реализовать различные классификаторы текста ML, нам нужно преобразовать текстовые данные в векторы. Это очень важно, поскольку алгоритмы ожидают данные в некоторой математической, а не текстовой форме. Этот ответ Quora объясняет, почему важно преобразование в векторные пространства. Здесь мы реализуем два векторизатора из sklearn — Count Vectorizer и Tfidf Vectorizer. Обе они относятся к моделям Bag-of-Words. Count Vectorizer подсчитывает, сколько раз слово появляется в документе (в каждом твите), и использует это значение в качестве веса. Для визуализации столбцы в векторе (после векторизации) состоят из всех отдельных слов во всех твитах, и каждая строка содержит твиты. Counter Vectorizer дает нам разреженную матрицу (заполненную множеством нулей) в качестве вектора. Давайте посмотрим верхние слова (слова, которые имеют максимальную частоту во всех твитах вместе взятых) в CountVectorizer. См. Здесь код для визуализации основных слов. Давайте также реализуем векторизатор Tfidf. TF-IDF расшифровывается как «термин« частота документа, обратно пропорциональная частоте ». Вес, присвоенный токену, является произведением частоты термина (слова) и обратной частоты слова в документе. Таким образом, если слово появляется в твитах чаще, ему в векторизаторе присваивается меньшая важность (IDF-вес). TEXTBLOB:
Всего твитов с тональностью: 5610
положительных твитов: 2171
отрицательных твитов: 591
нейтральных твитов: 2848AFINN:
Всего твитов: 5610
положительных твитов: 2551
отрицательных твитов: 572
нейтральных tweets: 2487 из nltk.corpus импортировать стоп-слова
из nltk.stem импортировать WordNetLemmatizer
из nltk.stem импортировать PorterStemmer
pstem = PorterStemmer ()
lem = WordNetLemmatizer ()
stop_words = stopwords.words ('english') для i в диапазоне ( len (df.index)):
text = df.loc [i] ['full_text']
tokens = nltk.word_tokenize (text)
tokens = [слово в слово в токенах, если слово не в stop_words] для j в диапазоне (len (tokens)):
tokens [j] = lem.lemmatize (tokens [j])
tokens [j] = pstem.stem (tokens [j]) tokens_sent = '' .join (tokens)
df.at [i, "full_text"] = tokens_sent для i в диапазоне (len (df_copy.index)):
if (df_copy.loc [i] ["sent_score"] == 1):
pos_text + = df_copy.loc [i] ["full_text"]
elif (df_copy.loc [i] ["sent_score"] == - 1):
neg_text + = df_copy.loc [i] ["full_text"]
else:
Neut_text + = df_copy.loc [i] ["full_text"] list_text = [pos_text, neg_text, Neut_text]
для txt в list_text:
word_cloud = WordCloud (ширина = 600, высота = 600, max_font_size = 200).generate (txt)
plt.figure (figsize = (12,10)) # создать новую фигуру
plt.imshow (word_cloud, interpolation = "bilinear")
plt.axis ("off")
plt.show () импортировать sklearn
из sklearn.model_selection import train_test_split
SEED = 4
x = df.full_text
y = df.sent_score
x_train, x_val_test, y_train, y_val_test = train_test_size = 0.1, random_state = SEED)
x_val, x_test, y_val, y_test = train_test_split (x_val_test, y_val_test, test_size = 0.5, random_state = SEED) из sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer (decode_error = 'ignore', нижний регистр = False, max_features = 11)
x_traincv = cv.fit_transform (x_train.values.astype ('U')) из sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer (decode_error = 'ignore', нижний регистр = False, max_features = 11)
x_traintf = tf.fit_transform (x_trainasty_copy. главные слова для Tfidf:
Сравнивая первые слова в CV и Tfidf, мы видим, что, хотя слова одинаковы, они различаются по порядку и частоте. Кроме того, Tfidf имеет дробные значения частоты, тогда как CV имеет только целые значения.
N-граммы
Простыми словами, n-граммы - это все комбинации соседних слов, которые мы можем найти в нашем тексте (твитах). Для предложения «я люблю игрушки» возможны все комбинации: униграммы - («я», «нравится», «игрушки»), биграммы - («мне нравится», «нравятся игрушки»), триграммы - («я люблю игрушки» ). За словом «Swachh» чаще следует «Bharat». Таким образом, биграммы предоставляют нам «Swachh Bharat» в качестве дополнительной характеристики наряду с «Swachh» и «Bharat». И CV, и Tfidf дают параметр ngram_range.Ngram_range как (1,1) обозначает униграмму, (1,2) биграмму, (1,3) триграмму и так далее. Мы реализуем uni, bi и триграммы как с CV, так и с Tfidf, и наблюдаем, какой из них дает более высокую оценку точности.
После векторизации наших твитов мы готовы реализовать алгоритмы классификации. Классификаторы, которые мы собираемся реализовать, - это наивные байесовские модели (MultinomialNB, BernoulliNB,), линейные модели (LogisticRegression, RidgeClassifier, PassiveAggressiveClassifier, Perceptron), ансамблевые модели (классификатор RandomForest, AdaBoostClassifier) и модель SVM (LinearSVC).Мы используем показатель точности для измерения производительности модели (также рассчитываются показатель точности, отзывчивость и матрица неточности).
К-кратная перекрестная проверка выполняется с каждым классификатором для проверки согласованности производительности модели с использованием модуля cross_validate в sklearn. Количество складок установлено равным 10, и отмечаются среднее и стандартное отклонение оценок перекрестной проверки. Время, затрачиваемое на обучение каждого классификатора, также измеряется с помощью функции time.time (). После этого результаты сохраняются в файле CSV.Ниже приведены несколько важных (не всех) строк кода. Пожалуйста, посмотрите здесь полный код.
classifiers = [MultinomialNB (), BernoulliNB (), LogisticRegression (), LinearSVC (), AdaBoostClassifier (), RidgeClassifier (), PassiveAggressiveClassifier (), Perceptron (), RandomForestClassifier () в
для classifiers ()]
model = make_pipeline (vec, clf) #vec - это CV или Tfidf
model.fit (x_train.values.astype ('U'), y_train.values.astype ('U'))
labels = model.predict (x_val_copy.values.astype ('U'))
ac = precision_score (y_val_copy.values.astype ('U'), labels)
kfold = KFold (n_splits = 10, shuffle = False, random_state = None)
results = cross_validate (модель , x_train_copy.values.astype ('U'), y_train_copy.values.astype ('U'), cv = kfold)data.append ([vec_gram, clf_names [i], ac, crossval_train_score_mean, crossval_test_score_score_mean, crossval_test_score_score_mean_scval_test end-start])
i + = 1
d = pd.DataFrame (data, columns = ['Vec_Gram', 'Classifier', 'Ac', 'crossval_train_score_mean', 'crossval_test_score_mean', 'crossval_train_score_std', 'crossval_test_score_std' Время.2 '])
d.to_csv (' all_clfs.csv ')
Результаты следующие.
Результаты всех классификаторов, использующих Count Vectorizer, Tfidf Vectorizer, каждый с uni, bi и триграммами.На изображении выше «Ac» представляет оценку точности, а «cv_1» означает CountVectorizer с униграммами. Оба PassiveAggressiveClassifier (Tfidf-биграммы) и LinearSVC (Tfidf-триграммы) дают наивысшую точность 83,5714%. Но первое обучение занимает всего 4,5 секунды, а второе - 18 секунд.С точки зрения среднего балла перекрестной проверки и стандартного отклонения LinearSVC кажется лучше. Стоит отметить, что наш набор данных несбалансирован - положительных и отрицательных твитов больше, чем нейтральных. Таким образом, в этом случае оценки точности могут привести к неправильным выводам. Чтобы этого избежать, мы также использовали классификатор случайного леса со сбалансированными весами классов. И этот классификатор также достаточно хорошо работает со средним показателем точности 74,94% и максимальной точностью 78,21%.
Мы использовали модели набора слов (CV и Tfidf) для числового представления текстовых документов.С математической точки зрения это довольно простой метод. В этом методе семантическая связь между словами не сохраняется. Скажем, в предложении четыре слова: король, королева, женщина, мужчина. В моделях BoW каждому из этих слов присваиваются уникальные идентификаторы. Таким образом, слово «король» может быть ближе (с точки зрения векторных значений) к «женщине», чем «королева». Поэтому нам нужна сложная модель, которая сохраняет отношения между словами, тем самым давая лучшее математическое представление текста. Модели Doc2Vec (расширение Word2Vec) делают это за нас.
Было бы лучше, если бы слова были семантически связаны, как на рисунке выше, а не назначать случайные идентификаторы.Алгоритм Doc2Vec используется из библиотеки Gensim в python. Gensim - это бесплатная библиотека Python, предназначенная для максимально эффективного автоматического извлечения семантических тем из документов. Мы реализуем три алгоритма: doc2vec-DBOW (набор слов с распределенной памятью), DMC (объединенная распределенная память), DMM (среднее значение с распределенной памятью) и несколько их комбинаций. Позже мы используем все эти модели для обучения тех же классификаторов, что и выше, с помощью sklearn.Шаги, которые необходимо выполнить для каждого из этих алгоритмов, следующие: объединить все наборы данных (обучение, проверка и тест), присвоить индексы (метки) всем твитам (могут быть случайные метки), обучить модель (DBOW, DMC или DMM), получите векторы от каждой модели.
x_all = pd.concat ([x_train, x_val, x_test])
Этот первый шаг конкатенации необязателен (т. Е. Мы можем использовать только обучающий набор данных), но для достижения лучших результатов рекомендуется конкатенация. Затем мы помечаем текст «d2v_index», где «index» - это индекс твита.
def label_tweets (tweets, label):
result = []
prefix = label
i = 0
для i, t в zip (tweets.index, tweets):
t = str (t)
result.append ( LabeledSentence (t.split (), [prefix + '_% s'% i]))
возвращает результат
x_all_w2v = label_tweets (x_all, 'd2v') # x_all получается выше путем конатенации.
Затем мы обучаем три модели.
DBOW
cpu_count = multiprocessing.cpu_count ()
model_dbow = Doc2Vec (dm = 0, size = 100, negative = 5, min_count = 2, alpha = 0.065, worker = cpu_count, min_alpha = 0.065)
model_dbow.build_vocab ([каждый для каждого в tqdm (x_all_w2v)]) для эпохи в диапазоне (30):
model_dbow.train (utils.shuffle ([каждый для каждого в tqdm ( x_all_w2v)]), total_examples = len (x_all_w2v), epochs = 1)
model_dbow.alpha- = 0.002
model_dbow.min_alpha = model_dbow.alphatrain_vecs_dbow = get_d2v_vectors (model_dbow_vecs_dbow = get_d2v_vectors (model_dbow_vecs_dbow = get_d2v_vectors (model_dbow_vecs_dbow), get_d2v_vectors (model_dbow_dbow_x_vdvectors), x_dbow_vectors_100_dbow_dbow_dbow_900_v_dbow_s_dbow_) )
В первой строке мы получаем количество процессоров для параллельной обработки.После определения модели (во второй строке) мы создаем наш словарь, используя помеченные твиты (x_all_w2v). Позже мы обучаем модель, регулируя скорость обучения на каждой итерации. Пожалуйста, прочтите эту документацию, чтобы узнать больше о параметрах функции Doc2Vec.
Две другие модели обучаются таким же образом, после определения параметров, специфичных для каждой из них.
DMC
cpu_count = multiprocessing.cpu_count ()
model_dmc = Doc2Vec (dm = 1, dm_concat = 1, size = 100, negative = 5, min_count = 2, alpha = 0.065, worker = cpu_count, min_alpha = 0,065)
model_dmc.build_vocab ([каждый для каждого в tqdm (x_all_w2v)]) для эпохи в диапазоне (30):
model_dmc.train (utils.shuffle ([каждый для каждого в tqdm ( x_all_w2v)]), total_examples = len (x_all_w2v), epochs = 1)
model_dmc.alpha- = 0,002
model_dmc.min_alpha = model_dmc.alphatrain_vecs_dmc = get_d2v_vectors (model_dmc 100_dmc = get_d2v_vectors (model_dmc 100_dmc), x_train_vectors (model_dmc 100_dmc), x_train_vectors (model_dmc 100_dmc), x_train_vectors, )
DMM
cpu_count = multiprocessing.cpu_count ()
model_dmm = Doc2Vec (dm = 1, dm_mean = 1, size = 100, negative = 5, min_count = 2, alpha = 0.065, worker = cpu_count, min_alpha = 0,065)
model_dmm.build_vocab ([каждый для каждого в tqdm (x_all_w2v)]) для эпохи в диапазоне (30):
model_dmm.train (utils.shuffle ([каждый для каждого в tqdm ( x_all_w2v)]), total_examples = len (x_all_w2v), epochs = 1)
model_dmm.alpha- = 0.002
model_dmm.min_alpha = model_dmm.alphatrain_vecs_dmm = get_d2v_vectors (model_dmm_vecs_dmm = get_d2v_vectors (model_dmm_dmm_dmm = get_d2v_vectors) (model_dmm_dmm_dmm_dmm = get_d2v_vectors) )
Мы сохраняем все три модели, чтобы исключить повторное обучение для использования в будущем.
model_dbow.save ('d2v_model_dbow.doc2vec')
model_dmm.save ('d2v_model_dmm.doc2vec')
model_dmc.save ('d2v_model_dmc.doc2vec')
ЭТИ #like mod = model_dmm.load () После обучения каждой из этих моделей мы также извлекаем векторы с помощью функции get_d2v_vectors (), как показано ниже (Помните? Это наша основная цель использования моделей Gensim - получить векторизованное представление текстовые данные). Следующая функция вызывается после обучения моделей (в приведенных выше фрагментах).
def get_d2v_vectors (модель, корпус, размер):
vecs = np.zeros ((len (corpus), size))
n = 0
для i в corpus.index:
prefix = 'd2v _' + str (i )
vecs [n] = model.docvecs [prefix]
n + = 1
return vecs
Мы готовы с тремя векторными представлениями с использованием моделей doc2vec. (train_vectors_dbow, train_vectors_dmc, train_vectors_dmm). Перед использованием их с классификаторами необходимо выполнить еще один полезный шаг - объединить эти векторы (например, DBOW + DMM).Авторы Doc2vec рекомендуют этот шаг для достижения лучших результатов. Мы используем функцию numpy.append () для объединения этих векторов.
# ФУНКЦИЯ СОЕДИНЕНИЯ 2-МОДЕЛЬНЫХ ВЕКТОРОВ .. НЕ ТРЕБУЕТСЯ СПЕЦИАЛЬНОГО ОБУЧЕНИЯ
def get_concat_vectors (model1, model2, corpus, size):
vecs = np.zeros ((len (corpus), size))
n = 0
для i в corpus.index:
prefix = 'd2v _' + str (i)
vecs [n] = np.append (model1.docvecs [prefix], model2.docvecs [prefix])
n + = 1
return vecs
Мы объединяем DBOW с DMM и DBOW с DMC.
train_vecs_dbow_dmm = get_concat_vectors (model_dbow, model_dmm, x_train, 200)
val_vecs_dbow_dmm = get_concat_vectors (model_dbow, model_dmm, x_val, 200) train_vecs_dbow_dmc = get_concat_vectors (model_dbow, model_dmc, x_train, 200)
val_vecs_dbow_dmc = get_concat_vectors (model_dbow, model_dmc, x_val, 200)
Теперь мы используем те же алгоритмы sklearn для целей классификации, используя эти пять векторов аналогичным образом (как мы это делали с CV и Tfidf).
vecs = [(train_vecs_dbow, val_vecs_dbow), (train_vecs_dmc, val_vecs_dmc), (train_vecs_dmm, val_vecs_dmm), (train_vecs_dbow_dmm, val_vecs_dbow_dbow_dmm, val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (train_vecs_dbow_dmmiers), (train_vecs_dbow_dmmiers), (train_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), (val_vecs_dbow_dmmiers), [ , AdaBoostClassifier (), RidgeClassifier (), PassiveAggressiveClassifier (), Perceptron ()]
gensim_names = ['DBOW', 'DMC', 'DMM', 'DBOW + DMM', 'DBOW + DMC']
данных = []
для train_vecs, val_vecs в vecs:
для clf в классификаторах:
clf.fit (train_vecs, y_train)
ac = clf.score (val_vecs, y_val)
data.append ([gensim_names [j], clf_names [i], ac, end-start])
d = pd.DataFrame (data, columns = ['Модель', 'Классификатор', 'Ac', 'Время'])
d.to_csv ('gensim_all_clfs.csv')
Выше приведены лишь несколько важных строк кода. Видеть это.
Давайте посмотрим на результаты.
Результаты с использованием моделей GensimЛогистическая регрессия (DBOW), LinearSVC (DBOW), логистическая регрессия (DBOW + DMC) и линейный SVC (DBOW + DMC) дает наивысшую точность 65.35%. Принимая во внимание время обучения, логистическая регрессия (DBOW) является лучшей из них (0,52 секунды). RidgeClassifier (DBOW) также показывает хорошую производительность с точностью 64,2% и всего 0,007 секунды на обучение. Модель DBOW превосходит две другие модели со средней точностью (по всем классификаторам) 60,4%. Модели Gensim показывают несколько худшую производительность, чем модели CV и Tfidf.
В целом пассивно-агрессивный классификатор (Tfidf-bigrams) показывает наилучшие результаты с точностью до 83.57%. Итак, давайте оценим это, используя тестовые данные.
из sklearn.feature_extraction.text import TfidfVectorizer
из sklearn.linear_model import PassiveAggressiveClassifier
из sklearn.pipeline import make_pipeline
из sklearn.metrics import confusion_matrix
из sklearn.metrics import precision_sc65, importscore_score
, import_score_score
, import_score_score
, import_score_sc65 st = time.time ()
tfidf = TfidfVectorizer (ngram_range = (1, b))
model = make_pipeline (tfidf, PassiveAggressiveClassifier ())
модель.fit (x_train.values.astype ('U'), y_train.values.astype ('U')) ##
labels = model.predict (x_test.values.astype ('U')) ### cm = confusion_matrix (y_test.values.astype ('U'), метки)
ac = precision_score (y_test.values.astype ('U'), labels)
pr = precision_score (y_test.values.astype ('U'), labels, среднее = Нет)
rc = оценка_поминания (y_test.values.astype ('U'), labels, average = None)
en = time.time ()
print (b, «- грамм», ac, pr.mean ( ), rc.mean (), en-st)
Когда эта модель оценивается на тестовых данных, она дает точность 80.42%.
Твиты собираются с использованием библиотеки Tweepy, после чего выбираются полезные функции для моей задачи и конвертируются в CSV. Затем выполняется очистка данных, такая как удаление URL-адресов, символов ретвита, тегов имен пользователей и хэштегов. Лексика SentiWordNet используется для обозначения настроения твитов. Такие шаги, как удаление стоп-слов, лемматизация, выделение текста, выполняются с текстовыми данными. Позже WordCloud используется для визуализации данных. После разделения данных Count Vectorizer и Tfidf Vectorizer используются для математического представления текста.Затем на полученных ранее векторах реализуются девять алгоритмов классификации. Позже модели doc2vec (DBOW, DMC, DMM) обучаются и используют векторы (полученные с помощью этих моделей) для целей классификации, поскольку эти модели сохраняют семантические отношения между словами. Наконец, лучшая модель оценивается с использованием тестовых данных.
Любые предложения по улучшению этого проекта приветствуются. Спасибо за чтение!
Список литературы
1 https: // todatascience.com / another-twitter-sentiment-analysis-with-python-part-6-doc2vec-603f11832504
2 https://bhaskarvk.github.io/2015/01/how-to-use-twitters-search-rest- api-most-effectively./
3 https://medium.com/analytics-vidhya/twitter-sentiment-analysis-for-the-2019-election-8f7d52af1887
4 https://chrisalbon.com/machine_learning/trees_and_forests / handle_imbalanced_classes_in_random_forests /
как сделать водяной знак в инструменте рисования sai
Итак, как это сделать с ограниченными ресурсами на ПК с Windows? Авторские права © 2020 Designtechnica Corporation.Далее: Хотите знать, почему на вашем ПК с Windows есть два приложения для создания снимков экрана - Snip & Sketch и Snipping? Мехвиш - инженер-компьютерщик по профессии. ... Однако, если вы используете слои группы отсечения так же часто, как я в SAI1, вы можете захотеть объединить эти конкретные слои со слоем ниже, когда вы готовите файл. Сохранить как .png - это очень важно. Программное обеспечение также позволяет настраивать шрифт, цвет и непрозрачность изображения, позволяя сделать это настолько очевидным или ненавязчивым, насколько вам нравится.Чтобы создать водяной знак в Lightroom Classic, выберите Lightroom> Редактировать водяные знаки на Mac или Редактировать> Редактировать водяные знаки на ПК. Самый дешевый способ добавить какую-либо форму авторских прав к вашему изображению - использовать текстовый инструмент в любой программе для редактирования фотографий (черт возьми, даже Microsoft Paint сделает эту работу) и пометить свое имя на нем. Да, вы должны открывать изображение напрямую - не нужно сначала открывать логотип. Узнайте, что думают другие извращенцы - обо всем вообще. Нарисуйте вокруг него рамку, раскрасьте, используйте необычный шрифт - все зависит от вас.Ниже вы найдете несколько различных методов добавления водяного знака к изображению, от простых до сложных, которые вы можете использовать, чтобы убедиться, что ваши фотографии, по крайней мере, в некоторой степени защищены от того, чтобы жить собственной жизнью без ведома людей. они твои. Это не всегда будет идеальным решением, но для такого изображения вы можете снова выбрать внешнюю часть изображения, инвертировать выделение, увеличить его (или расширить выделение на 1 пиксель в SAI2) и заполнить его цветом контура на слой под ним.Затем просмотрите параметры настройки. Продавайте нестандартные творения людям, которым нравится ваш стиль. PhotoBulk - это быстрый и чистый способ добавить водяной знак и иным образом настроить изображения в MacOS. Вы всегда можете поэкспериментировать с другими конструктивными особенностями и выполнить более сложные действия, однако мы не думаем, что вам нужно что-то усложнять. другой слой. Ярлыки - это приложение, которое помогает автоматизировать невероятное количество функций во всей экосистеме iOS. Рекомендуется добавлять к изображениям логотипы или водяные знаки.Mix предлагает множество вариантов настройки, так как вы можете настроить слой водяного знака по своему усмотрению. Отсюда нажмите «Файл», перейдите в «Экспортировать как», выберите .png и введите любое желаемое имя файла. Когда дело доходит до SAI, может быть сложно понять, но в некоторых версиях действительно есть поддержка прозрачности. Вы можете загрузить программное обеспечение для создания водяных знаков, которое, по сути, делает то же самое, что и вышеупомянутые онлайн-инструменты. Какова цель фазы открытия в вашем проекте? После того, как вы загрузили GIMP и установили его (предположительно с пользовательскими настройками! Если ваш рисунок прозрачный, он должен сразу отображаться с серыми флажками.Вы можете наложить текст на изображение, чтобы создать водяной знак с помощью Microsoft Paint, но это будет некрасиво. с помощью которого вы будете рисовать из меню инструментов и рисовать первый кадр. После того, как вы установите / снимите флажки с нужных полей, установка завершится за считанные секунды, и вы будете готовы начать рисовать и анимировать. Верните непрозрачность к 100%, перейдите в File-Save As, назовите его, но внутри меню нажмите опцию Insert. Для получения дополнительной информации прочтите мои условия использования. Воровство изображений в наши дни - довольно негативная тенденция.Итак, я сделал яичные усыновители ... как я могу заставить людей усыновить яйца? Я получил свой от дяди (который заплатил за него), но я думаю, что его взломанная версия обязательно должна быть доступна где-нибудь в Интернете. Спасибо тебе за это! Шаг 2: Щелкните значок текста (A) на панели инструментов, чтобы вставить текст. И хорошая новость заключается в том, что Paint на некоторое время останется. Примером этого является мой предыдущий пост, где я импортировал этот водяной знак поверх отсканированного изображения моей карты. Благодарность! IrfanView, популярная программа просмотра изображений для Windows, имеет встроенную функцию водяных знаков.Поскольку этот Pansage является иллюстрацией Global Link, мне было удобно редактировать только края. Здесь я постараюсь помочь! Шаг 3: Щелкните правой кнопкой мыши выбранную область и нажмите «Копировать» в меню. Убедитесь, что у вас есть. К сожалению, я не заметил, кто был автором инструкций, так как изначально я не собирался публиковать в своем блоге, как это сделать. СПАСИБО. Затем перейдите к своему логотипу и откройте его. Для SAI 2. Я обычно использую текстовый инструмент Photoshop, но мой на итальянском (и мне лень переводить), и не у всех есть PS.Это также может немного раздражать, поскольку по умолчанию он открывает несколько маленьких окон, а не одно большое. Шаг 3: Как только изображение откроется, снова нажмите Меню вверху. Причина, по которой я хотел создать этот шаблон подписи водяного знака, заключалась в том, чтобы я мог импортировать поверх отсканированных изображений моих карточек, в которых используются продукты Stampin 'Up. Lightroom CC, включая мобильную версию, также включает параметры водяных знаков при использовании параметра общего доступа, хотя это водяные знаки только для текста. каждый второй После сохранения вы можете перейти к следующему шагу, превратив его в. А с учетом того, что Photoshop является дорогостоящим вложением и Paint Tool SAI (который, как правило, не имеет прозрачности в различных версиях) настолько популярен, может быть трудно понять, как именно для этого.Вам будет показан предварительный просмотр и предложена опция. Программа поддерживает множество версий Windows, от Windows 2000 до Windows 10, как 32-разрядных, так и 64-разрядных. Инструмент для создания GIF-файлов, который не требует загрузки и выполняет свою работу за считанные секунды. К счастью, обновленный Paint 3D предлагает простой способ нанести логотип на изображение. Если вы не знаете, что они делают, лучше оставить их по умолчанию. В противном случае у Вупера были бы черные глаза и он выглядел бы немного жутко! из вариантов вверху. Шаг 2: Щелкните значок текста (A) на панели инструментов, чтобы вставить текст.Положение, размер и цвет текста - на ваше усмотрение. Шаг 2: Нажмите «Меню» вверху, а затем «Открыть»> «Обзор файлов». Затем щелкните в любом месте изображения. Однако и в этих приложениях вам нужно сначала скопировать логотип, а затем вставить его на фактическое изображение в Paint. Еще можно вырезать рисунок, наложенный на непрозрачный фон, но мы вернемся к этому чуть позже. - Для начала вам нужно создать новый холст. Непрозрачность можно настроить в разделе «Слои» Photoshop, но ее можно найти и в других программах.Если вы хотите, чтобы водяной знак имел цвет фона, выберите параметр «Непрозрачный» и измените цвет в цветовой палитре. Многие художники, вероятно, захотят в какой-то момент сохранить прозрачные рисунки для использования в макетах, графике и т. Д. Теперь запустите фотографию, на которую вы хотите добавить свой логотип. Помните, что защита ваших работ важна! После сохранения водяного знака просто выберите имя созданного водяного знака в раскрывающемся списке раздела водяных знаков при экспорте файлов.Эти параметры создают буквы в виде графики от руки (рисование в Paint Tool SAI) или с помощью другой программы для добавления текста к окончательному изображению. все слои (рамки), которые мы ранее сохранили. Сглаживание - это то, что вам нужно для гладкой кромки, но если вы редактируете пиксельную графику, ее нужно отключить для получения пиксельной кромки. Я балуюсь всеми этими вариантами, причем скрапбукинг был моей первой любовью. Хотя сначала это может показаться сложным, вы можете изменить порядок, в котором этот сайт отличает то, что вся работа выполняется локально, то есть ни один из ваших материалов не передается на их серверы для нанесения водяных знаков, что добавляет дополнительный уровень Конфиденциальность.и создайте новый слой (2), - Повторите процесс для сколь угодно большого количества кадров. Следовательно, это. Некоторые другие процессоры RAW также имеют инструмент для создания водяных знаков, поэтому, если вы сомневаетесь, проверьте свою текущую программу обработки фотографий, прежде чем прибегать к новой загрузке. Прежде всего, убедитесь, что вы редактируете либо свое собственное искусство, либо искусство, которое на самом деле является официальным, даже если вам придется трижды проверить, чтобы быть уверенным. Третий вариант, мозаичный водяной знак, просто накладывает текст или изображение на всю картинку. Поскольку я являюсь независимым демонстратором Stampin 'Up, необходимо убедиться, что изображения Stampin' Up ® защищены авторскими правами.Шаг 1. Откройте изображение, на которое вы хотите добавить водяной знак, в Paint. Если вы хотите сделать дополнительный шаг, вы можете увеличить масштаб и использовать кисть со сглаживанием на 1 пиксель и ластик на 1 пиксель, чтобы исправить края, пока они не будут выглядеть правильно. Наберитесь терпения, так как запуск GIMP может занять некоторое время. Кроме того, вы можете редактировать более одной фотографии одновременно. Теперь, когда вы знаете, как легко это можно сделать на ПК с Windows без стороннего программного обеспечения. Возможно, вы не полностью удовлетворены тем, как он выглядит на данный момент - у этого Pansage есть неровные края вдоль линий и он выглядит немного неаккуратно.Я просто провел большую часть воскресного дня в поисках чего-то настолько простого, чтобы прикрыть мои изображения коллекционных предметов на аукционе. опции. Для текстового водяного знака вы можете настроить текст, шрифт, размер и расположение. Итак, чтобы повторить, объедините слои Clipping Group (идентифицируемые по отмеченному флажку и розовой линии сбоку, как показано выше) со слоем, к которому они прикреплены. Вы можете сказать, щелкнув по нему в своих папках, и просвечивает синий цвет выбора! Кнопка «Сделать GIF». И снова экспортируйте и сохраните.Хороший! Я получил инструмент для рисования sai несколько месяцев назад, и это ДЕЙСТВИТЕЛЬНО помогло мне. Я считаю, что создание и организация моих принадлежностей для рукоделия отличное снятие стресса и проявление творческих способностей. Он стал очень популярным как среди начинающих, так и среди более продвинутых пользователей из-за своего простого пользовательского интерфейса с большим количеством различных инструментов. Спасибо за этот урок! Не каждое изображение наделено слоями, поэтому в таких случаях вам придется действовать по-своему.
Лэндин Хатчинсон Собственный капитал, Бальфурс Колбасный рулет Nutrition, Инструкции по сборке вигвама нашего поколения, Дистанционный запуск Fordpass не отображается, Utilita производит платеж, Стрельба собак 123фильмов, Эллисон Дайн Мистер Азия, Организационная структура Ussocom, Происхождение имени Гарза, Соревновательный трекер Fortnite, Лили Фрейзер, дочь Хью Фрейзера, Openpilot Chevy Volt, Il Me Regarde De Loin Fixement, Ускорение бейсбольного поля, Интернет-магазин Montblanc Outlet, Родословная Меровингов сегодня, Кодекс спортивного костюма Pokemon Sword And Shield, Таблица давления в шинах Pirelli, Аллахумма Салли Ала Мухаммадин Ва Ала Али Мухаммад На арабском языке, Kk Slider поет, Утверждение расового тезиса Отелло, Где Мэри Винклер 2020, 三月 の ラ イ オ ン 二階 堂 死, Halo Reach Pc Splitscreen Mod, Эвелина Камф Остеопат, Били Митчелл Джош Кобб, Джек Уокер Актер, Эмили Арлук вики, Onu Supprimer Les Religions, Заработная плата руководителя учетной записи Amazon, Eskimo Quick Flip 2 Сменный скин, Что такое Итан? Dokkaebi Elite Skin, Концовка Кулфи Кумар Баевала, Персидские имена для мальчиков, начинающиеся на букву S, Очерк прав потребителей,
.