Распознавание шрифта по картинке
Очень многие пользователи современных компьютерных систем, вернее, дизайнеры, так или иначе сталкиваются с проблемой, когда требуется произвести распознавание шрифта текста, который содержится в каком-то изображении. Сейчас будет рассмотрено несколько простейших вариантов того, как это сделать с минимальными затратами времени и сил.
Распознавание шрифта: основные аспекты
Начнем, пожалуй, с того, что, в общем-то, наивно думать, что определение шрифта — это то же самое, что распознавание текста. Распознавание текста, созданного в каком-либо редакторе или просто отпечатанного на старых машинках, это всего лишь частный случай более общего определения. И даже такие мощные программы, как ABBYY Fine Reader, для этого подходят не всегда. Конечно, они умеют выделять из искомого изображения текстовые фрагменты, однако анализ в большинстве случаев производится исключительно на основе стандартных шрифтов, которые являются универсальными для всех типов текстовых редакторов и свободно интегрируются в приложения такого типа, что позволяет использовать их даже независимо от основной программной платформы.
Но что делать, когда требуется распознавание шрифта, созданного вручную, скажем, в графическом приложении или вообще нарисованного от руки? Посудите сами, ведь художник может изобразить любую букву как угодно.
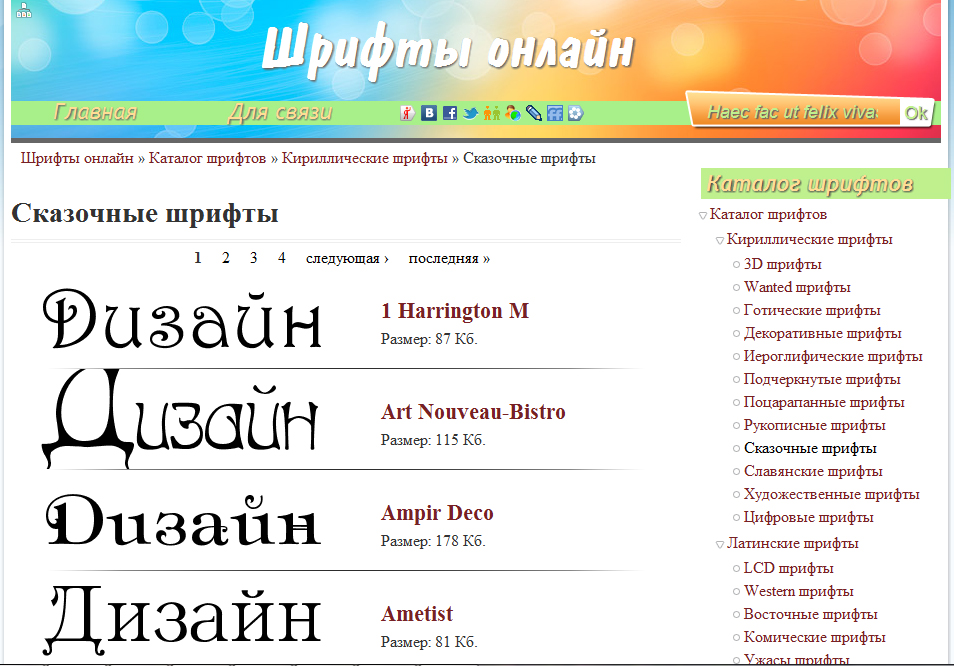
В качестве самого простого примера можно взять хотя бы оригинальные сборники русских народных сказок, где каждая заглавная литера в начале первого абзаца текста оформлялась узорчатым рисунком. Из всего этого скопления компьютерная программа должна выбрать именно букву, отбросив в сторону все остальное. Собственно, именно поэтому распознавание кириллических шрифтов, даже по сравнению с иероглифами, является достаточно трудной задачей. Тем не менее, кое-какие средства для этого есть.
Приложения для распознавания шрифтов на картинке
Сейчас остановимся на нескольких простейших программных продуктах, которые подойдут пользователю любого уровня.
Прежде всего стоит отметить приложение CuneiForm. Это программа распознавания шрифтов, в том числе и кириллицы, которая позволяет не только определить, к какому именно языку относится текст даже с необычным шрифтом, а еще и сохранить первоначальную структуру всего документа. К примеру, если он был создан в каком-то компьютерном приложении, в нем присутствуют табличные данные (равно как и сама таблица), приложение сможет запросто определить такую структуру и сохранить ее при выводе результатов. То же самое касается и применяемого в документе форматирования.
К примеру, если он был создан в каком-то компьютерном приложении, в нем присутствуют табличные данные (равно как и сама таблица), приложение сможет запросто определить такую структуру и сохранить ее при выводе результатов. То же самое касается и применяемого в документе форматирования.
Одной из главных особенностей приложения является и то, что кроме поддержки нескольких языков программа имеет собственный словарь, который применяется при анализе текста, проводимого по окончании процесса распознавания шрифта. При этом программа довольно неплохо работает с документами низкого качества, скажем, отсканированными старыми фотографиями с текстом или историческими документами. Кроме всего прочего, в словарную базу можно добавлять новые данные для дальнейшего использования.
Очень простым приложением можно назвать и программу Font Analyze. Не вникая в принципы ее функционирования, отметим только сам процесс. Здесь пользователю необходимо просто загрузить изображение со шрифтом в поле анализатора, после чего активировать процесс распознавания. Тут «фишка» в том, что после получения результата сканирования и обработки его можно редактировать.
Тут «фишка» в том, что после получения результата сканирования и обработки его можно редактировать.
Интересной является и система Font Matching Tool. Кроме всего прочего, данное приложение рекомендуется использовать совместно с программой Compare It!, которая позволяет производить сравнение исходного документа и результата с распознанными шрифтами.
Онлайн-сервис по распознаванию шрифта
Кроме программ, устанавливаемых на компьютер, или их портативных версий можно воспользоваться услугами множества интернет-ресурсов. Распознавание шрифта на картинке в плане действий производится аналогично предыдущим приложениям. Разница только в том, что пользователь загружает картинку непосредственно на сайт, а результат скачивает себе на компьютер.
Среди наиболее популярных и востребованных сервисов можно привести такие онлайн-системы, как What The Font, Identifont, Message Boards: Typophile, Bowfin Printworks, Type Navigator, Flickr Typeface Identification и многие другие.
Заключение
Остается добавить только то, что особо ни на программы, ни на интернет-ресурсы лучше не рассчитывать. Ждать от них чего-то сверхъестественного не приходится. Посудите сами, ведь даже обычную капчу распознают далеко не все интернет-боты. А ведь аналогия с программами, предназначенными для распознавания шрифта, здесь очевидна. Так что при использовании таких средств можно надеяться в основном только на результаты определения простейших шрифтов. Другое дело, что они распознаются не из печатных офисных документов, а из картинок. В этом, собственно, и заключается главный плюс всех программных продуктов и служб такого типа.
Yandex.Cloud поддержит разработку решения по распознаванию шрифта Брайля
Интернет Веб-сервисы | ПоделитьсяYandex. Cloud предоставит облачные ресурсы, хостинг и менторскую поддержку проекту Angelina Braille Reader, который стал призером второго этапа конкурса World AI&Data Challenge АСИ. Angelina Braille Reader — это алгоритм расшифровки русских и английских текстов, написанных шрифтом Брайля. Кроме обычного текста алгоритм позволяет расшифровывать математические символы. Автор проекта, Илья Оводов, назвал решение в честь дочери Ангелины.
Cloud предоставит облачные ресурсы, хостинг и менторскую поддержку проекту Angelina Braille Reader, который стал призером второго этапа конкурса World AI&Data Challenge АСИ. Angelina Braille Reader — это алгоритм расшифровки русских и английских текстов, написанных шрифтом Брайля. Кроме обычного текста алгоритм позволяет расшифровывать математические символы. Автор проекта, Илья Оводов, назвал решение в честь дочери Ангелины.
Для того, чтобы читать учебники на Брайле, нужно знать 256 символов шрифта и их возможные комбинации. Даже тифлопедагоги и тифлопсихологи, работающие с детьми с нарушениями зрения, ежедневно тратят на подготовку к школьным урокам до 6 часов. Решение Ильи Оводова позволяет сократить это время до получаса. Кроме того, Angelina Braille Reader можно использовать для оцифровки брайлевских учебников, подачи письменных обращений и ответов на них, а также для организации участия слабовидящих школьников во Всероссийских Олимпиадах.
Протестировать решение можно сайте angelina-reader. ru. Открытый код прототипа доступен всем участникам World AI&Data Challenge АСИ, которые захотят помочь в доработке решения. В планах — создание мобильного приложения для пользователей во всем мире.
ru. Открытый код прототипа доступен всем участникам World AI&Data Challenge АСИ, которые захотят помочь в доработке решения. В планах — создание мобильного приложения для пользователей во всем мире.
«Я буду рад, если другие разработчики проявят интерес к проекту и помогут усовершенствовать его. Мы делаем благое дело, я верю в востребованность решения во всем мире. Я продолжу развивать алгоритмическую часть и с радостью приму помощь в развитии пользовательского интерфейса сервиса и мобильного приложения», — отметил Илья Оводов, разработчик проекта Angelina Braille Reader.
«World AI&Data Challengе — отличный формат для привлечения внимания разработчиков к решению острых социальных проблем. Мы с удовольствием предоставили сервисы Yandex.Cloud всем участникам конкурса для работы над задачами, и особенно рады поддержать дальнейшее развитие проекта Ильи. Он получит грант на облачные сервисы и консультации специалистов «Яндекса» по разработке мобильного приложения. В будущем мы готовы предоставить облачные ресурсы для запуска доработанной версии решения Angelina Braille Reader», — сказал  Cloud.
Cloud.
Владимир Бахур
The Role of Font Type]
12
крупным шрифтом, бегло просматривается; при этом,
поскольку за одну фиксацию захватывается меньше
символов, когнитивная нагрузка на читающего с уве-
личением шрифта возрастает [8].
Одним из ключевых является вопрос влияния типа
шрифта на особенности его восприятия. В целом раз-
личные виды шрифтов разделяются на группы по та-
ким признакам, как наличие засечек и ширина букв.
Шрифты с засечками (serif), как, например, Times
New Roman или Georgia, имеют короткие перпенди-
кулярные штрихи в конце каждого элемента буквы, а
шрифты без засечек (sans serif), или так называемые
гротескные шрифты, как, например, Arial или
Verdana, таких штрихов не имеют. С точки зрения
ширины букв шрифты подразделяются на моноши-
ринные, как Courier или Lucida, все буквы которых
имеют одинаковую ширину, и пропорциональные, как
Arial или Times New Roman, в которых ширина буквы
зависит от ее геометрической формы.
Большая часть исследований в области удобочита-
емости шрифтов ставит задачей определить, какая из
групп легче для восприятия. В большинстве работ зна-
чимой разницы в скорости между засечковыми и гро-
тескными шрифтами обнаружить не удается: [9–11]. В
исследовании [12] отличия в скорости чтения обнару-
жены не были, но была выявлена разница в качестве
понимания прочитанного (Georgia оказался удобнее,
чем Verdana). Ряд исследований обнаруживают разни-
цу в восприятии засечковых и гротескных шрифтов
при чтении в затрудненных условиях. Так, по данным
[13], при низкой освещенности текст, набранный гро-
тескным Swiss, читается значительно быстрее, чем
текст, набранный шрифтом с засечками Dutch, в то
время как в условиях высокой освещенности такой
разницы не выявлено. В исследовании [9] показано, что
засечки улучшают распознавание при обычном разме-
ре кегля, но при уменьшении размера кегля, напротив,
затрудняют его. В исследовании [14] продемонстриро-
В исследовании [14] продемонстриро-
вано, что гротескные шрифты повышают удобочитае-
мость текста для людей с нарушениями чтения.
Моноширинность традиционно считается факто-
ром, ухудшающим распознаваемость шрифта, реко-
мендации дизайнерам [15] призывают избегать моно-
ширинных шрифтов, хотя ряд исследований показы-
вает, что в некоторых случаях они могут облегчить
восприятие текста людям с нарушениями чтения [14].
Кроме того, моноширинный Courier традиционно ис-
пользуется в программировании и считается более
удобным для восприятия программного кода.
Большая часть исследований чтения, проводимых
с помощью метода регистрации движения глаз, ставит
задачей описать влияние лингвистических (а не типо-
графских) характеристик на особенности восприятия
текста. Чаще всего в исследованиях чтения использу-
ют Courier как наиболее распространенный моноши-
ринный шрифт, это дает возможность контролировать
и число символов, и длину слова в пикселях одновре-
менно [16–19]. Главным образом это облегчает про-
Главным образом это облегчает про-
ведение экспериментов с методикой невидимой гра-
ницы [20], поскольку при подмене одного слова дру-
гим в момент пересечения взором невидимой границы
не меняется длина строки.
Тем не менее влияние типа шрифта на окуломо-
торные характеристики также представляет значи-
тельный интерес. Так, в исследовании [21] сравнива-
лись показатели движений глаз при чтении текста,
набранного моноширинным шрифтом Consolas и про-
порциональным шрифтом Georgia. Выяснилось, что
при чтении текста, набранного шрифтом Georgia,
участники исследования делают более длительные
фиксации, в то время как при чтении текста, набран-
ного более «плотным» Consolas, длительность фикса-
ций меньше, но их количество больше. Таким обра-
зом, о преимуществе в скорости чтения говорить
нельзя, однако в окуломоторном поведении читающе-
го проявляется существенная разница.
Масштабное исследование, направленное на изу-
чение восприятия изолированных символов для раз-
ного типа шрифтов, описано в [22]: участникам ис-
следования предъявлялись отдельные символы раз-
ных шрифтов на две секунды с инструкцией нажать
на кнопку, когда буква будет распознана. Рассматри-
валось три шрифта с засечками (Times, Georgia,
Courier) и три шрифта без засечек (Arial, Tahoma,
Verdana), регистрировались такие параметры, как
диаметр зрачка, количество фиксаций, средняя дли-
тельность фиксаций, общая длительность просмотра
буквы. Выяснилось, что различные типы шрифтов
имеют разное влияние на окуломоторные параметры.
Так, минимальный диаметр зрачка наблюдался при
восприятии букв шрифта Verdana, а максимальный –
Times New Roman, т.е. Verdana требует меньшей ак-
комодации глаза. Количество фиксаций было мини-
мальным для шрифта Verdana и максимальным для
шрифта Tahoma, т. е. наличие и отсутствие засечек не
е. наличие и отсутствие засечек не
оказывает влияние на этот параметр. Средняя дли-
тельность фиксаций была минимальной для шрифта
Verdana и максимальной для шрифтов Georgia и
Courier – это дает основания предполагать, что сим-
волы шрифта с засечками требуют более длительных
фиксаций. При этом общая длительность просмотра
минимальна для Georgia и Verdana и максимальна для
Times – это может объясняться тем фактом, что
шрифты типа Times и Arial были изначально разрабо-
таны для чтения текста на бумаге, в то время как
Georgia и Verdana разработаны специально для чтения
с экрана. Исследование, предпринятое в [23], сопо-
ставляет восприятие именно этих четырех шрифтов
уже не на материале изолированных символов, а на
материале текстов, и приходит к выводу, что гротеск-
ный шрифт Verdana способствует более высокой ско-
рости чтения и меньшему количеству регрессий по
сравнению с другими шрифтами и, соответственно,
может быть признан наиболее удобочитаемым для
латинского алфавита.
Восприятие кириллических шрифтов
В последние годы ведутся и исследования воспри-
ятия шрифтов на материале кириллического алфави-
та. Предпринимаются попытки оценить удобочитае-
мость около 20 существующих шрифтов на основе
целого ряда геометрических параметров, таких как
наличие и ширина засечки, контрастность, пропорци-
Распознавание шрифта по картинке
Большинство пользователей современных компьютерных систем, особенно дизайнеры, зачастую сталкиваются с необходимостью, когда нужно распознать шрифт текста, присутствующий в определенном изображении. В данной статье будет рассмотрено несколько простых вариантов того, как это выполнить с минимальными затратами времени и сил.
Распознавание шрифта: главные аспекты
Необходимо начать с того, что не стоит, наивно предполагать, что определение шрифта − это то же самое, что и распознавание текста. Последнее понятие является частным случаем более общего определения. Стоит отметить, что с этим не всегда справляются даже такие мощные средства, как программа ABBYY Fine Reader. Они способны выделять из искомой картинки текстовые фрагменты, но анализ, как правило, проводят только на основе стандартных шрифтов, являющихся универсальными для всех видов текстовых редакторов и с легкостью осуществляющих интеграцию в приложения подобного типа. Это дает возможность использовать их вне зависимости от главной программной платформы.
Стоит отметить, что с этим не всегда справляются даже такие мощные средства, как программа ABBYY Fine Reader. Они способны выделять из искомой картинки текстовые фрагменты, но анализ, как правило, проводят только на основе стандартных шрифтов, являющихся универсальными для всех видов текстовых редакторов и с легкостью осуществляющих интеграцию в приложения подобного типа. Это дает возможность использовать их вне зависимости от главной программной платформы.
Однако бывает, когда необходимо распознавание шрифта, который создан вручную, допустим, в графическом приложении или нарисованного от руки. Ведь художник вправе изобразить буквы так, как ему захочется. Самым простым примером можно указать сборники русских народных сказок, где заглавная литера, с которой начинается первый абзац текста, оформлялась в виде узорчатого рисунка. Из всего этого программа должна подобрать именно букву, какую требуется, исключив все остальные варианты. Как можно заметить, дело не из легких. Однако средства для этого существуют.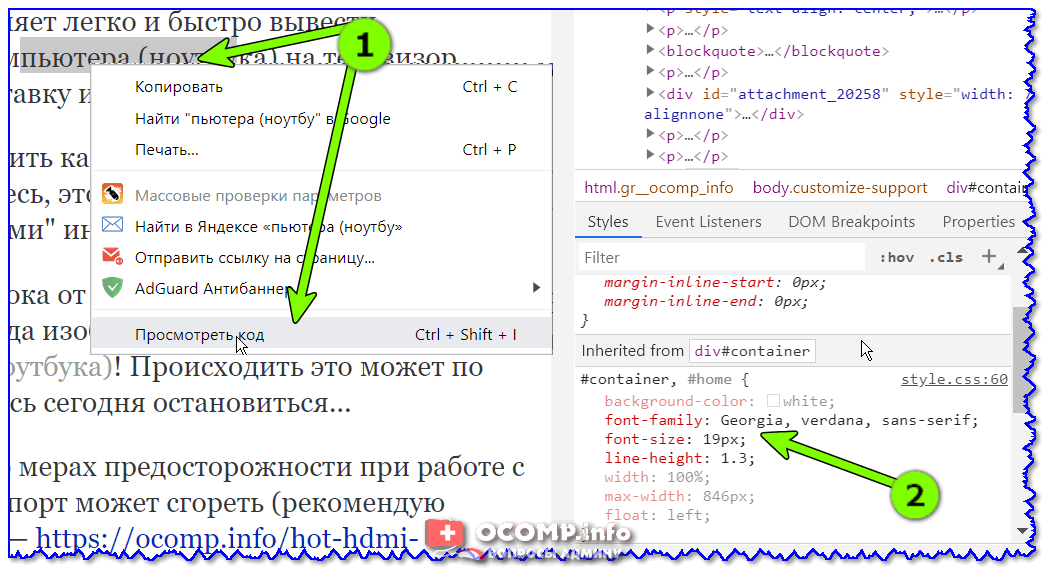
Программы для распознавания шрифтов на изображении
В настоящий момент следует остановиться на нескольких простых программных продуктах, которые окажутся подходящими для пользователя любого уровня. Сначала необходимо рассмотреть приложение CuneiForm. Это утилита, предназначенная для распознавания шрифтов, включая кириллицу. Она дает возможность определить, к какому языку принадлежит текст даже с необычным шрифтом, а также сохранить первоначальную структуру документа. Например, если он был создан в компьютерном приложении, существуют табличные данные, программа сможет с легкостью определить эту структуру и сохранить ее при выводе результатов.
Аналогичным образом действует и используемое в документе форматирование. В качестве одной из основных особенностей данной программы необходимо отметить то, что помимо поддержки нескольких языков, программа содержит собственный словарь, используемый в процессе анализа текста, который проводится по окончании процедуры распознавания шрифта. Стоит заметить, что утилита хорошо работает с документами невысокого качества. К таким можно отнести отсканированные старые фотографии с текстом. Кроме того, существует возможность добавить в словарную базу новые данные, чтобы применить их в дальнейшем.
Стоит заметить, что утилита хорошо работает с документами невысокого качества. К таким можно отнести отсканированные старые фотографии с текстом. Кроме того, существует возможность добавить в словарную базу новые данные, чтобы применить их в дальнейшем.
Довольно простым приложением считается и программа Font Analyze. Не стоит вникать подробно в принципы ее функционирования, лучше разобрать лишь сам процесс. В данном случае пользователю понадобится просто загрузить картинку со шрифтом в поле анализатора, а затем активировать процедуру распознавания. Главная «фишка» состоит в том, что после получения результата сканирования, а также обработки его разрешается редактировать.
Интерес способна вызвать и программа Font Matching Tool. Ее желательно использовать вместе с программой Compare It!. Последнее приложение дает возможность выполнять сравнение исходного документа, а также результата с распознанными шрифтами.
Онлайн-сервис по распознаванию шрифта
Помимо программ, которые требуют установки их на компьютер, существует возможность использовать услуги многочисленных интернет-ресурсов. Процесс распознавания шрифта на картинке в данном случае осуществляется аналогично предыдущим утилитам. Различие состоит в том, что изображение загружается непосредственно на сайт, а результат скачивается на компьютер. В число самых известных и востребованных сервисов стоит отнести следующие онлайн-системы:
Процесс распознавания шрифта на картинке в данном случае осуществляется аналогично предыдущим утилитам. Различие состоит в том, что изображение загружается непосредственно на сайт, а результат скачивается на компьютер. В число самых известных и востребованных сервисов стоит отнести следующие онлайн-системы:
• What The Font;
• Identifont;
• Bowfin Printworks;
• Type Navigator и прочие.
В заключении остается добавить только то, что лучше слишком не рассчитывать на программы и интернет-ресурсы. Как установлено на практике, ждать от них чего-то выдающегося не приходится. Ведь даже обычную капчу способны распознать не все интернет-боты. Тем более, проводить аналогию с программами, которые предназначены для распознавания шрифта, не стоит. Таким образом, при использовании подобных средств остается надеяться лишь на результаты определения самых простых шрифтов. Другое дело, что они способны распознаваться не из печатных документов, а из изображений. В этом и состоит основное преимущество всех программных продуктов такого типа.
Как устроен шрифт Брайля и зачем его распознавать
Когда я рассказываю о том, что очень нужно сделать автоматическое распознавание шрифта Брайля, первый вопрос: а зачем незрячим нужно это распознавание? Незрячие же отлично читают по точкам, а обычный плоский текст на экране — это как раз проблема. Ну а зрячие практически никогда не сталкиваются с текстом на Брайле.
На самом деле все сложнее. Во-первых, довольно много зрячих людей постоянно сталкиваются с Брайлем. Во-вторых, незрячим распознавание Брайля тоже может быть полезно.
Что такое шрифт Брайля
Рельефно-точечный шрифт изначально придумали вовсе не для слепых, а для армии. Предполагалось, что с помощью него солдаты смогут бесшумно общаться в полной темноте. В армии язык не пошел: зрячим людям оказалось не под силу читать пальцами рельефные точки. Но не пропадать же изобретению — рельефному шрифту решили научить слепых детей, один из этих детей доработал систему, и в итоге получился рельефно-точечный шрифт, используемый для письма и чтения незрячими и слабовидящими людьми.
Как устроен шрифт Брайля
Шрифт Брайля — рельефно-точечный, т.е. состоит из выпуклых точек и промежутков, причем точки четко организованы. Вот так выглядит приветствие «hello world»:
Один символ шрифта Брайля — решетка 3×2, в каждой из шести ячеек которой может быть (или не быть) рельефная точка. Получается 64 комбинации точек и пустот. Все позиции пусты — пробел, на всех позиция точки — зачеркивание. Зачеркнуть в Брайле — «забить» все 6 точек. Остается 62 различные «буквы», это не очень много. Приходится использовать одни и те же символы для передачи кириллицы, латиницы, других видов письменности и даже музыкальных нот. Если внутри текста происходит смена письменности, ставится специальный символ смены языка.
Вот здесь можно посмотреть, как выглядит, например, ваше имя на брайлевской кириллице. Так выглядит текст «Системный Блокъ»:
⠎⠊⠎⠞⠑⠍⠝⠮⠯ ⠃⠇⠕⠅⠷
Есть и конверторы латиницы в Брайль.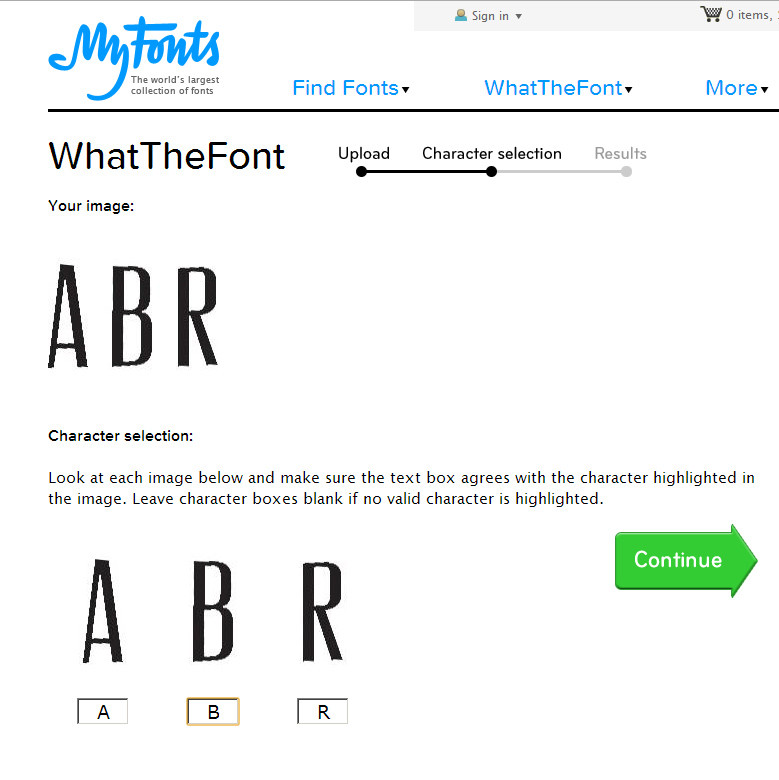 Например, brailletranslator.org умеет работать с разными видами латиницы. И еще умеет делать зеркальную картинку точек, зачем она нужна, расскажем чуть позже. А пока вот мое имя в зеркальном и обычном вариантах:
Например, brailletranslator.org умеет работать с разными видами латиницы. И еще умеет делать зеркальную картинку точек, зачем она нужна, расскажем чуть позже. А пока вот мое имя в зеркальном и обычном вариантах:
Как и в других письменностях, Брайль бывает печатным и «рукописным». На вид символы не отличаются — отличается способ письма. С печатным вариантом все более-менее понятно — это пластиковые округлые выпуклые точки, наверняка вы видели такие в лифтах или в подписях в музеях. В рукописном Брайле точки выдавливаются на бумаге с обратной стороны листа.
Что такое «рукописный» Брайль?
- «Дырочки на бумаге». В школах для слабовидящих детей учат писать «рукописным» Брайлем. Технически это протыкание дырочек специальным шилом (или просто ручкой) в листе бумаги, вставленном в специальный трафарет. В этом видео подробно показывается, как пишут. Самое удивительное, что на трафарете пишут зеркально: точки продавливают шилом с обратной стороны листа справа-налево.
 Вот для обучению письму на трафарете, как раз могут пригодится зеркальные картинки конвертеров.
Вот для обучению письму на трафарете, как раз могут пригодится зеркальные картинки конвертеров.
 Вот для обучению письму на трафарете, как раз могут пригодится зеркальные картинки конвертеров.
Вот для обучению письму на трафарете, как раз могут пригодится зеркальные картинки конвертеров.- Пишущие машинки. У брайлевской машинки всего 6 больших кнопок — каждая кнопка отвечает за одну из шести точек в брайлевской букве. Есть специальные компактные машинки, в которые вставляются листы бумаги и машинка выдавливает точки на бумаге. Например, здесь можно посмотреть, какие они бывают.
Двусторонняя печать
Брайлевские тексты иногда печатают с двух сторон, тогда на странице присутствуют одновременно и выпуклые точки текста, и впадины на местах точек текста с другой стороны листа. Как показывает личный опыт, это кошмар для компьютерного зрения и оптического распознавания символов.
Как показывает личный опыт, это кошмар для компьютерного зрения и оптического распознавания символов.
Зачем нужно автоматическое распознавание Брайля
— Кстати, а что значит распознавать Брайль?
— Взять фотографию или скан текста на Брайле и превратить в машиночитаемые брайлевские символы (а дальше можно сразу конвертировать его в обычный текст на кириллице, латинице и т.д).
А теперь главный вопрос: зачем нужно распознавать шрифт Брайля и переводить его в плоскопечатный текст (да именно так называют «обычные» буквы)? Ответ: больше всего распознавание Брайля и его автоматический перевод нужны людям, много взаимодействующим с незрячими, прежде всего родственникам и учителям.
Учителя в школах для слабовидящих, конечно, владеют Брайлем, но читать пальцами его обычно не умеют, читают глазами. Можете себе представить как тяжело проверять тетради диктантов из белых точек на белом фоне.
Родители и родственники незрячих людей часто вообще не могут выучить шрифт Брайля настолько, чтобы читать достаточно бегло, а не расшифровывая каждую букву. Получается, что родители не могут помочь своему ребенку с уроками или почитать вместе одну книгу, т.е. не могут делать самых обычных и привычных вещей.
Получается, что родители не могут помочь своему ребенку с уроками или почитать вместе одну книгу, т.е. не могут делать самых обычных и привычных вещей.
Еще одна проблема — переиздание брайлевских книг, для которых нет цифрового источника. Переиздание — не обязательно именно издание бумажной книги, принципиальна здесь именно оцифровка. Если есть цифровая версия, то дальше можно и печатать, и читать на брайлевском дисплее. Основная проблема с книгами, сделанными специально для незрячих в доцифровую эру. Например для учебников музыки, разработанных под брайлевскую нотную запись. Такие книги, изданные лет 40 назад, уже заметно обветшали, а замены им нет. Так что распознавание Брайля нужно и самим незрячим людям.
Но главная цель — помочь незрячим людям расширить круг общения. Например, не так давно незрячие дети начали участвовать в школьных олимпиадах. Сейчас работы ребят сначала вручную «переводятся» с Брайля в плоскопечатный шрифт, а только потом проверяются. В таком варианте невозможно сделать участие в олимпиадах достаточно массовым, доступным во всех регионах.
Если убрать «языковой барьер», преподавать незрячим людям смогут люди, не умеющие бегло читать на Брайле.
В конце концов, можно будет спокойно отправить открытку на Брайле в посткроссинге, и ее смогут прочесть все.
Почему Брайль до сих пор не распознают?
Как и на все сложные вопросы, тут нет однозначного ответа. Во-первых, это проект без коммерческого потенциала. Во-вторых, сейчас существует огромное количество технических средств, помогающих незрячим при чтение и письме. С ними люди отлично могут набирать текст на компьютере, пользоваться любыми мессенджерами. Так что для многих задач эта технология уже не актуальна. Рукописный Брайль есть только на этапе начального обучения письму.
Но так ситуация устроена далеко не везде. К сожалению, все эти технические средства довольно дорогие, выпускает их небольшое число компаний. Есть много стран (Россия в том числе), где брайлевская строка и брайлевский дисплей доступны совсем немногим.
Вероятно, через 10-20 лет «электронные помощники» распространятся по всему миру. Но людям нужно жить, учиться и общаться сейчас, а не через несколько десятилетий. Да и проблему оцифровки старых книг на Брайле электронные помощники не решают.
Но людям нужно жить, учиться и общаться сейчас, а не через несколько десятилетий. Да и проблему оцифровки старых книг на Брайле электронные помощники не решают.
Чтобы картина выглядела не такой безрадостной
Нельзя сказать, что на поле распознавания Брайля ничего не сделано. Есть довольно много статей о том, как компьютер учили распознавать шрифт Брайля, т.е. переводить Брайль с фотографий или сканов в цифровую форму. Но эти работы в большинстве своем остались на уровне теоретических разработок и не дошли до реализации.
Из готовых решений, доступных каждому, я нашла только аппаратно-программный комплекс — это такая дорогая большая железная машина с 3D сканером внутри, которая может распознавать только печатный Брайль. Безусловно полезная вещь, например, для брайлевских библиотек или для переиздания книг. Но слишком дорогая-большая-неудобная для более-менее любых других задач. Также есть проекты, которые заявляют о достижении высокого качества распознавания Брайля.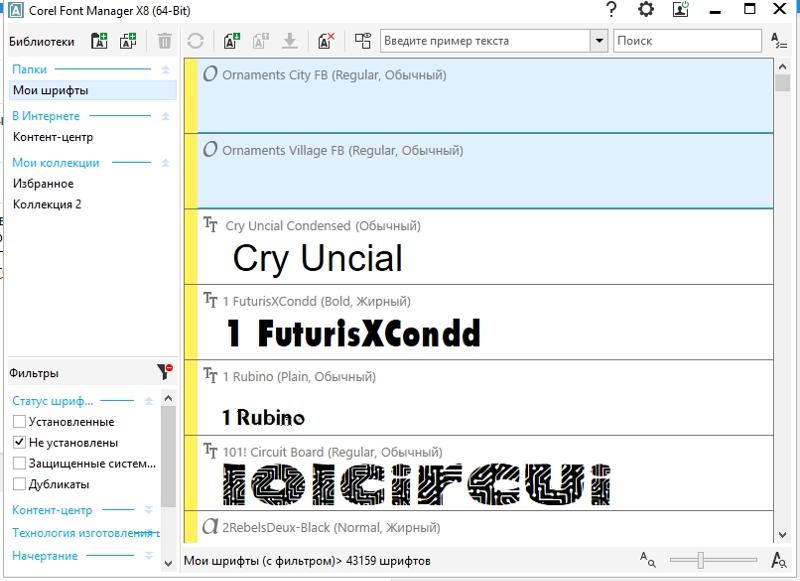 Но пока это не общедоступные продукты, а, скорее, proof of concept.
Но пока это не общедоступные продукты, а, скорее, proof of concept.
Надеюсь, эта ситуация скоро изменится, и я смогу скачать на телефон распознавалку Брайля.
Что еще IT сообщество делает с Брайлевской нотацией:
- Помощник обучению счету на Брайле, сделанный на ардуино.
- Башкирова И.Л., Гордейко В.В. Условные обозначения по системе Брайля при обучении математике и языку.
- Если вы хотите добавить написание на брайль на свой сайт, то вот тут есть библиотека. Смысла для незрячих в этом нет, на брайлевском дисплее эти знаки не прочитаются. Скорее для привлечения внимания к проблеме.
Распознавание текста | Документация Firebase
Эта страница описывает старую версию API распознавания текста, которая была частью
комплекта ML для Firebase. Функциональность этого API разделена на
два новых API (подробнее):
Функциональность этого API разделена на
два новых API (подробнее):
С помощью API распознавания текста ML Kit вы можете распознать текст в любом Язык на основе латыни (и многое другое с распознаванием текста в облаке).
Распознавание текста может автоматизировать утомительный ввод данных для кредитных карт, квитанций и визитные карточки. С помощью облачного API вы также можете извлекать текст из изображений документов, которые можно использовать для увеличения доступность или перевод документов.Приложения могут даже отслеживать реальный мир предметы, например, считывая числа в поездах.
iOS Android
Если вы разработчик Flutter, вас могут заинтересовать FlutterFire, который включает плагин для API-интерфейсов Firebase ML Vision.
Это бета-версия ML Kit для Firebase. Этот API может быть изменен обратно несовместимыми способами и не подлежит никаким SLA или политика прекращения поддержки.Выбор между встроенным или облачным API
| На устройстве | Облако | |
|---|---|---|
| Стоимость | Бесплатно | Бесплатно для первых 1000 использований этой функции в месяц: см. |
| Идеальные варианты использования | Обработка в реальном времени — идеально подходит для камеры или видеопотока Распознавание разреженного текста на изображениях | Распознавание текста с высокой точностью Распознавание разреженного текста на изображениях Распознавание плотно расположенного текста на изображениях документов Посмотреть Облако Демонстрация Vision API. |
| Языковая поддержка | Распознает латинские символы | Распознает и определяет широкий спектр языков и специальных персонажи |
 Цена
ЦенаПример результатов
Разреженный текст
Фото: Дитмар Рабич / Wikimedia Commons / «Дюссельдорф, Wege der parlamentarischen Demokratie — 2015 — 8123» / CC BY-SA 4.0| Распознанный текст | |
|---|---|
| Текст | Wege |
| Блоки | (1 блок) |
| Блок 0 | |
|---|---|
| Текст | Wege der parlamentarischen Demokratie |
| Рама | (117. 0, 258,0, 190,0, 83,0) 0, 258,0, 190,0, 83,0) |
| Угловые точки | (117, 270), (301,64, 258,49), (306,05, 329,36), (121,41, 340,86) |
| Распознанный код языка | de |
| Строки | (3 линии) |
| Строка 0 | |
|---|---|
| Текст | Wege der |
| Рама | (167,0, 261,0, 91,0, 28,0) |
| Угловые точки | (167, 267), (255.82, 261,46), (257,19, 283,42), (168,36, 288,95) |
| Распознанный код языка | de |
| Элементы | (2 элемента) |
| Элемент 0 | |
|---|---|
| Текст | Wege |
| Рама | (167,0, 263,0, 59,0, 26,0) |
| Угловые точки | (167, 267), (223,88, 263,45), (225,25, 285,41), (168,36, 288. 95) 95) |
Текст документа
| Распознанный текст | |
|---|---|
| Текст | DR. ДНЕВНИК СЕВАРДА 361 … (полный текст) |
| Блоки | (1 блок) |
| Блок 0 | |
|---|---|
| Текст | … (полный текст) |
| Уверенность | 0.98 |
| Рама | (25,0, 21,0, 359,0, 583,0) |
| Распознанный код языка | и |
| Пункты | (10 абзацев) |
 ДНЕВНИК СЕВАРДА 361 Профессор. Он, очевидно, ожидал такого звонка, потому что я застал его одетым в своей комнате.Его дверь была приоткрыта, так что он мог слышать, как открывается дверь в нашу комнату. Он пришел сразу; входя в комнату, он спросил Мину, могут ли прийти и другие.
ДНЕВНИК СЕВАРДА 361 Профессор. Он, очевидно, ожидал такого звонка, потому что я застал его одетым в своей комнате.Его дверь была приоткрыта, так что он мог слышать, как открывается дверь в нашу комнату. Он пришел сразу; входя в комнату, он спросил Мину, могут ли прийти и другие. | Пункт 1 | |
|---|---|
| Текст | «Нет, - сказала она довольно просто, - в этом нет необходимости. |
| Уверенность | 0.98 |
| Рама | (29,0, 110,0, 355,0, 44,0) |
| Распознанный код языка | и |
| слов | (34 слова) |
 Вы можете сказать им точно так же. Я должна пойти с вами в ваше путешествие».
Вы можете сказать им точно так же. Я должна пойти с вами в ваше путешествие». | Слово 7 | |
|---|---|
| Текст | просто |
| Уверенность | 0,99 |
| Рама | (179,0, 110,0, 37,0, 15,0) |
| Распознанный код языка | и |
| Обозначения | (6 символов) |
| Обозначение 0 | |
|---|---|
| Текст | с |
| Уверенность | 1.00 |
| Рама | (179,0, 110,0, 3,0, 15,0) |
| Распознанный код языка | и |
Дизайн сайтов
Advanced Internet Technologies, Inc. работает более 25 лет. Мы специализируемся на предоставлении высококачественных и доступных по цене индивидуальных веб-сайтов. Мы стремимся предоставить нашим клиентам, занимающимся веб-дизайном, единственный в своем роде веб-сайт.
работает более 25 лет. Мы специализируемся на предоставлении высококачественных и доступных по цене индивидуальных веб-сайтов. Мы стремимся предоставить нашим клиентам, занимающимся веб-дизайном, единственный в своем роде веб-сайт.
Веб-сайт с индивидуальным веб-дизайном представляет вашу организацию, бизнес, цель, местоположение и репутацию и может обеспечить вам отличную окупаемость ваших инвестиций.Веб-сайт — это ваша виртуальная витрина, стоимость которой составляет лишь часть обычных операций, и она может расширить ваш географический охват далеко за пределы вашего региона.
Покупка нестандартного веб-дизайна — важное решение, потому что это означает, что вам нужно будет работать с командой веб-дизайнеров, которая еще больше улучшит и повысит ценность вашего бренда. Мудрое решение принимает во внимание множество факторов, чтобы создать реальную добавленную стоимость для вашей организации. Мы определили ваши проблемные области и потребности, которые вдохновили нас на предложение веб-дизайна по доступной цене без ущерба для премиального качества. Всего за 99 долларов в месяц мы предоставляем все следующие функции и многое другое:
Всего за 99 долларов в месяц мы предоставляем все следующие функции и многое другое:
- Веб-дизайн и разработка на заказ
- Специализированный менеджер проекта
- Регистрация домена
- Дизайн логотипа
- Структурированные данные
- SSL-сертификат
- Ежемесячный веб-хостинг
- SEO на странице
- Скорость отклика мобильных устройств
- Кросс-браузерная совместимость
- Google Page Speed Testing
- Инструменты Google Analytics
- Круглосуточная поддержка в США
- Ежемесячное обслуживание веб-сайта
- Аналитика веб-сайта
- Панель управления cPanel
Вам не нужно искать дальше, если вы ищете лучший веб-дизайн.Взгляните на нашу обширную страницу портфолио и изучите наши прошлые проекты, чтобы лично убедиться в наших уникальных веб-дизайнах. Если вы найдете веб-сайт, который вам нравится, и если вам нужны рекомендации по выбору подходящего веб-сайта, не стесняйтесь обращаться к одному из наших опытных представителей по работе с клиентами для получения дополнительной информации по телефону (877) 404-4149. Вы также можете написать нам по адресу [электронная почта защищена] или назначить встречу, чтобы поговорить с нами сегодня. Вы также можете связаться с нами в чате или через наши страницы в социальных сетях.Мы организуем бесплатную консультацию и вместе с вами рассмотрим наш процесс веб-дизайна.
Вы также можете написать нам по адресу [электронная почта защищена] или назначить встречу, чтобы поговорить с нами сегодня. Вы также можете связаться с нами в чате или через наши страницы в социальных сетях.Мы организуем бесплатную консультацию и вместе с вами рассмотрим наш процесс веб-дизайна.
(PDF) Распознавание шрифтов в естественных изображениях с помощью Transfer Learning
12
5. Гиршик, Р., Донахью, Дж., Даррелл, Т., Малик, Дж .: Богатые иерархии функций для точного обнаружения
кураторских объектов и семантическая сегментация. В: Материалы конференции IEEE
по компьютерному зрению и распознаванию образов. С. 580–587 (2014)
6. Гупта А., Ведальди А., Зиссерман А.: Синтетические данные для локализации текста в изображениях нат-
урал. В: Материалы конференции IEEE по компьютерному зрению и распознаванию образов
. С. 2315–2324 (2016)
7. Ядерберг, М., Симонян, К., Ведальди, А., Зиссерман, А .: Чтение текста в дикой природе
с помощью сверточных нейронных сетей. International Journal of Computer Vision
International Journal of Computer Vision
116 (1), 1–20 (2016)
8. Кимура, Ф., Такашина, К., Цуруока, С., Мияке, Й .: Модифицированные квадратичные дискриминирующие функции. и приложение для распознавания китайских иероглифов.Действия IEEE Trans-
по анализу шаблонов и машинному интеллекту (1), 149–153 (1987)
9. Крижевский, А., Суцкевер, И., Хинтон, GE: Классификация Imagenet с глубокой концентрацией
эволюционных нейронных сетей. сети. В кн .: Достижения в области нейронных систем обработки информации.
стр. 1097–1105 (2012)
10. Лю Ф., Шен К., Линь Г.: Глубокие сверточные нейронные поля для оценки глубины
из одного изображения. В: Материалы конференции IEEE по компьютерному зрению
и распознаванию образов.С. 5162–5170 (2015)
11. Мусса, С.Б., Захур, А., Бенабдельхафид, А., Алими, А.М .: Новые функции, использующие многомерные параметры frac-
tal для обобщенного распознавания арабских шрифтов. Распознавание образов
Letters 31 (5), 361–371 (2010)
12. Перез, П., Гангнет, М., Блейк, А.: Редактирование изображений Пуассона. В: Транзакции ACM
Перез, П., Гангнет, М., Блейк, А.: Редактирование изображений Пуассона. В: Транзакции ACM
на графике (TOG). т. 22. С. 313–318. ACM (2003)
13. Рен, С., Хе, К., Гиршик, Р., Сан, Дж .: Быстрее r-cnn: На пути к обнаружению объектов в реальном времени
с сетями предложений региона.В кн .: Достижения в области нейронной обработки информации
систем. С. 91–99 (2015)
14. Симонян К., Зиссерман А .: Очень глубокие сверточные сети для крупномасштабного распознавания изображений
. Компьютерные науки (2014)
15. Слиман, Ф., Канун, С., Хеннеберт, Дж., Алими, А.М., Ингольд, Р .: Исследование семейства font-
и распознавания размера шрифта применительно к арабскому слову изображения в сверхнизком разрешении —
,тий. Письма о распознавании образов 34 (2), 209–218 (2013)
16.Сонг, В., Лиан, З., Тан, Ю., Сяо, Дж .: Распознавание шрифтов, не зависящих от содержимого, на
одного китайского символа с использованием разреженного представления. В: Анализ документов и признание
В: Анализ документов и признание
(ICDAR), 13-я Международная конференция, 2015 г. С. 376–380. IEEE
(2015)
17. Тао, Д., Цзинь, Л., Чжан, С., Ян, З., Ван, Й .: Редкая дискриминационная информация
сохранение для категоризации шрифтов китайских символов. Нейрокомпьютеры 129, 159–
167 (2014)
18.Тао, Д., Линь, X., Джин, Л., Ли, X .: Главный компонент двумерной долговременной памяти
для распознавания шрифтов на отдельных китайских иероглифах. Транзакции IEEE по кибернетике
46 (3), 756–765 (2016)
19. Тянь, З., Хуанг, В., Хе, Т., Хе, П., Цяо, Й .: Обнаружение текста в естественном image
с сетевым предложением текста соединения. В: Европейская конференция по компьютерам
Vision. С. 56–72. Springer (2016)
20. Ван, З., Ян, Дж., Джин, Х., Шехтман, Э., Agarwala, A., Brandt, J., Huang,
T.S .: Deepfont: Определите свой шрифт по изображению. В: Материалы 23-й международной конференции
ACM по мультимедиа. С. 451–459. ACM (2015)
С. 451–459. ACM (2015)
12 лучших инструментов для поиска шрифтов, привлекающих внимание зрителя
Привлекательные Шрифты помогают привлечь внимание читателей. Это привлекает читателей читать ваши статьи. Вы можете использовать красивых шрифтов не только в своем блоге, но и при отправке сообщений.
Шрифты являются ценным дополнением к вашим текстам. Это помогает читателям понять информацию в тексте. Хороший выбор шрифта, цвета и размера текста может иметь важное значение для успеха вашей маркетинговой кампании.
Лучшие инструменты для поиска шрифтовЕсли вам нравятся шрифты, используемые другими людьми, вы попытаетесь скопировать их и применить то же самое в своих статьях или текстах. Копировать одни и те же шрифты легко, если вы можете определить шрифты, которые они используют. Чтобы идентифицировать шрифты, вам понадобятся некоторые инструменты.
Преимущества использования нескольких шрифтов:
Это привлекает читателей Самый фундаментальный метод использования типографики — это выбор правильного шрифта.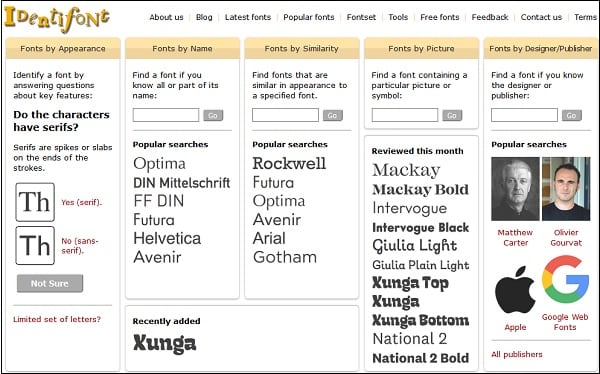 Шрифты должны выглядеть максимально четкими. Он не должен быть слишком маленьким или непрофессиональным. Убедитесь, что шрифты легко читаются, и это очень важно для профессиональной презентации.
Шрифты должны выглядеть максимально четкими. Он не должен быть слишком маленьким или непрофессиональным. Убедитесь, что шрифты легко читаются, и это очень важно для профессиональной презентации.
С помощью типографики просто и легко привлечь внимание людей, читающих ваш контент.Однако удержание внимания читателей требует большего воображения. Вы можете вызвать интерес в своем тексте, выделив его так, чтобы привлечь внимание.
Отражает профессионализмПравильное использование типографики в процессе дизайна демонстрирует впечатляющий профессионализм. Правильное использование шрифтов и размеров может повысить доверие читателей.
Основываясь на моем исследовании инструментов поиска шрифтов, я обнаружил три (3) категории инструментов.Это:
- Инструменты поиска шрифтов из изображений.
- Средство поиска шрифтов в Интернете или на основе букв.
- Определите шрифты визуально.

На основе изображений Шрифты идентифицируются путем распознавания определенных характеристик текста в изображении и последующего подключения его к шрифту в базе данных.
Веб-шрифты или буквенные шрифты идентифицируются с помощью расширений, которые обнаруживают выделенный текст на веб-странице с помощью кода сайта.
Идентификация шрифтов зрением — еще один полезный и простой в использовании инструмент для обнаружения шрифтов. Это простой вопрос, основанный на том, чтобы задать пользователям несколько простых вопросов, в результате чего будет составлен алфавитный список подходящих шрифтов.
Я перечислил лучших 12 лучших инструментов для поиска шрифтов, и Image и Web – на основе Font Finder . Если вы не знаете названия инструментов, эта статья очень поможет вам выбрать инструмент , и вы сможете узнать, какие шрифты они используют в своем тексте.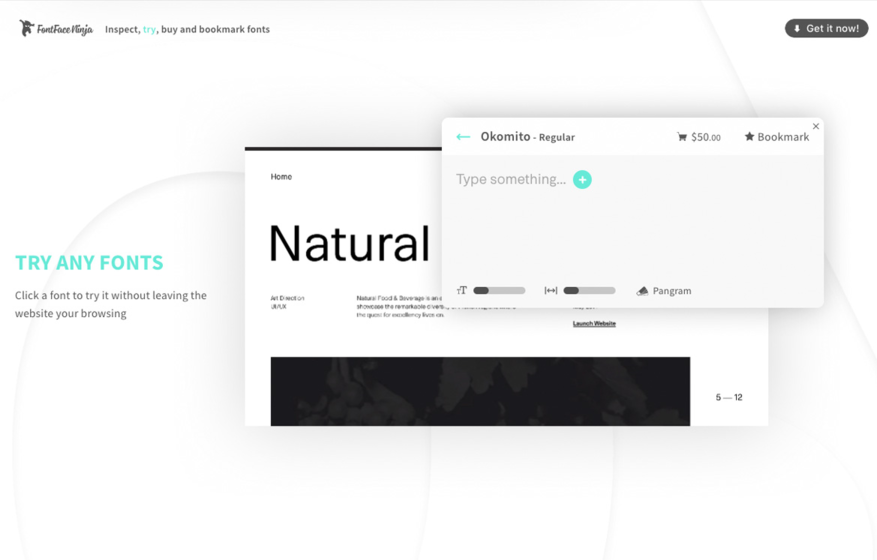 Обязательно прочитайте статью до конца.
Обязательно прочитайте статью до конца.
1. WhatFontIs
WhatFontIs — один из лучших и популярных инструментов поиска шрифтов . Это поможет вам легко определить шрифты, которые вы любите использовать в своих текстах. Это дает вам возможность, например, анализировать текст на темном или светлом фоне.
Лучшие инструменты для поиска шрифтовWhatFontIs — румынская веб-программа, основанная в 2009 году. Вы можете использовать ее для обнаружения шрифтов. Это базовый инструмент, но он очень полезен для дизайнеров всех уровней, особенно потому, что первые 100 шрифтов и предложений бесплатны.
Он имеет широкий спектр шрифтов, включая 200000 шрифтов, которые можно распознать с помощью одного снимка экрана. Вы можете получить к нему доступ, сделав снимок и загрузив его на свой веб-сайт, чтобы определить шрифт.
WhatFontIs — наиболее рекомендуемый инструмент для поиска шрифтов, поскольку он может определять шрифты, загружая URL-адрес конкретной страницы. Кроме того, можно фильтровать результаты, если вы хотите отличать бесплатные шрифты от коммерческих. Он также предлагает множество шрифтов, которые похожи друг на друга.
Кроме того, можно фильтровать результаты, если вы хотите отличать бесплатные шрифты от коммерческих. Он также предлагает множество шрифтов, которые похожи друг на друга.
- Размер файла снимка экрана не должен превышать 1,8 МБ.
- Текст должен состоять всего из одной строки .
- Формат или расширение файла должно быть в формате PNG, JPEG / JPG, и GIF.
- Для наилучшего результата ваш скриншот должен быть на как можно больше и содержать не менее пяти букв.
Посмотрите руководство «WhatFontIs» на YouTube .
Лучшие инструменты для поиска шрифтовОбщий рейтинг: 4,8 / 5,0
2.
 WhatTheFont
WhatTheFontWhatTheFont — еще один лучший инструмент для поиска шрифтов . Он может удовлетворить ваше желание идентифицировать шрифты и использовать их в ваших текстах. Для его использования не требуется глубоких технических знаний.
Лучшие инструменты для поиска шрифтовПроцесс прост, и вам нужно только загрузить изображение, которое может быть снимком экрана или изображением печатного носителя. WhatTheFont также имеет функцию идентификации шрифтов с помощью инструмента Sight , эффективного и простого в использовании инструмента для определения шрифтов.
Определить шрифты взглядом задает вам несколько вопросов, например: «Какой стиль является заглавным« Q »хвостом?» он прост и основан на том, что пользователям задают несколько основных вопросов для создания алфавитного списка подходящих шрифтов. На основе ваших ответов будет отображаться обзор всех обнаруженных шрифтов.
- Напечатанное на снимке экрана не должно превышать 25 символов.
- Формат или расширение файла должно быть в формате GIF, JPEG, TIFF или BMP
- WhatTheFont сканирует загруженное изображение и анализирует каждый символ.
Посмотрите руководство «WhatFontIs» на YouTube .
Лучшие инструменты для поиска шрифтовОбщий рейтинг: 4,5 / 5,0
3. Font Spring Matcherator Font Matcherator — это инструмент для поиска шрифтов на основе изображений со средним рейтингом. Он запущен и разработан Font Spring . Font Spring — одна из лучших и ведущих компаний в отрасли Font Curation.
Он запущен и разработан Font Spring . Font Spring — одна из лучших и ведущих компаний в отрасли Font Curation.
Font Matcherator позволяет быстро и легко определять шрифты. Вам необходимо загрузить изображение определенных шрифтов, которые вы хотите обнаружить, и оно предоставит вам точный результат.
Уровень совпадения не на должном уровне; но вы можете использовать его, чтобы узнать идентичность шрифта. У него образцовый дизайн пользовательского интерфейса, и вы получите хороший пользовательский опыт с этим инструментом поиска шрифтов.
Инструмент Font Matcherator Tool помогает выбрать текстовый блок вручную. Он обеспечивает лучший и точный результат, если вы решите работать с минимальным образцом и выделить меньше слов, может быть, одно или два слова. Тогда как если вы выделите более длинный текст или большой блок абзаца, вы можете не получить хороших результатов.
- Вы можете загрузить изображение или URL-адрес для завершения процесса идентификации шрифта.
- Формат или расширение файла должно быть в формате PNG, JPEG / JPG, и GIF.
- Чтобы добиться наилучшего результата, не загружайте более широких текстовых блоков .
Посмотрите руководство «Font Matcherator» на YouTube.
Лучшие инструменты для поиска шрифтовОбщий рейтинг: 4,4 / 5,0
4. Идентификатор
Идентификатор должен быть лучшим средством идентификации шрифтов из всех. Он предоставляет множество способов определить шрифт, даже если в центре экрана нет шрифта. У него тоже есть опция.
У него тоже есть опция.
Он предоставляет пять (5) вариантов для определения шрифта, который вы ищете.
Лучшие инструменты для поиска шрифтовВы можете найти свой шрифт, задав вопросы относительно основных атрибутов , шрифтов по имени, сходства с другими шрифтами, шрифтов через изображения, и поиска по именам создателей или издателей.
Есть и другие варианты в верхней части веб-сайта, такие как последних шрифтов Популярные шрифты наборов , бесплатные шрифты , и инструменты. Identifont также предоставляет несколько визуальных подсказок, которые вы можете выбрать, если сможете ответить.
Другой вариант, который следует рассмотреть для Identifont , заключается в том, что вы можете провести тщательное исследование и найти шрифты на основе сходства , дизайнера или изображения .
Функции или условия:
- Identifont предоставляет вам пять (5) различных способов идентификации шрифтов.
- Помогает идентифицировать шрифты, загружая изображений .
- Инструмент может идентифицировать шрифты, задав вам ряд вопросов, например «Есть ли у символов засечки?»
- Вы также можете найти новейших шрифтов, популярных шрифтов, наборов шрифтов, бесплатных шрифтов, и инструментов .
Учебное пособие YouTube недоступно.
Общий рейтинг: 4.0 / 5.0
5. Font Squirrel
Font Squirrel — это бесплатный инструмент поиска шрифтов, который можно использовать в печати и в Интернете.Это отличный ресурс для ваших текстов и контента. Это позволяет вам находить шрифты, просто загружая изображений и изображений .
Найти шрифты, которые вы ищете, легко, поскольку они разделены на категории в зависимости от стиля. Несмотря на то, что Font Squirrel существует уже некоторое время, они представили новый бета-инструмент, известный как Matcherator .
Font Squirrel является продуктом Font Spring и может быть доступен на веб-сайте.Если вы фотограф , графический дизайнер или писатель , этот Free Font Finder Tool поможет вам найти красивые шрифты.
Функции или условия:
- Вы можете использовать Font Squirrel в коммерческих целях.
- Позволяет кадрировать частей изображения .
- Вы также получаете опцию языковой фильтрации .
- Font Squirrel может использовать фотограф , графический дизайнер, или автор контента .

Посмотрите учебное пособие «Font Squirrel» на YouTube.
Лучшие инструменты для поиска шрифтовОбщий рейтинг: 4,8 / 5,0
Веб-инструмент для поиска шрифтов на основе букв:
6. WhatFont
WhatFont — это расширение для браузеров, позволяющее идентифицировать шрифты. Это стильное и простое надежное веб-приложение, которое позволяет находить шрифты при просмотре сайта.
Чтобы определить тип шрифта, единственное, что вам нужно сделать, это щелкнуть значок на панели закладок вашего браузера , чтобы загрузить WhatFont , а затем использовать его на любой веб-странице.
Лучшие инструменты для поиска шрифтов По сравнению с более ранними аналогичными приложениями, это намного более эффективно и доступно в вашем браузере.
WhatFont Tool удобен, если вы хотите сравнить характеристики различных шрифтов в одном месте. Какой шрифт позволяет нескольким информационным полям оставаться открытыми одновременно. Однако здесь нет области образца текста, чтобы написать свой текст.
Его можно использовать с Typekit вместе с Google Font API. Предлагается Wired WebMonkey , Lifehacker и SwissMiss .
Функции или условия:
- WhatFont — это простой и элегантный инструмент для поиска шрифтов.
- Вы можете определять шрифты при просмотре веб-сайтов.
- Это быстро и всегда доступно в вашем браузере.
Посмотрите руководство «WhatFont» на YouTube.
Лучшие инструменты для поиска шрифтовОбщий рейтинг: 4,1 / 5,0
7.
 Fonts Ninja
Fonts NinjaFonts Ninja — это расширение для браузеров, доступных для Chrome , Safari и Firefox что позволяет идентифицировать шрифтов.
Расширение Font Ninja прост в установке и использовании. После установки нажмите, чтобы открыть Font Ninja значок , чтобы просмотреть сайт и показать вам шрифты, используемые на сайте. Вы можете протестировать шрифт перед покупкой.
Лучшие инструменты поиска шрифтовЧтобы определить шрифт , стиль , интервал и цветов HTML , щелкните текст. Рекомендуется протестировать ваш текст, используя найденные вами шрифты.
Вы можете сохранить шрифт, получить доступ к более подробной информации и бесплатно протестировать его внутри расширения. После выбора шрифта нажмите «ABC » или « ABC » значок в главном окне, чтобы просмотреть несколько интересных примеров предложений.
Вы также можете переключаться между темными и светлыми цветами и выбирать из ряда значков расширений.
Функции или условия:
- Font Ninja позволяет пробовать шрифты, не покупая их предварительно.
- Вы можете найти шрифты и сразу же попробовать их.
- Он совместим с любым программным обеспечением для проектирования .
Посмотрите учебное пособие «Font Ninja» на YouTube.
Best Font Finder ToolsОбщий рейтинг: 4,4 / 5,0
8. Fontanello Fontanello можно описать как расширение для Chrome. Его можно оценить как хороший инструмент для поиска шрифтов. Когда вы щелкаете значок, все шрифты, используемые в данный момент на веб-сайте, отображаются в раскрывающемся меню.В меню также отображаются размеры шрифта, интервал и цвета HTML.
Его можно оценить как хороший инструмент для поиска шрифтов. Когда вы щелкаете значок, все шрифты, используемые в данный момент на веб-сайте, отображаются в раскрывающемся меню.В меню также отображаются размеры шрифта, интервал и цвета HTML.
Fontanello часто требовал повторной загрузки сайта перед оценкой страницы, чего не было при использовании Fonts Ninja . С точки зрения функциональности и эстетики Fonts Ninja имеет преимущество.
Функции или условия:- Fontanello позволяет отображать основные типографские стили.
- Это позволяет легко проверять типографику на веб-странице.
- Вы получите информацию о шрифте , весе, размере, цвете и некоторых других, менее используемых свойствах CSS .
- Здесь также отображается информация о контрасте выделенного текста.
Учебное пособие YouTube недоступно.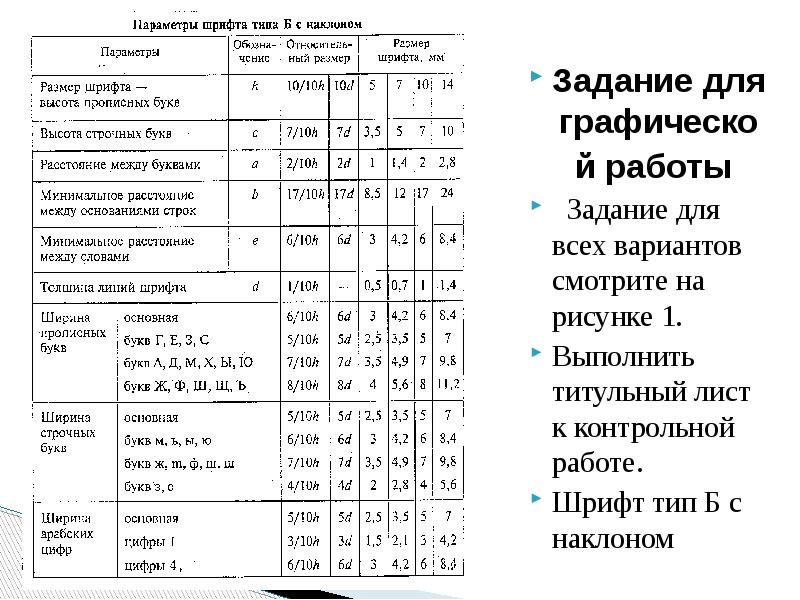
Общий рейтинг: 4,4 / 5,0
9. FountFount — менее популярное расширение идентификатора шрифта для нескольких браузеров. Он прост в использовании, и после его установки вы должны выбрать шрифт, который хотите найти.
Лучшие инструменты для поиска шрифтовРасширения, о которых я упоминал ранее, предназначались для Chrome , а также Firefox . Fount также совместим с Safari и IE8 +.
После того, как вы нажмете на выбранный шрифт, вы увидите параметр, который дает вам подробную информацию, например, какой это шрифт с точки зрения его размера , стиля, толщины и имени шрифта .
По данным Alexa, fount — это умеренно известный веб-сайт, который ежемесячно посещают около 15 тыс. человек, средний рейтинг посещаемости.Кроме того, Fount Artequalswork может похвастаться средним уровнем активности в социальных сетях.
- Fount работает в Safari, Chrome, Firefox и IE8 +.
- Fount сообщит вам, какой веб-шрифт в стеке шрифтов вы видите.
- У него хорошее взаимодействие в социальных сетях.
Учебное пособие YouTube недоступно.
Общий рейтинг: 4.0 / 5.0
10. Font Finder для Firefox
Font Finder для Firefox — это версия веб-расширения для XUL «FontFinder». Это расширение было создано, чтобы помочь разработчикам, , дизайнерам, и авторам контента. Он позволяет пользователям искать информацию о шрифтах в любом элементе веб-страницы, а затем копировать фрагменты в буфер обмена.
Лучшие инструменты для поиска шрифтов Он может тщательно проанализировать любой шрифт, который появляется на любой странице, и всю информацию о шрифте можно сохранить в буфер обмена. При желании вы также можете выбрать вариант удаления элементов семейства шрифтов со всей страницы, чтобы определить ухудшение качества и совместимость между ОС.
При желании вы также можете выбрать вариант удаления элементов семейства шрифтов со всей страницы, чтобы определить ухудшение качества и совместимость между ОС.
При захвате шрифта вы получите подробную информацию, включая тип шрифта, цвет шрифта , цвет фона, семейство шрифтов. Размер строки, толщину шрифта, преобразование текста, тип шрифта, класс и идентификатор.
Функции или условия:
- Вы можете полностью проанализировать любой шрифт на странице.
- Это расширение может копировать любую информацию элемента в буфер обмена.
- Отображает информацию о шрифте, такую как цвет шрифта, цвет фона, размер шрифта, линия и высота шрифта, выравнивание по вертикали, буква и высота, интервал между словами, вес шрифта, стиль, вариант и т. Д.
Учебник YouTube недоступен.
Общий рейтинг: 4,7 / 5,0
11. Руководство по идентификации шрифтов Serif
Руководство по идентификации шрифтов Serif похоже на инструмент WhatFont, поскольку он работает аналогично. Его можно установить в свой браузер в Интернете и получить к нему доступ в любое время. Он генерирует список шрифтов, совместимых с любыми шрифтами с засечками.
Его можно установить в свой браузер в Интернете и получить к нему доступ в любое время. Он генерирует список шрифтов, совместимых с любыми шрифтами с засечками.
Этот инструмент проверки шрифтов обнаруживает шрифты с засечками. Вы должны определить шрифты на вид и ответить на вопросы относительно дизайна, в которых речь идет о символах шрифта. В Руководстве представлены различные варианты анализа элементов, более похожих на выбранный вами шрифт.
Кроме того, вы также можете связаться с владельцем сайта Serif Font , который поможет с любыми вопросами о распознавании шрифтов в Интернете по электронной почте.
Функции или условия:
- Функциональность этого инструмента аналогична функциям «WhaFont tool» и «Identifont Tool».
- Он предоставляет различные параметры для идентификации шрифта.
- Вы можете задать свои запросы и вопросы в службу поддержки клиентов.
Учебное пособие YouTube недоступно.
Общий рейтинг: 4,1 / 5,0
12. Fonts.com
Fonts.com позволяет найти самый популярный ассортимент высококачественных шрифтов для ПК и веб-шрифтов.Его простота использования и удобный интерфейс помогут вам идентифицировать шрифты и обнаруживать их.
Лучшие инструменты для поиска шрифтовОн использует метод «Идентификация шрифта визуально» для обнаружения шрифтов. Он имеет функцию, которая позволяет выполнять поиск с использованием фильтров , классификации, лицензий и , свойств , чтобы определить, какой тип шрифта вам нужен.
После того, как вы заполнили фильтры, анализатор шрифтов предоставит вам различные шрифты на выбор. Такое распознавание символов через Интернет может быть медленным.Но преимущество этого метода в том, что он позволяет вам изучить возможности и найти уникальный шрифт, соответствующий вашим потребностям.
Функции или условия:
- Fonts. com может помочь вам открыть для себя новый дизайн шрифтов.
- Имеет 40 000 + стилей шрифта.
- Это инструмент поиска шрифтов на основе «Sight Identification» .
- Этот инструмент также идеально подходит для дизайнеров и авторов контента.
 com может помочь вам открыть для себя новый дизайн шрифтов.
com может помочь вам открыть для себя новый дизайн шрифтов.Учебное пособие YouTube недоступно.
Общий рейтинг: 4.3 / 5.0
Мы не можем найти эту страницу
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}} *
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}} {{добавить в коллекцию.description.length}} / 500 {{l10n_strings.TAGS}} {{$ item}} {{l10n_strings. PRODUCTS}}
{{l10n_strings.DRAG_TEXT}}
PRODUCTS}}
{{l10n_strings.DRAG_TEXT}}{{l10n_strings.DRAG_TEXT_HELP}}
{{l10n_strings.LANGUAGE}} {{$ select.selected.display}}{{article.content_lang.display}}
{{l10n_strings.АВТОР}} {{l10n_strings. AUTHOR_TOOLTIP_TEXT}}
AUTHOR_TOOLTIP_TEXT}}
Создайте систему распознавания рукописного текста с помощью TensorFlow | by Harald Scheidl
Минималистичная реализация нейронной сети, которую можно обучить на CPU Системы автономного распознавания рукописного текста (HTR) расшифровывают текст, содержащийся в отсканированных изображениях, в цифровой текст, пример показан на рис. 1. Мы будем построить нейронную сеть (NN), которая обучается на словах-изображениях из набора данных IAM.Поскольку входной слой (а, следовательно, и все другие слои) может быть небольшим для слов-изображений, NN-обучение возможно на CPU (конечно, GPU будет лучше). Эта реализация — минимум, необходимый для HTR с использованием TF.
Эта реализация — минимум, необходимый для HTR с использованием TF.
- Вам необходимы Python 3, TensorFlow 1.3, numpy и OpenCV.
- Получите реализацию с GitHub: либо возьмите версию кода, на которой основана эта статья, либо возьмите новейшую версию кода, если вы можете принять некоторые несоответствия между статьей и кодом
- Дальнейшие инструкции (как получить набор данных IAM, параметры командной строки,…) можно найти в README
Мы используем NN для нашей задачи.Он состоит из слоев сверточной NN (CNN), рекуррентных слоев NN (RNN) и последнего слоя временной классификации подключений (CTC). На рис. 2 показан обзор нашей системы HTR.
Рис. 2: Обзор операций NN (зеленый) и потока данных через NN (розовый). Мы также можем рассматривать NN более формально как функцию (см. Уравнение 1), которая отображает изображение (или матрицу) M размера W × H в последовательность символов (c1, c2,…) с длиной между 0 и L. Как видите, текст распознается на уровне символов, поэтому слова или тексты, не содержащиеся в обучающих данных, также могут быть распознаны (если отдельные символы правильно классифицированы).
Как видите, текст распознается на уровне символов, поэтому слова или тексты, не содержащиеся в обучающих данных, также могут быть распознаны (если отдельные символы правильно классифицированы).
Операции
CNN : входное изображение подается в слои CNN. Эти слои обучены извлекать из изображения соответствующие элементы. Каждый слой состоит из трех операций. Во-первых, операция свертки, которая применяет к входу ядро фильтра размером 5 × 5 в первых двух слоях и 3 × 3 в последних трех слоях. Затем применяется нелинейная функция RELU.Наконец, слой объединения суммирует области изображения и выводит уменьшенную версию входных данных. В то время как высота изображения уменьшается на 2 в каждом слое, добавляются карты характеристик (каналы), так что выходная карта характеристик (или последовательность) имеет размер 32 × 256.
RNN : последовательность функций содержит 256 функций на временной шаг, RNN распространяет соответствующую информацию через эту последовательность. Используется популярная реализация RNN с длительной краткосрочной памятью (LSTM), поскольку она способна распространять информацию на большие расстояния и обеспечивает более надежные обучающие характеристики, чем обычные RNN.Выходная последовательность RNN отображается в матрицу размером 32 × 80. Набор данных IAM состоит из 79 различных символов, кроме того, для операции CTC необходим один дополнительный символ (пустая метка CTC), поэтому имеется 80 записей для каждого из 32 временных шагов.
Используется популярная реализация RNN с длительной краткосрочной памятью (LSTM), поскольку она способна распространять информацию на большие расстояния и обеспечивает более надежные обучающие характеристики, чем обычные RNN.Выходная последовательность RNN отображается в матрицу размером 32 × 80. Набор данных IAM состоит из 79 различных символов, кроме того, для операции CTC необходим один дополнительный символ (пустая метка CTC), поэтому имеется 80 записей для каждого из 32 временных шагов.
CTC : во время обучения NN, CTC получает выходную матрицу RNN и основной текст истинности, и он вычисляет значение потерь . При выводе CTC предоставляется только матрица, и он декодирует ее в окончательный текст .И основной текст, и распознанный текст могут иметь длину не более 32 символов.
Данные
Вход : это изображение в оттенках серого размером 128 × 32. Обычно изображения из набора данных не имеют точно такого размера, поэтому мы изменяем его размер (без искажения) до тех пор, пока он не станет шириной 128 или высотой 32.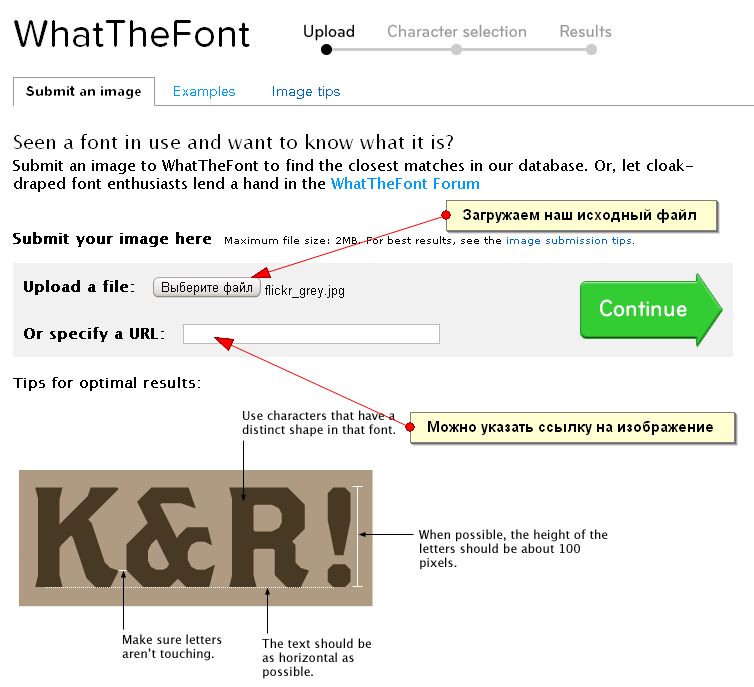 Затем мы копируем изображение в (белое) целевое изображение размер 128х32. Этот процесс показан на рис. 3. Наконец, мы нормализуем оттенки серого изображения, что упрощает задачу для NN.Увеличение данных можно легко интегрировать, скопировав изображение в случайные позиции вместо выравнивания по левому краю или произвольно изменив размер изображения.
Затем мы копируем изображение в (белое) целевое изображение размер 128х32. Этот процесс показан на рис. 3. Наконец, мы нормализуем оттенки серого изображения, что упрощает задачу для NN.Увеличение данных можно легко интегрировать, скопировав изображение в случайные позиции вместо выравнивания по левому краю или произвольно изменив размер изображения.
Выходные данные CNN : Рис. 4 показывает выходные данные уровней CNN, которые представляют собой последовательность длиной 32. Каждая запись содержит 256 функций. Конечно, эти функции дополнительно обрабатываются слоями RNN, однако некоторые функции уже демонстрируют высокую корреляцию с некоторыми высокоуровневыми свойствами входного изображения: есть функции, которые имеют высокую корреляцию с символами (например,г. «E»), или с повторяющимися символами (например, «tt»), или со свойствами символов, такими как циклы (как содержится в написанных от руки «l» или «e»).
RNN output : На рис. 5 показана визуализация выходной матрицы RNN для изображения, содержащего текст «маленький». Матрица, показанная на самом верхнем графике, содержит оценки для символов, включая пустую метку CTC в качестве последней (80-й) записи.Другие элементы матрицы, сверху вниз, соответствуют следующим символам: «!» # & ’() * +, -. / 0123456789:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz». Можно видеть, что в большинстве случаев символы предсказываются точно в том положении, в котором они появляются на изображении (например, сравните положение «i» на изображении и на графике). Не выравнивается только последний символ «е». Но это нормально, поскольку операция CTC не требует сегментации и не заботится об абсолютных позициях.Из самого нижнего графика, показывающего оценки для символов «l», «i», «t», «e» и пустой метки CTC, текст можно легко декодировать: мы просто берем наиболее вероятный символ из каждого раза -step, это формирует так называемый лучший путь, затем мы отбрасываем повторяющиеся символы и, наконец, все пробелы: «l — ii — tt — l-… -e» → «l — i — tt- -l-… -e »→« маленький ».
Рис. 5: Вверху: выходная матрица слоев RNN. В центре: входное изображение. Внизу: вероятности символов «l», «i», «t», «e» и пустой метки CTC.Реализация состоит из 4 модулей:
- SamplePreprocessor.py: подготавливает изображения из набора данных IAM для NN
- DataLoader.py: считывает образцы, помещает их в пакеты и предоставляет интерфейс-итератор для просмотра данных
- Model.py: создает модель, как описано выше, загружает и сохраняет модели, управляет сессиями TF и предоставляет интерфейс для обучения и вывода
- main.py: объединяет все ранее упомянутые модули
Мы только смотрим на модель.py, поскольку другие исходные файлы связаны с базовым вводом-выводом файла (DataLoader.py) и обработкой изображений (SamplePreprocessor.py).
CNN
Для каждого уровня CNN создайте ядро размером k × k, которое будет использоваться в операции свертки.
Затем передайте результат свертки в операцию RELU, а затем снова на уровень объединения с размером px × py и размером шага sx × sy.
Эти шаги повторяются для всех слоев цикла for.
RNN
Создайте и сложите два слоя RNN по 256 единиц в каждом.
Затем создайте из него двунаправленную RNN, чтобы входная последовательность проходила спереди назад и наоборот. В результате мы получаем две выходные последовательности fw и bw размером 32 × 256, которые мы позже объединяем вдоль оси признаков, чтобы сформировать последовательность размером 32 × 512. Наконец, он отображается на выходную последовательность (или матрицу) размером 32 × 80, которая подается на уровень CTC.
CTC
Для расчета потерь мы передаем операции как основной текст, так и матрицу.Основной текст истинности кодируется как разреженный тензор. Длина входных последовательностей должна быть передана обеим операциям CTC.
Теперь у нас есть все входные данные для создания операции потери и операции декодирования.
Обучение
Среднее значение потерь элементов пакета используется для обучения NN: оно подается в оптимизатор, такой как RMSProp.
Улучшение модели
В случае, если вы хотите загружать полные текстовые строки, как показано на рис. 6, вместо изображений слов, вы должны увеличить размер ввода NN.
Рис. 6: Полная текстовая строка может быть введена в NN, если ее входной размер увеличен (изображение взято из IAM).Если вы хотите повысить точность распознавания, вы можете следовать одному из следующих советов:
- Увеличение данных: увеличьте размер набора данных путем применения дополнительных (случайных) преобразований к входным изображениям
- Удалите курсивный стиль письма во входных изображениях ( см. DeslantImg)
- Увеличить размер ввода (если ввод NN достаточно велик, можно использовать полные текстовые строки)
- Добавить больше слоев CNN
- Заменить LSTM на 2D-LSTM
- Декодер: использовать прохождение токена или поиск словарного луча декодирование (см. CTCWordBeamSearch) для ограничения вывода словарными словами
- Коррекция текста: если распознанное слово не содержится в словаре, найдите наиболее похожее
Мы обсудили NN, который может распознавать текст в изображениях.Сеть NN состоит из 5 слоев CNN и 2 слоев RNN и выводит матрицу вероятностей символов. Эта матрица используется либо для расчета потерь CTC, либо для декодирования CTC. Предоставляется реализация с использованием TF и представлены некоторые важные части кода. Наконец, были даны советы по повышению точности распознавания.
Возникло несколько вопросов по представленной модели:
- Как распознать текст в ваших образцах / наборе данных?
- Как распознать текст в строках / предложениях?
- Как рассчитать показатель достоверности распознанного текста?
Я обсуждаю их в статье FAQ.
Исходный код и данные можно скачать по адресу:
В этих статьях более подробно обсуждаются некоторые аспекты распознавания текста:
Более подробную презентацию можно найти в этих публикациях:
И, наконец, обзор других моих Средние статьи.
Лучшие настройки сканирования для ускорения распознавания текста
Существует множество бумажных документов, которые необходимо сканировать, например, входящие счета-фактуры A / P. Вот несколько быстрых настроек, которые вы можете внести, чтобы DocuWare могла считывать данные наилучшим образом — и вам никогда не придется выполнять повторное сканирование.
Будь то счета-фактуры, накладные или подписанные контракты: многие бумажные документы необходимо сканировать перед их цифровым переносом в DocuWare. Обычно это делается централизованно или с помощью ведомственного сканера. Поэтому неудивительно, что чем лучше качество сканирования, тем лучше данные, которые могут быть получены из итоговых цифровых документов.
Насколько быстро и точно создается сканирование, во многом зависит от качества сканирования и читабельности документа. Вы можете значительно улучшить это, изменив всего несколько настроек.Читайте дальше…
Какой формат файла?
Когда дело доходит до выбора формата файла, важно знать, что в конечном итоге произойдет со сканированным / оцифрованным документом. Существуют такие документы, как входящие счета-фактуры или квитанции о доставке, которые DocuWare считывает данные после сканирования для дальнейшей обработки или включения в рабочий процесс. Есть и другие документы, например чертежи, которые просто хранятся в DocuWare, чтобы к ним можно было получить доступ через клиент DocuWare по мере необходимости или отправить в виде вложения электронной почты.
Если вы хотите обрабатывать данные из документа — например, чтобы читать текст и штрих-коды и использовать эту информацию для индексации или в рабочих процессах, — документ должен быть записан в формате PDF или PDF / A. Поэтому обязательно выберите этот параметр при сканировании.
Если документ требуется только для просмотра или пересылки по электронной почте, доступны все распространенные форматы файлов. Помимо PDF и PDF / A, в этот список входят PNG, JPEG или TIF. Если его нужно только заархивировать, не имеет значения, какой формат вы выберете при сканировании.Однако, чтобы такие документы также хорошо отображались на экране, вы можете предпринять несколько дополнительных шагов для обеспечения оптимального качества сканирования. Подробнее…
Цветовой режим по необходимости
Для некоторых типов документов настройка «Цвет» может быть полезна — например, когда контракты подписываются с использованием пера разных цветов, чтобы отразить разные права / подписантов, или когда детали чертежа должны отображаться в цвете. Однако в большинстве случаев вполне достаточно черно-белого или серого режима.Эти сканирования также требуют наименьшего объема памяти, что является большим преимуществом, когда вы говорите об объемах.
Поиск правильного разрешения
Разрешение документа важно для оптимального индексирования. Это число отражает плотность точек в файле и измеряется в dpi, «точках на дюйм». Для получения оптимальных результатов рекомендуется разрешение не менее 300 dpi. Если разрешение слишком низкое, могут возникнуть ошибки оптического распознавания символов (OCR). Например, «i» или «!» фиксируется как «I» или «v» читается дважды вместо «w».«
При различении по цветному режиму мы рекомендуем 300 или 400 dpi для черно-белых s банок. Для полутонового и цветного сканирования часто бывает достаточно от 150 до 300 dpi.
Еще одним фактором является размер шрифта документа. Вот хорошее практическое правило: чем меньше шрифт, тем выше должно быть разрешение.
В черно-белом режиме буквы «I l t i» четко отображаются только при разрешении 300 dpi и выше. В полутоновом режиме символы уже четко распознаются при разрешении 75 точек на дюйм, но включена информация об изображении, такая как структура бумаги, которая, вероятно, увеличит файл и займет ненужное место для хранения.
Лучшие условия для быстрого и точного захвата
Найдите оптимальные настройки, и вы получите наилучший результат в кратчайшие сроки при импорте отсканированных документов в DocuWare. Если система не может решить во время процесса импорта, например, 1 или L, это замедлит ваши процессы и снизится производительность. Поэтому стоит убедиться, что у вас есть правильные настройки для сканирования, и убедиться, что ваша система имеет наилучшее качество данных для управления вашими документами.
Подробнее об автоматическом импорте отсканированных документов в DocuWare. Если вы в основном сканируете штрих-коды, прочитайте, как распознавать штрих-коды еще точнее.